 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFEnc$^2$: Unifying Data Packing for Efficient Private Inference via Convolution and Architecture-Aware Fragment Encoding
Jun 15, 2026Fully Homomorphic Encryption (FHE) enables privacy-preserving machine learning but incurs extreme computational and memory overhead. These costs come not only from expensive low-level primitives, including Number Theoretic Transform (NTT), rotation, and key-switching, but also from inefficient ciphertext packing at the application level. Existing packing strategies typically preserve either neighboring data elements or feature grouping, but not both, leading to wasted ciphertext slots, excessive rotations, and inflated ciphertext counts. We propose FEnc2, a unified and principled fragment-based encoding framework for CKKS-based private convolutional neural network inference. FEnc2 optimizes slot utilization, rotation complexity, and ciphertext density through two components: 1)Conv-aware Encoding, which analytically selects an optimal fragment size to decouple spatial dependencies and jointly minimize inner-outer rotations across layers, and 2)Arch-aware Ct Compression, which restores ciphertext density after feature- or channel-reduction layers. Together, these transformations reshape encrypted workload structure and reduce homomorphic operations by one to two orders of magnitude. With full memory capacity utilized, i.e., at maximum batch size, FEnc2 achieves end-to-end latency speedups over the state-of-the-art Orion of up to 228.83x on GPU and 226.06x on CPU for LeNet on MNIST, and up to 4.55x on GPU and 9.43x on CPU for MobileNet on ImageNet. FEnc2 is hardware-agnostic yet architecturally transformative: by optimizing encrypted tensor layout before execution, it reduces ciphertext count and workload pressure on hardware, complementing primitive-level optimizations such as NTT and keyswitch accelerators. These results show that application-level data layout is a first-order architectural design dimension for encrypted inference and an important enabler for next-generation FHE systems.
AEGIS: Scaling Long-Sequence Homomorphic Encrypted Transformer Inference via Hybrid Parallelism on Multi-GPU Systems
Apr 03, 2026Fully Homomorphic Encryption (FHE) enables privacy-preserving Transformer inference, but long-sequence encrypted Transformers quickly exceed single-GPU memory capacity because encoded weights are already large and encrypted activations grow rapidly with sequence length. Multi-GPU execution therefore becomes unavoidable, yet scaling remains challenging because communication is jointly induced by application-level aggregation and encryption-level RNS coupling. Existing approaches either synchronize between devices frequently or replicate encrypted tensors across devices, leading to excessive communication and latency. We present AEGIS, an Application-Encryption Guided Inference System for scalable long-sequence encrypted Transformer inference on multi-GPU platforms. AEGIS derives device placement from ciphertext dependencies jointly induced by Transformer dataflow and CKKS polynomial coupling, co-locating modulus-coherent and token-coherent data so that communication is introduced only when application dependencies require it, while reordering polynomial operators to overlap the remaining collectives with computation. On 2048-token inputs, AEGIS reduces inter-GPU communication by up to 57.9% in feed-forward networks and 81.3% in self-attention versus prior state-of-the-art designs. On four GPUs, it achieves up to 96.62% scaling efficiency, 3.86x end-to-end speedup, and 69.1% per-device memory reduction. These results establish coordinated application-encryption parallelism as a practical foundation for scalable homomorphic Transformer inference.
KinD-LCE Curve Estimation And Retinex Fusion On Low-Light Image
Jul 19, 2022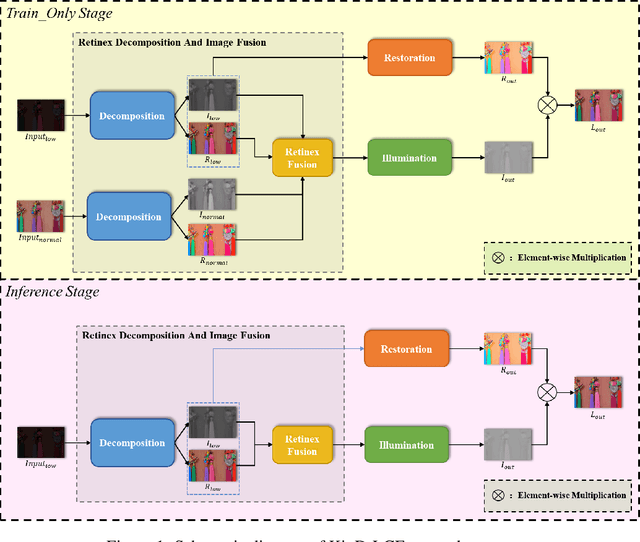

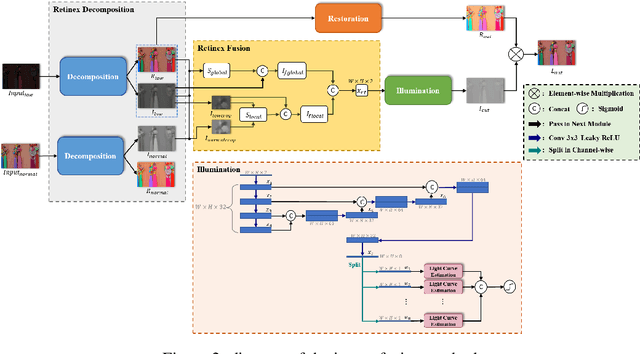

The problems of low light image noise and chromatic aberration is a challenging problem for tasks such as object detection, semantic segmentation, instance segmentation, etc. In this paper, we propose the algorithm for low illumination enhancement. KinD-LCE uses the light curve estimation module in the network structure to enhance the illumination map in the Retinex decomposed image, which improves the image brightness; we proposed the illumination map and reflection map fusion module to restore the restored image details and reduce the detail loss. Finally, we included a total variation loss function to eliminate noise. Our method uses the GladNet dataset as the training set, and the LOL dataset as the test set and is validated using ExDark as the dataset for downstream tasks. Extensive Experiments on the benchmarks demonstrate the advantages of our method and are close to the state-of-the-art results, which achieve a PSNR of 19.7216 and SSIM of 0.8213 in terms of metrics.
Using Frequency Attention to Make Adversarial Patch Powerful Against Person Detector
May 11, 2022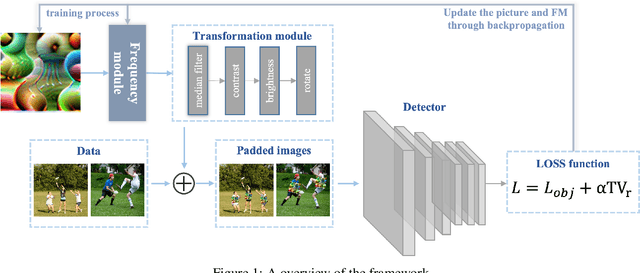

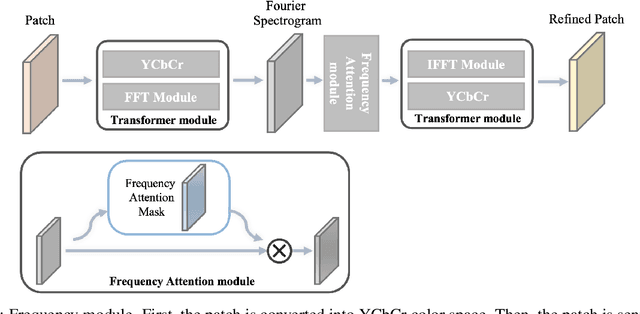
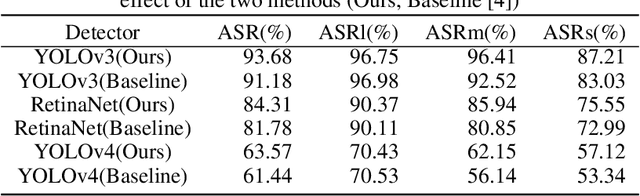
Deep neural networks (DNNs) are vulnerable to adversarial attacks. In particular, object detectors may be attacked by applying a particular adversarial patch to the image. However, because the patch shrinks during preprocessing, most existing approaches that employ adversarial patches to attack object detectors would diminish the attack success rate on small and medium targets. This paper proposes a Frequency Module(FRAN), a frequency-domain attention module for guiding patch generation. This is the first study to introduce frequency domain attention to optimize the attack capabilities of adversarial patches. Our method increases the attack success rates of small and medium targets by 4.18% and 3.89%, respectively, over the state-of-the-art attack method for fooling the human detector while assaulting YOLOv3 without reducing the attack success rate of big targets.
STDC-MA Network for Semantic Segmentation
May 11, 2022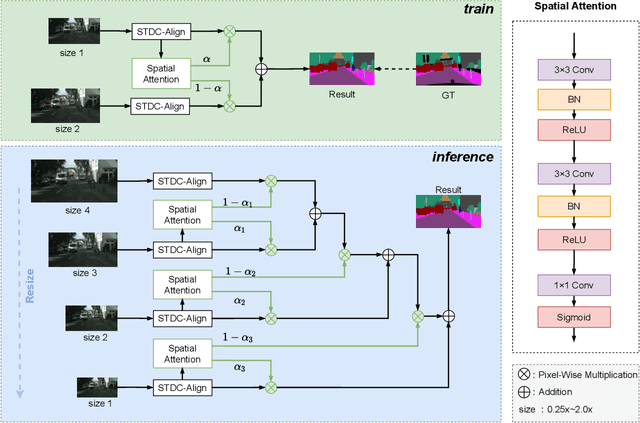

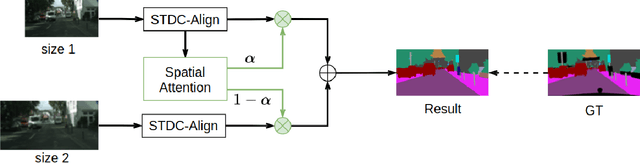
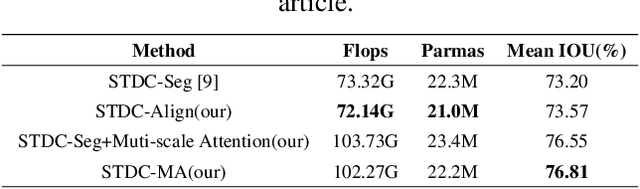
Semantic segmentation is applied extensively in autonomous driving and intelligent transportation with methods that highly demand spatial and semantic information. Here, an STDC-MA network is proposed to meet these demands. First, the STDC-Seg structure is employed in STDC-MA to ensure a lightweight and efficient structure. Subsequently, the feature alignment module (FAM) is applied to understand the offset between high-level and low-level features, solving the problem of pixel offset related to upsampling on the high-level feature map. Our approach implements the effective fusion between high-level features and low-level features. A hierarchical multiscale attention mechanism is adopted to reveal the relationship among attention regions from two different input sizes of one image. Through this relationship, regions receiving much attention are integrated into the segmentation results, thereby reducing the unfocused regions of the input image and improving the effective utilization of multiscale features. STDC- MA maintains the segmentation speed as an STDC-Seg network while improving the segmentation accuracy of small objects. STDC-MA was verified on the verification set of Cityscapes. The segmentation result of STDC-MA attained 76.81% mIOU with the input of 0.5x scale, 3.61% higher than STDC-Seg.