 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForceVLA: Enhancing VLA Models with a Force-aware MoE for Contact-rich Manipulation
May 28, 2025Vision-Language-Action (VLA) models have advanced general-purpose robotic manipulation by leveraging pretrained visual and linguistic representations. However, they struggle with contact-rich tasks that require fine-grained control involving force, especially under visual occlusion or dynamic uncertainty. To address these limitations, we propose \textbf{ForceVLA}, a novel end-to-end manipulation framework that treats external force sensing as a first-class modality within VLA systems. ForceVLA introduces \textbf{FVLMoE}, a force-aware Mixture-of-Experts fusion module that dynamically integrates pretrained visual-language embeddings with real-time 6-axis force feedback during action decoding. This enables context-aware routing across modality-specific experts, enhancing the robot's ability to adapt to subtle contact dynamics. We also introduce \textbf{ForceVLA-Data}, a new dataset comprising synchronized vision, proprioception, and force-torque signals across five contact-rich manipulation tasks. ForceVLA improves average task success by 23.2\% over strong $\pi_0$-based baselines, achieving up to 80\% success in tasks such as plug insertion. Our approach highlights the importance of multimodal integration for dexterous manipulation and sets a new benchmark for physically intelligent robotic control. Code and data will be released at https://sites.google.com/view/forcevla2025.
SIME: Enhancing Policy Self-Improvement with Modal-level Exploration
May 02, 2025Self-improvement requires robotic systems to initially learn from human-provided data and then gradually enhance their capabilities through interaction with the environment. This is similar to how humans improve their skills through continuous practice. However, achieving effective self-improvement is challenging, primarily because robots tend to repeat their existing abilities during interactions, often failing to generate new, valuable data for learning. In this paper, we identify the key to successful self-improvement: modal-level exploration and data selection. By incorporating a modal-level exploration mechanism during policy execution, the robot can produce more diverse and multi-modal interactions. At the same time, we select the most valuable trials and high-quality segments from these interactions for learning. We successfully demonstrate effective robot self-improvement on both simulation benchmarks and real-world experiments. The capability for self-improvement will enable us to develop more robust and high-success-rate robotic control strategies at a lower cost. Our code and experiment scripts are available at https://ericjin2002.github.io/SIME/
Novel Demonstration Generation with Gaussian Splatting Enables Robust One-Shot Manipulation
Apr 17, 2025Visuomotor policies learned from teleoperated demonstrations face challenges such as lengthy data collection, high costs, and limited data diversity. Existing approaches address these issues by augmenting image observations in RGB space or employing Real-to-Sim-to-Real pipelines based on physical simulators. However, the former is constrained to 2D data augmentation, while the latter suffers from imprecise physical simulation caused by inaccurate geometric reconstruction. This paper introduces RoboSplat, a novel method that generates diverse, visually realistic demonstrations by directly manipulating 3D Gaussians. Specifically, we reconstruct the scene through 3D Gaussian Splatting (3DGS), directly edit the reconstructed scene, and augment data across six types of generalization with five techniques: 3D Gaussian replacement for varying object types, scene appearance, and robot embodiments; equivariant transformations for different object poses; visual attribute editing for various lighting conditions; novel view synthesis for new camera perspectives; and 3D content generation for diverse object types. Comprehensive real-world experiments demonstrate that RoboSplat significantly enhances the generalization of visuomotor policies under diverse disturbances. Notably, while policies trained on hundreds of real-world demonstrations with additional 2D data augmentation achieve an average success rate of 57.2%, RoboSplat attains 87.8% in one-shot settings across six types of generalization in the real world.
Digital Gene: Learning about the Physical World through Analytic Concepts
Apr 09, 2025Reviewing the progress in artificial intelligence over the past decade, various significant advances (e.g. object detection, image generation, large language models) have enabled AI systems to produce more semantically meaningful outputs and achieve widespread adoption in internet scenarios. Nevertheless, AI systems still struggle when it comes to understanding and interacting with the physical world. This reveals an important issue: relying solely on semantic-level concepts learned from internet data (e.g. texts, images) to understand the physical world is far from sufficient -- machine intelligence currently lacks an effective way to learn about the physical world. This research introduces the idea of analytic concept -- representing the concepts related to the physical world through programs of mathematical procedures, providing machine intelligence a portal to perceive, reason about, and interact with the physical world. Except for detailing the design philosophy and providing guidelines for the application of analytic concepts, this research also introduce about the infrastructure that has been built around analytic concepts. I aim for my research to contribute to addressing these questions: What is a proper abstraction of general concepts in the physical world for machine intelligence? How to systematically integrate structured priors with neural networks to constrain AI systems to comply with physical laws?
DexTOG: Learning Task-Oriented Dexterous Grasp with Language
Apr 06, 2025This study introduces a novel language-guided diffusion-based learning framework, DexTOG, aimed at advancing the field of task-oriented grasping (TOG) with dexterous hands. Unlike existing methods that mainly focus on 2-finger grippers, this research addresses the complexities of dexterous manipulation, where the system must identify non-unique optimal grasp poses under specific task constraints, cater to multiple valid grasps, and search in a high degree-of-freedom configuration space in grasp planning. The proposed DexTOG includes a diffusion-based grasp pose generation model, DexDiffu, and a data engine to support the DexDiffu. By leveraging DexTOG, we also proposed a new dataset, DexTOG-80K, which was developed using a shadow robot hand to perform various tasks on 80 objects from 5 categories, showcasing the dexterity and multi-tasking capabilities of the robotic hand. This research not only presents a significant leap in dexterous TOG but also provides a comprehensive dataset and simulation validation, setting a new benchmark in robotic manipulation research.
OmniCam: Unified Multimodal Video Generation via Camera Control
Apr 03, 2025

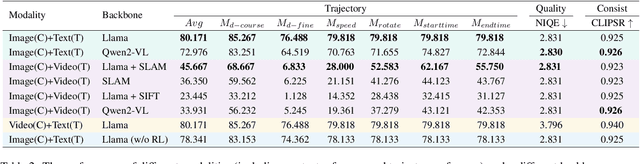
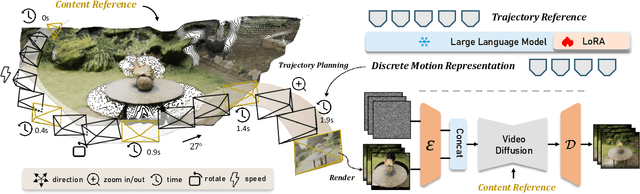
Camera control, which achieves diverse visual effects by changing camera position and pose, has attracted widespread attention. However, existing methods face challenges such as complex interaction and limited control capabilities. To address these issues, we present OmniCam, a unified multimodal camera control framework. Leveraging large language models and video diffusion models, OmniCam generates spatio-temporally consistent videos. It supports various combinations of input modalities: the user can provide text or video with expected trajectory as camera path guidance, and image or video as content reference, enabling precise control over camera motion. To facilitate the training of OmniCam, we introduce the OmniTr dataset, which contains a large collection of high-quality long-sequence trajectories, videos, and corresponding descriptions. Experimental results demonstrate that our model achieves state-of-the-art performance in high-quality camera-controlled video generation across various metrics.
Physically Ground Commonsense Knowledge for Articulated Object Manipulation with Analytic Concepts
Mar 30, 2025We human rely on a wide range of commonsense knowledge to interact with an extensive number and categories of objects in the physical world. Likewise, such commonsense knowledge is also crucial for robots to successfully develop generalized object manipulation skills. While recent advancements in Large Language Models (LLM) have showcased their impressive capabilities in acquiring commonsense knowledge and conducting commonsense reasoning, effectively grounding this semantic-level knowledge produced by LLMs to the physical world to thoroughly guide robots in generalized articulated object manipulation remains a challenge that has not been sufficiently addressed. To this end, we introduce analytic concepts, procedurally defined upon mathematical symbolism that can be directly computed and simulated by machines. By leveraging the analytic concepts as a bridge between the semantic-level knowledge inferred by LLMs and the physical world where real robots operate, we are able to figure out the knowledge of object structure and functionality with physics-informed representations, and then use the physically grounded knowledge to instruct robot control policies for generalized, interpretable and accurate articulated object manipulation. Extensive experiments in both simulation and real-world environments demonstrate the superiority of our approach.
Dense Policy: Bidirectional Autoregressive Learning of Actions
Mar 17, 2025Mainstream visuomotor policies predominantly rely on generative models for holistic action prediction, while current autoregressive policies, predicting the next token or chunk, have shown suboptimal results. This motivates a search for more effective learning methods to unleash the potential of autoregressive policies for robotic manipulation. This paper introduces a bidirectionally expanded learning approach, termed Dense Policy, to establish a new paradigm for autoregressive policies in action prediction. It employs a lightweight encoder-only architecture to iteratively unfold the action sequence from an initial single frame into the target sequence in a coarse-to-fine manner with logarithmic-time inference. Extensive experiments validate that our dense policy has superior autoregressive learning capabilities and can surpass existing holistic generative policies. Our policy, example data, and training code will be publicly available upon publication. Project page: https: //selen-suyue.github.io/DspNet/.
REArtGS: Reconstructing and Generating Articulated Objects via 3D Gaussian Splatting with Geometric and Motion Constraints
Mar 09, 2025Articulated objects, as prevalent entities in human life, their 3D representations play crucial roles across various applications. However, achieving both high-fidelity textured surface reconstruction and dynamic generation for articulated objects remains challenging for existing methods. In this paper, we present REArtGS, a novel framework that introduces additional geometric and motion constraints to 3D Gaussian primitives, enabling high-quality textured surface reconstruction and generation for articulated objects. Specifically, given multi-view RGB images of arbitrary two states of articulated objects, we first introduce an unbiased Signed Distance Field (SDF) guidance to regularize Gaussian opacity fields, enhancing geometry constraints and improving surface reconstruction quality. Then we establish deformable fields for 3D Gaussians constrained by the kinematic structures of articulated objects, achieving unsupervised generation of surface meshes in unseen states. Extensive experiments on both synthetic and real datasets demonstrate our approach achieves high-quality textured surface reconstruction for given states, and enables high-fidelity surface generation for unseen states. Codes will be released within the next four months.
AirExo-2: Scaling up Generalizable Robotic Imitation Learning with Low-Cost Exoskeletons
Mar 05, 2025Scaling up imitation learning for real-world applications requires efficient and cost-effective demonstration collection methods. Current teleoperation approaches, though effective, are expensive and inefficient due to the dependency on physical robot platforms. Alternative data sources like in-the-wild demonstrations can eliminate the need for physical robots and offer more scalable solutions. However, existing in-the-wild data collection devices have limitations: handheld devices offer restricted in-hand camera observation, while whole-body devices often require fine-tuning with robot data due to action inaccuracies. In this paper, we propose AirExo-2, a low-cost exoskeleton system for large-scale in-the-wild demonstration collection. By introducing the demonstration adaptor to transform the collected in-the-wild demonstrations into pseudo-robot demonstrations, our system addresses key challenges in utilizing in-the-wild demonstrations for downstream imitation learning in real-world environments. Additionally, we present RISE-2, a generalizable policy that integrates 2D and 3D perceptions, outperforming previous imitation learning policies in both in-domain and out-of-domain tasks, even with limited demonstrations. By leveraging in-the-wild demonstrations collected and transformed by the AirExo-2 system, without the need for additional robot demonstrations, RISE-2 achieves comparable or superior performance to policies trained with teleoperated data, highlighting the potential of AirExo-2 for scalable and generalizable imitation learning. Project page: https://airexo.tech/airexo2