 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLKV: Efficiently Scaling up Large Embedding Model Training with Disk-based Key-Value Storage
Apr 02, 2025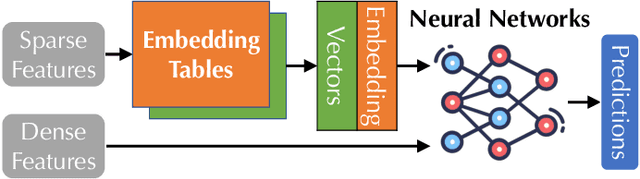
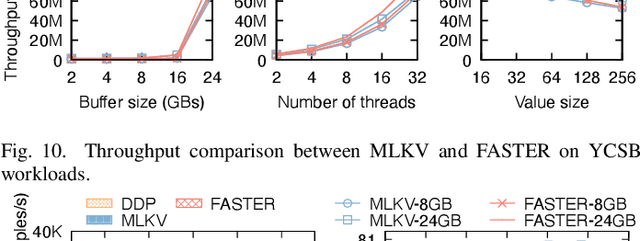
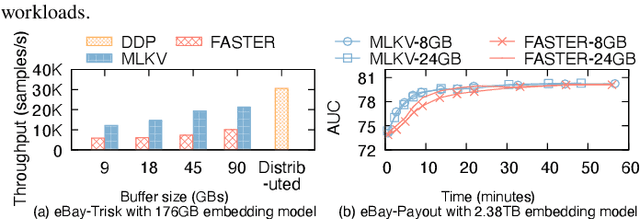
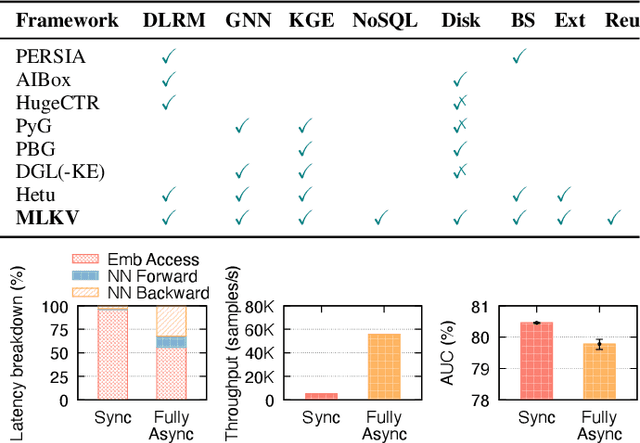
Many modern machine learning (ML) methods rely on embedding models to learn vector representations (embeddings) for a set of entities (embedding tables). As increasingly diverse ML applications utilize embedding models and embedding tables continue to grow in size and number, there has been a surge in the ad-hoc development of specialized frameworks targeted to train large embedding models for specific tasks. Although the scalability issues that arise in different embedding model training tasks are similar, each of these frameworks independently reinvents and customizes storage components for specific tasks, leading to substantial duplicated engineering efforts in both development and deployment. This paper presents MLKV, an efficient, extensible, and reusable data storage framework designed to address the scalability challenges in embedding model training, specifically data stall and staleness. MLKV augments disk-based key-value storage by democratizing optimizations that were previously exclusive to individual specialized frameworks and provides easy-to-use interfaces for embedding model training tasks. Extensive experiments on open-source workloads, as well as applications in eBay's payment transaction risk detection and seller payment risk detection, show that MLKV outperforms offloading strategies built on top of industrial-strength key-value stores by 1.6-12.6x. MLKV is open-source at https://github.com/llm-db/MLKV.
BASKET: A Large-Scale Video Dataset for Fine-Grained Skill Estimation
Mar 26, 2025We present BASKET, a large-scale basketball video dataset for fine-grained skill estimation. BASKET contains 4,477 hours of video capturing 32,232 basketball players from all over the world. Compared to prior skill estimation datasets, our dataset includes a massive number of skilled participants with unprecedented diversity in terms of gender, age, skill level, geographical location, etc. BASKET includes 20 fine-grained basketball skills, challenging modern video recognition models to capture the intricate nuances of player skill through in-depth video analysis. Given a long highlight video (8-10 minutes) of a particular player, the model needs to predict the skill level (e.g., excellent, good, average, fair, poor) for each of the 20 basketball skills. Our empirical analysis reveals that the current state-of-the-art video models struggle with this task, significantly lagging behind the human baseline. We believe that BASKET could be a useful resource for developing new video models with advanced long-range, fine-grained recognition capabilities. In addition, we hope that our dataset will be useful for domain-specific applications such as fair basketball scouting, personalized player development, and many others. Dataset and code are available at https://github.com/yulupan00/BASKET.
Self-Correcting Decoding with Generative Feedback for Mitigating Hallucinations in Large Vision-Language Models
Feb 10, 2025While recent Large Vision-Language Models (LVLMs) have shown remarkable performance in multi-modal tasks, they are prone to generating hallucinatory text responses that do not align with the given visual input, which restricts their practical applicability in real-world scenarios. In this work, inspired by the observation that the text-to-image generation process is the inverse of image-conditioned response generation in LVLMs, we explore the potential of leveraging text-to-image generative models to assist in mitigating hallucinations in LVLMs. We discover that generative models can offer valuable self-feedback for mitigating hallucinations at both the response and token levels. Building on this insight, we introduce self-correcting Decoding with Generative Feedback (DeGF), a novel training-free algorithm that incorporates feedback from text-to-image generative models into the decoding process to effectively mitigate hallucinations in LVLMs. Specifically, DeGF generates an image from the initial response produced by LVLMs, which acts as an auxiliary visual reference and provides self-feedback to verify and correct the initial response through complementary or contrastive decoding. Extensive experimental results validate the effectiveness of our approach in mitigating diverse types of hallucinations, consistently surpassing state-of-the-art methods across six benchmarks. Code is available at https://github.com/zhangce01/DeGF.
Speculative Prefill: Turbocharging TTFT with Lightweight and Training-Free Token Importance Estimation
Feb 05, 2025



Improving time-to-first-token (TTFT) is an essentially important objective in modern large language model (LLM) inference engines. Because optimizing TTFT directly results in higher maximal QPS and meets the requirements of many critical applications. However, boosting TTFT is notoriously challenging since it is purely compute-bounded and the performance bottleneck shifts from the self-attention to the MLP part. We present SpecPrefill, a training free framework that accelerates the inference TTFT for both long and medium context queries based on the following insight: LLMs are generalized enough to still preserve the quality given only a carefully chosen subset of prompt tokens. At its core, SpecPrefill leverages a lightweight model to speculate locally important tokens based on the context. These tokens, along with the necessary positional information, are then sent to the main model for processing. We evaluate SpecPrefill with a diverse set of tasks, followed by a comprehensive benchmarking of performance improvement both in a real end-to-end setting and ablation studies. SpecPrefill manages to serve Llama-3.1-405B-Instruct-FP8 with up to $7\times$ maximal end-to-end QPS on real downstream tasks and $7.66\times$ TTFT improvement during benchmarking.
BgGPT 1.0: Extending English-centric LLMs to other languages
Dec 14, 2024We present BgGPT-Gemma-2-27B-Instruct and BgGPT-Gemma-2-9B-Instruct: continually pretrained and fine-tuned versions of Google's Gemma-2 models, specifically optimized for Bulgarian language understanding and generation. Leveraging Gemma-2's multilingual capabilities and over 100 billion tokens of Bulgarian and English text data, our models demonstrate strong performance in Bulgarian language tasks, setting a new standard for language-specific AI models. Our approach maintains the robust capabilities of the original Gemma-2 models, ensuring that the English language performance remains intact. To preserve the base model capabilities, we incorporate continual learning strategies based on recent Branch-and-Merge techniques as well as thorough curation and selection of training data. We provide detailed insights into our methodology, including the release of model weights with a commercial-friendly license, enabling broader adoption by researchers, companies, and hobbyists. Further, we establish a comprehensive set of benchmarks based on non-public educational data sources to evaluate models on Bulgarian language tasks as well as safety and chat capabilities. Our findings demonstrate the effectiveness of fine-tuning state-of-the-art models like Gemma 2 to enhance language-specific AI applications while maintaining cross-lingual capabilities.
Multisource Collaborative Domain Generalization for Cross-Scene Remote Sensing Image Classification
Dec 05, 2024



Cross-scene image classification aims to transfer prior knowledge of ground materials to annotate regions with different distributions and reduce hand-crafted cost in the field of remote sensing. However, existing approaches focus on single-source domain generalization to unseen target domains, and are easily confused by large real-world domain shifts due to the limited training information and insufficient diversity modeling capacity. To address this gap, we propose a novel multi-source collaborative domain generalization framework (MS-CDG) based on homogeneity and heterogeneity characteristics of multi-source remote sensing data, which considers data-aware adversarial augmentation and model-aware multi-level diversification simultaneously to enhance cross-scene generalization performance. The data-aware adversarial augmentation adopts an adversary neural network with semantic guide to generate MS samples by adaptively learning realistic channel and distribution changes across domains. In views of cross-domain and intra-domain modeling, the model-aware diversification transforms the shared spatial-channel features of MS data into the class-wise prototype and kernel mixture module, to address domain discrepancies and cluster different classes effectively. Finally, the joint classification of original and augmented MS samples is employed by introducing a distribution consistency alignment to increase model diversity and ensure better domain-invariant representation learning. Extensive experiments on three public MS remote sensing datasets demonstrate the superior performance of the proposed method when benchmarked with the state-of-the-art methods.
ΩSFormer: Dual-Modal Ω-like Super-Resolution Transformer Network for Cross-scale and High-accuracy Terraced Field Vectorization Extraction
Nov 26, 2024



Terraced field is a significant engineering practice for soil and water conservation (SWC). Terraced field extraction from remotely sensed imagery is the foundation for monitoring and evaluating SWC. This study is the first to propose a novel dual-modal {\Omega}-like super-resolution Transformer network for intelligent TFVE, offering the following advantages: (1) reducing edge segmentation error from conventional multi-scale downsampling encoder, through fusing original high-resolution features with downsampling features at each step of encoder and leveraging a multi-head attention mechanism; (2) improving the accuracy of TFVE by proposing a {\Omega}-like network structure, which fully integrates rich high-level features from both spectral and terrain data to form cross-scale super-resolution features; (3) validating an optimal fusion scheme for cross-modal and cross-scale (i.e., inconsistent spatial resolution between remotely sensed imagery and DEM) super-resolution feature extraction; (4) mitigating uncertainty between segmentation edge pixels by a coarse-to-fine and spatial topological semantic relationship optimization (STSRO) segmentation strategy; (5) leveraging contour vibration neural network to continuously optimize parameters and iteratively vectorize terraced fields from semantic segmentation results. Moreover, a DMRVD for deep-learning-based TFVE was created for the first time, which covers nine study areas in four provinces of China, with a total coverage area of 22441 square kilometers. To assess the performance of {\Omega}SFormer, classic and SOTA networks were compared. The mIOU of {\Omega}SFormer has improved by 0.165, 0.297 and 0.128 respectively, when compared with best accuracy single-modal remotely sensed imagery, single-modal DEM and dual-modal result.
RedPajama: an Open Dataset for Training Large Language Models
Nov 19, 2024Large language models are increasingly becoming a cornerstone technology in artificial intelligence, the sciences, and society as a whole, yet the optimal strategies for dataset composition and filtering remain largely elusive. Many of the top-performing models lack transparency in their dataset curation and model development processes, posing an obstacle to the development of fully open language models. In this paper, we identify three core data-related challenges that must be addressed to advance open-source language models. These include (1) transparency in model development, including the data curation process, (2) access to large quantities of high-quality data, and (3) availability of artifacts and metadata for dataset curation and analysis. To address these challenges, we release RedPajama-V1, an open reproduction of the LLaMA training dataset. In addition, we release RedPajama-V2, a massive web-only dataset consisting of raw, unfiltered text data together with quality signals and metadata. Together, the RedPajama datasets comprise over 100 trillion tokens spanning multiple domains and with their quality signals facilitate the filtering of data, aiming to inspire the development of numerous new datasets. To date, these datasets have already been used in the training of strong language models used in production, such as Snowflake Arctic, Salesforce's XGen and AI2's OLMo. To provide insight into the quality of RedPajama, we present a series of analyses and ablation studies with decoder-only language models with up to 1.6B parameters. Our findings demonstrate how quality signals for web data can be effectively leveraged to curate high-quality subsets of the dataset, underscoring the potential of RedPajama to advance the development of transparent and high-performing language models at scale.
CATCH: Complementary Adaptive Token-level Contrastive Decoding to Mitigate Hallucinations in LVLMs
Nov 19, 2024



Large Vision-Language Model (LVLM) systems have demonstrated impressive vision-language reasoning capabilities but suffer from pervasive and severe hallucination issues, posing significant risks in critical domains such as healthcare and autonomous systems. Despite previous efforts to mitigate hallucinations, a persistent issue remains: visual defect from vision-language misalignment, creating a bottleneck in visual processing capacity. To address this challenge, we develop Complementary Adaptive Token-level Contrastive Decoding to Mitigate Hallucinations in LVLMs (CATCH), based on the Information Bottleneck theory. CATCH introduces Complementary Visual Decoupling (CVD) for visual information separation, Non-Visual Screening (NVS) for hallucination detection, and Adaptive Token-level Contrastive Decoding (ATCD) for hallucination mitigation. CATCH addresses issues related to visual defects that cause diminished fine-grained feature perception and cumulative hallucinations in open-ended scenarios. It is applicable to various visual question-answering tasks without requiring any specific data or prior knowledge, and generalizes robustly to new tasks without additional training, opening new possibilities for advancing LVLM in various challenging applications.
Dual Prototype Evolving for Test-Time Generalization of Vision-Language Models
Oct 16, 2024



Test-time adaptation, which enables models to generalize to diverse data with unlabeled test samples, holds significant value in real-world scenarios. Recently, researchers have applied this setting to advanced pre-trained vision-language models (VLMs), developing approaches such as test-time prompt tuning to further extend their practical applicability. However, these methods typically focus solely on adapting VLMs from a single modality and fail to accumulate task-specific knowledge as more samples are processed. To address this, we introduce Dual Prototype Evolving (DPE), a novel test-time adaptation approach for VLMs that effectively accumulates task-specific knowledge from multi-modalities. Specifically, we create and evolve two sets of prototypes--textual and visual--to progressively capture more accurate multi-modal representations for target classes during test time. Moreover, to promote consistent multi-modal representations, we introduce and optimize learnable residuals for each test sample to align the prototypes from both modalities. Extensive experimental results on 15 benchmark datasets demonstrate that our proposed DPE consistently outperforms previous state-of-the-art methods while also exhibiting competitive computational efficiency. Code is available at https://github.com/zhangce01/DPE-CLIP.