 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Correcting Decoding with Generative Feedback for Mitigating Hallucinations in Large Vision-Language Models
Feb 10, 2025While recent Large Vision-Language Models (LVLMs) have shown remarkable performance in multi-modal tasks, they are prone to generating hallucinatory text responses that do not align with the given visual input, which restricts their practical applicability in real-world scenarios. In this work, inspired by the observation that the text-to-image generation process is the inverse of image-conditioned response generation in LVLMs, we explore the potential of leveraging text-to-image generative models to assist in mitigating hallucinations in LVLMs. We discover that generative models can offer valuable self-feedback for mitigating hallucinations at both the response and token levels. Building on this insight, we introduce self-correcting Decoding with Generative Feedback (DeGF), a novel training-free algorithm that incorporates feedback from text-to-image generative models into the decoding process to effectively mitigate hallucinations in LVLMs. Specifically, DeGF generates an image from the initial response produced by LVLMs, which acts as an auxiliary visual reference and provides self-feedback to verify and correct the initial response through complementary or contrastive decoding. Extensive experimental results validate the effectiveness of our approach in mitigating diverse types of hallucinations, consistently surpassing state-of-the-art methods across six benchmarks. Code is available at https://github.com/zhangce01/DeGF.
Evaluating Deep Unlearning in Large Language Models
Oct 19, 2024



Machine unlearning is a key requirement of many data protection regulations such as GDPR. Prior work on unlearning has mostly considered superficial unlearning tasks where a single or a few related pieces of information are required to be removed. However, the task of unlearning a fact is much more challenging in recent large language models (LLMs), because the facts in LLMs can be deduced from each other. In this work, we investigate whether current unlearning methods for LLMs succeed beyond superficial unlearning of facts. Specifically, we formally propose a framework and a definition for deep unlearning facts that are interrelated. We design the metric, recall, to quantify the extent of deep unlearning. To systematically evaluate deep unlearning, we construct a synthetic dataset EDU-RELAT, which consists of a synthetic knowledge base of family relationships and biographies, together with a realistic logical rule set that connects them. We use this dataset to test four unlearning methods in four LLMs at different sizes. Our findings reveal that in the task of deep unlearning only a single fact, they either fail to properly unlearn with high recall, or end up unlearning many other irrelevant facts. Our dataset and code are publicly available at: https://github.com/wrh14/deep_unlearning.
IoT-LM: Large Multisensory Language Models for the Internet of Things
Jul 13, 2024



The Internet of Things (IoT) network integrating billions of smart physical devices embedded with sensors, software, and communication technologies is a critical and rapidly expanding component of our modern world. The IoT ecosystem provides a rich source of real-world modalities such as motion, thermal, geolocation, imaging, depth, sensors, and audio to recognize the states of humans and physical objects. Machine learning presents a rich opportunity to automatically process IoT data at scale, enabling efficient inference for understanding human wellbeing, controlling physical devices, and interconnecting smart cities. To realize this potential, we introduce IoT-LM, an open-source large multisensory language model tailored for the IoT ecosystem. IoT-LM is enabled by two technical contributions: the first is MultiIoT, the most expansive unified IoT dataset to date, encompassing over 1.15 million samples from 12 modalities and 8 tasks prepared for multisensory pre-training and instruction-tuning. The second is a new multisensory multitask adapter layer to condition pre-trained large language models on multisensory IoT data. Not only does IoT-LM yield substantial improvements on 8 supervised IoT classification tasks, but it also demonstrates new interactive question-answering, reasoning, and dialog capabilities conditioned on IoT sensors. We release IoT-LM's data sources and new multisensory language modeling framework.
MultiIoT: Towards Large-scale Multisensory Learning for the Internet of Things
Nov 10, 2023



The Internet of Things (IoT), the network integrating billions of smart physical devices embedded with sensors, software, and communication technologies for the purpose of connecting and exchanging data with other devices and systems, is a critical and rapidly expanding component of our modern world. The IoT ecosystem provides a rich source of real-world modalities such as motion, thermal, geolocation, imaging, depth, sensors, video, and audio for prediction tasks involving the pose, gaze, activities, and gestures of humans as well as the touch, contact, pose, 3D of physical objects. Machine learning presents a rich opportunity to automatically process IoT data at scale, enabling efficient inference for impact in understanding human wellbeing, controlling physical devices, and interconnecting smart cities. To develop machine learning technologies for IoT, this paper proposes MultiIoT, the most expansive IoT benchmark to date, encompassing over 1.15 million samples from 12 modalities and 8 tasks. MultiIoT introduces unique challenges involving (1) learning from many sensory modalities, (2) fine-grained interactions across long temporal ranges, and (3) extreme heterogeneity due to unique structure and noise topologies in real-world sensors. We also release a set of strong modeling baselines, spanning modality and task-specific methods to multisensory and multitask models to encourage future research in multisensory representation learning for IoT.
Iterative Refinement of the Approximate Posterior for Directed Belief Networks
Feb 20, 2018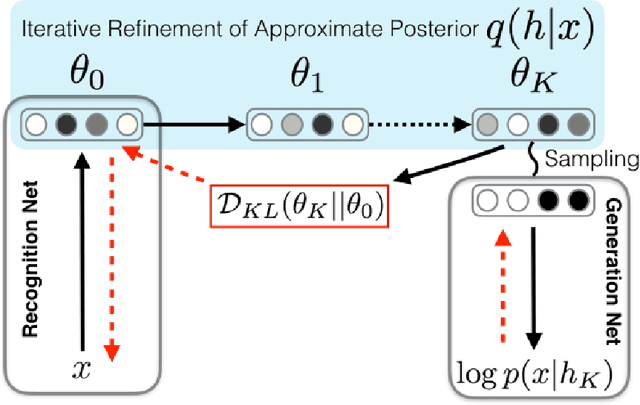
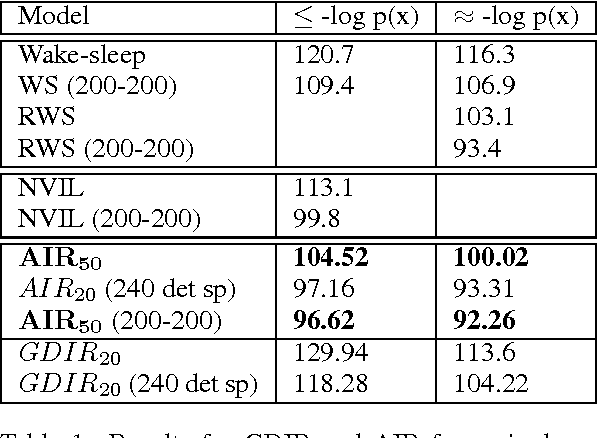

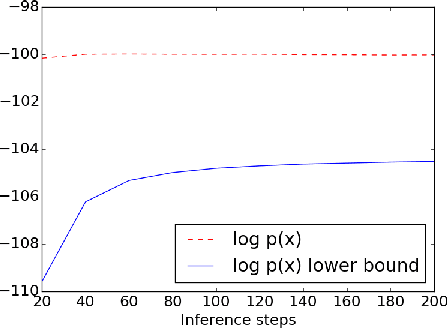
Variational methods that rely on a recognition network to approximate the posterior of directed graphical models offer better inference and learning than previous methods. Recent advances that exploit the capacity and flexibility in this approach have expanded what kinds of models can be trained. However, as a proposal for the posterior, the capacity of the recognition network is limited, which can constrain the representational power of the generative model and increase the variance of Monte Carlo estimates. To address these issues, we introduce an iterative refinement procedure for improving the approximate posterior of the recognition network and show that training with the refined posterior is competitive with state-of-the-art methods. The advantages of refinement are further evident in an increased effective sample size, which implies a lower variance of gradient estimates.