 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersia: An Open, Hybrid System Scaling Deep Learning-based Recommenders up to 100 Trillion Parameters
Nov 23, 2021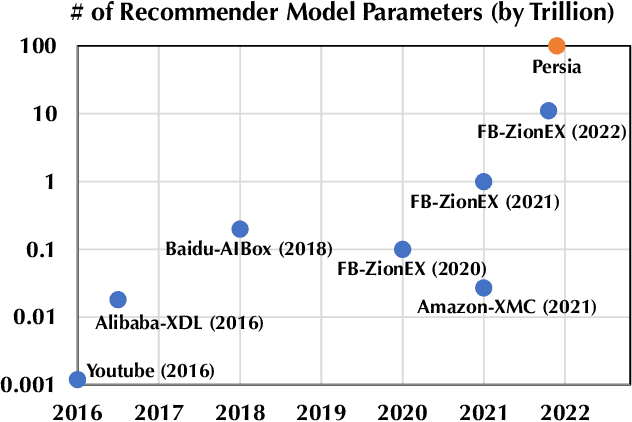
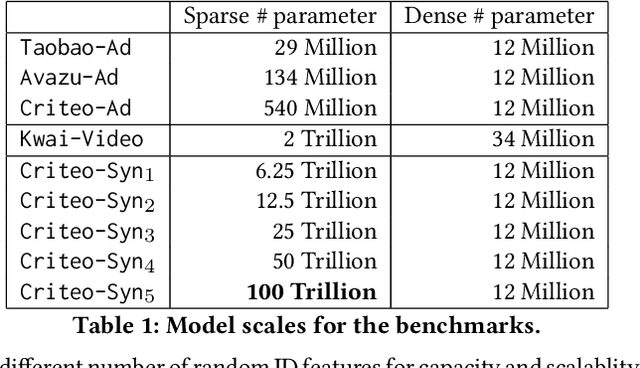
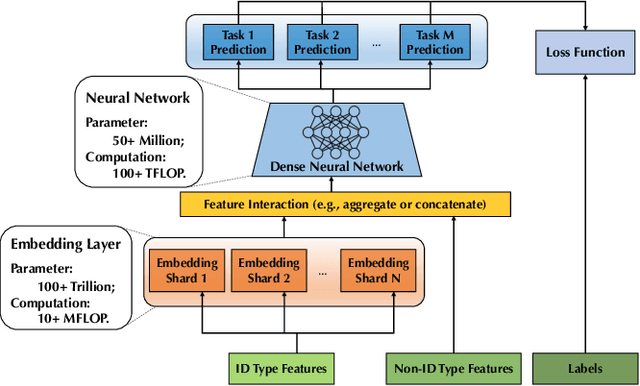
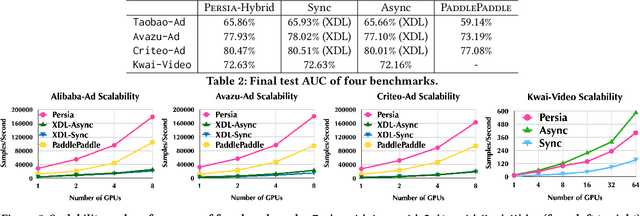
Deep learning based models have dominated the current landscape of production recommender systems. Furthermore, recent years have witnessed an exponential growth of the model scale--from Google's 2016 model with 1 billion parameters to the latest Facebook's model with 12 trillion parameters. Significant quality boost has come with each jump of the model capacity, which makes us believe the era of 100 trillion parameters is around the corner. However, the training of such models is challenging even within industrial scale data centers. This difficulty is inherited from the staggering heterogeneity of the training computation--the model's embedding layer could include more than 99.99% of the total model size, which is extremely memory-intensive; while the rest neural network is increasingly computation-intensive. To support the training of such huge models, an efficient distributed training system is in urgent need. In this paper, we resolve this challenge by careful co-design of both the optimization algorithm and the distributed system architecture. Specifically, in order to ensure both the training efficiency and the training accuracy, we design a novel hybrid training algorithm, where the embedding layer and the dense neural network are handled by different synchronization mechanisms; then we build a system called Persia (short for parallel recommendation training system with hybrid acceleration) to support this hybrid training algorithm. Both theoretical demonstration and empirical study up to 100 trillion parameters have conducted to justified the system design and implementation of Persia. We make Persia publicly available (at https://github.com/PersiaML/Persia) so that anyone would be able to easily train a recommender model at the scale of 100 trillion parameters.
Efficient Hybrid Transformer: Learning Global-local Context for Urban Scene Segmentation
Oct 13, 2021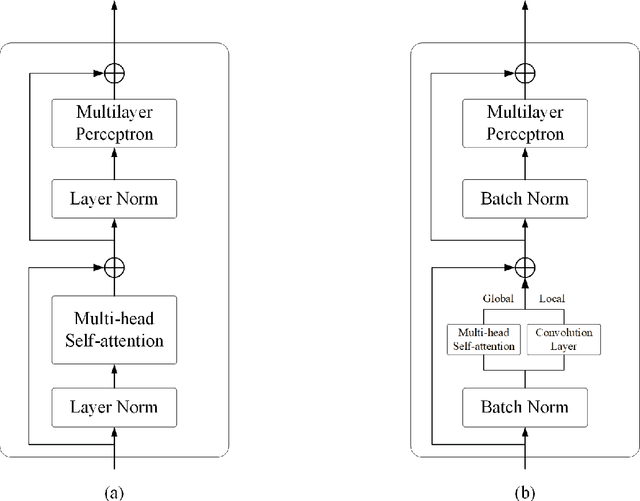

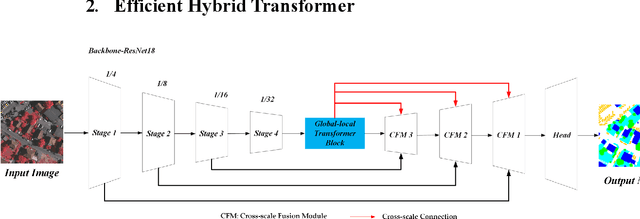
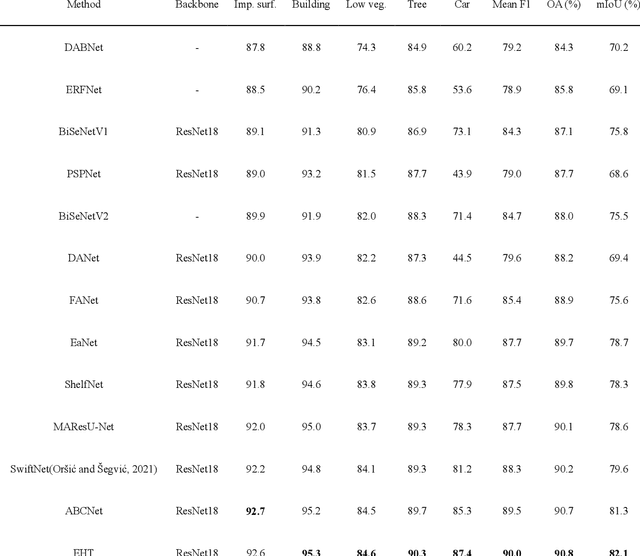
Semantic segmentation of fine-resolution urban scene images plays a vital role in extensive practical applications, such as land cover mapping, urban change detection, environmental protection and economic assessment. Driven by rapid developments in deep learning technologies, the convolutional neural network (CNN) has dominated the semantic segmentation task for many years. Convolutional neural networks adopt hierarchical feature representation, demonstrating strong local information extraction. However, the local property of the convolution layer limits the network from capturing global context that is crucial for precise segmentation. Recently, Transformer comprise a hot topic in the computer vision domain. Transformer demonstrates the great capability of global information modelling, boosting many vision tasks, such as image classification, object detection and especially semantic segmentation. In this paper, we propose an efficient hybrid Transformer (EHT) for real-time urban scene segmentation. The EHT adopts a hybrid structure with and CNN-based encoder and a transformer-based decoder, learning global-local context with lower computation. Extensive experiments demonstrate that our EHT has faster inference speed with competitive accuracy compared with state-of-the-art lightweight models. Specifically, the proposed EHT achieves a 66.9% mIoU on the UAVid test set and outperforms other benchmark networks significantly. The code will be available soon.
Towards Automatic Bias Detection in Knowledge Graphs
Sep 19, 2021

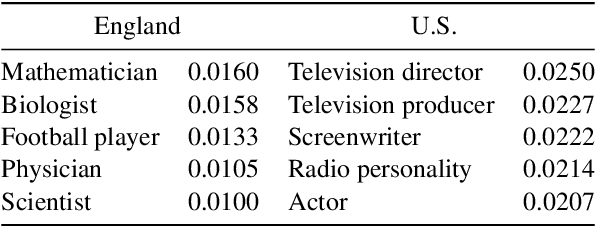
With the recent surge in social applications relying on knowledge graphs, the need for techniques to ensure fairness in KG based methods is becoming increasingly evident. Previous works have demonstrated that KGs are prone to various social biases, and have proposed multiple methods for debiasing them. However, in such studies, the focus has been on debiasing techniques, while the relations to be debiased are specified manually by the user. As manual specification is itself susceptible to human cognitive bias, there is a need for a system capable of quantifying and exposing biases, that can support more informed decisions on what to debias. To address this gap in the literature, we describe a framework for identifying biases present in knowledge graph embeddings, based on numerical bias metrics. We illustrate the framework with three different bias measures on the task of profession prediction, and it can be flexibly extended to further bias definitions and applications. The relations flagged as biased can then be handed to decision makers for judgement upon subsequent debiasing.
Evaluating Bayes Error Estimators on Read-World Datasets with FeeBee
Aug 30, 2021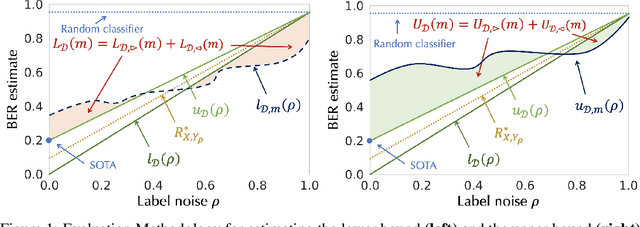
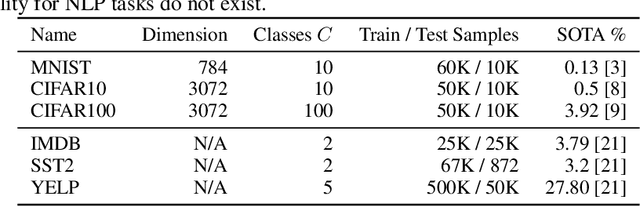
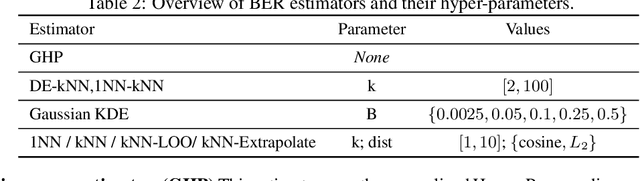
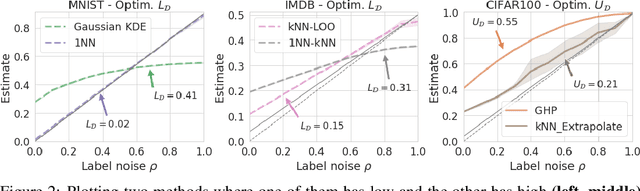
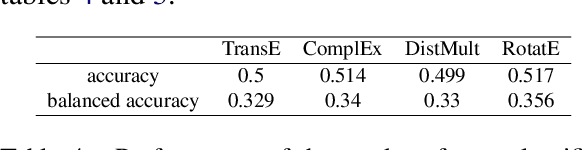
The Bayes error rate (BER) is a fundamental concept in machine learning that quantifies the best possible accuracy any classifier can achieve on a fixed probability distribution. Despite years of research on building estimators of lower and upper bounds for the BER, these were usually compared only on synthetic datasets with known probability distributions, leaving two key questions unanswered: (1) How well do they perform on real-world datasets?, and (2) How practical are they? Answering these is not trivial. Apart from the obvious challenge of an unknown BER for real-world datasets, there are two main aspects any BER estimator needs to overcome in order to be applicable in real-world settings: (1) the computational and sample complexity, and (2) the sensitivity and selection of hyper-parameters. In this work, we propose FeeBee, the first principled framework for analyzing and comparing BER estimators on any modern real-world dataset with unknown probability distribution. We achieve this by injecting a controlled amount of label noise and performing multiple evaluations on a series of different noise levels, supported by a theoretical result which allows drawing conclusions about the evolution of the BER. By implementing and analyzing 7 multi-class BER estimators on 6 commonly used datasets of the computer vision and NLP domains, FeeBee allows a thorough study of these estimators, clearly identifying strengths and weaknesses of each, whilst being easily deployable on any future BER estimator.
LinkTeller: Recovering Private Edges from Graph Neural Networks via Influence Analysis
Aug 20, 2021
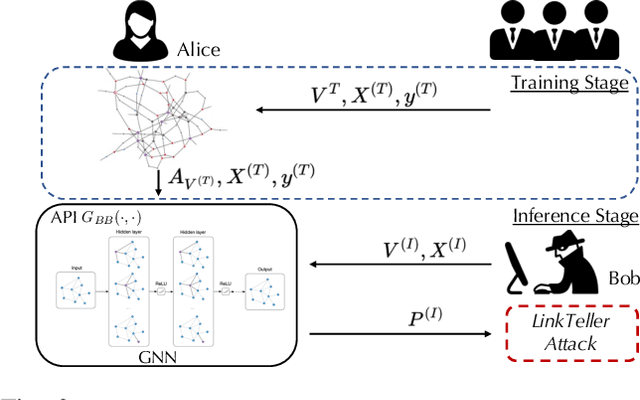
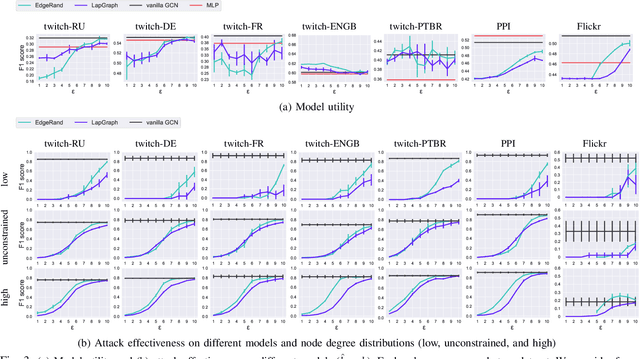
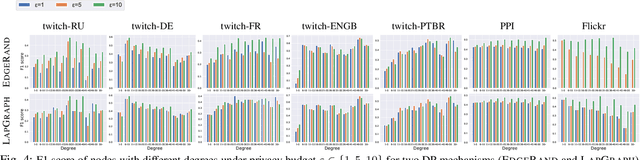
Graph structured data have enabled several successful applications such as recommendation systems and traffic prediction, given the rich node features and edges information. However, these high-dimensional features and high-order adjacency information are usually heterogeneous and held by different data holders in practice. Given such vertical data partition (e.g., one data holder will only own either the node features or edge information), different data holders have to develop efficient joint training protocols rather than directly transfer data to each other due to privacy concerns. In this paper, we focus on the edge privacy, and consider a training scenario where Bob with node features will first send training node features to Alice who owns the adjacency information. Alice will then train a graph neural network (GNN) with the joint information and release an inference API. During inference, Bob is able to provide test node features and query the API to obtain the predictions for test nodes. Under this setting, we first propose a privacy attack LinkTeller via influence analysis to infer the private edge information held by Alice via designing adversarial queries for Bob. We then empirically show that LinkTeller is able to recover a significant amount of private edges, outperforming existing baselines. To further evaluate the privacy leakage, we adapt an existing algorithm for differentially private graph convolutional network (DP GCN) training and propose a new DP GCN mechanism LapGraph. We show that these DP GCN mechanisms are not always resilient against LinkTeller empirically under mild privacy guarantees ($\varepsilon>5$). Our studies will shed light on future research towards designing more resilient privacy-preserving GCN models; in the meantime, provide an in-depth understanding of the tradeoff between GCN model utility and robustness against potential privacy attacks.
Tackling the Overestimation of Forest Carbon with Deep Learning and Aerial Imagery
Aug 19, 2021
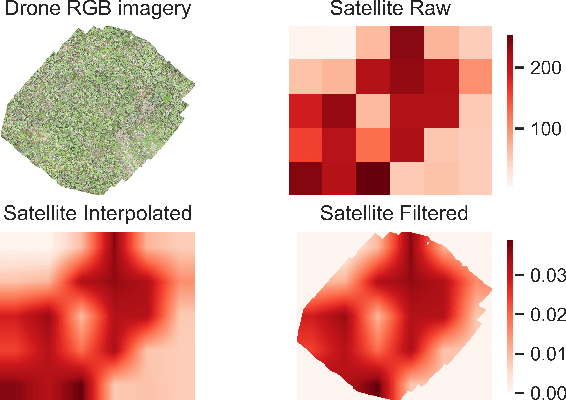
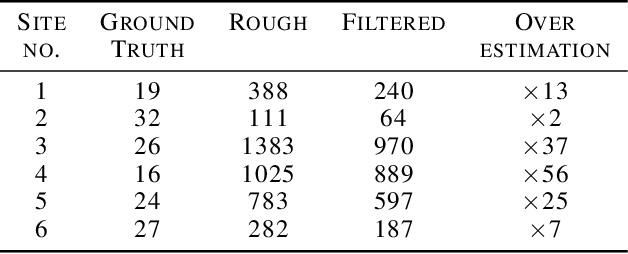
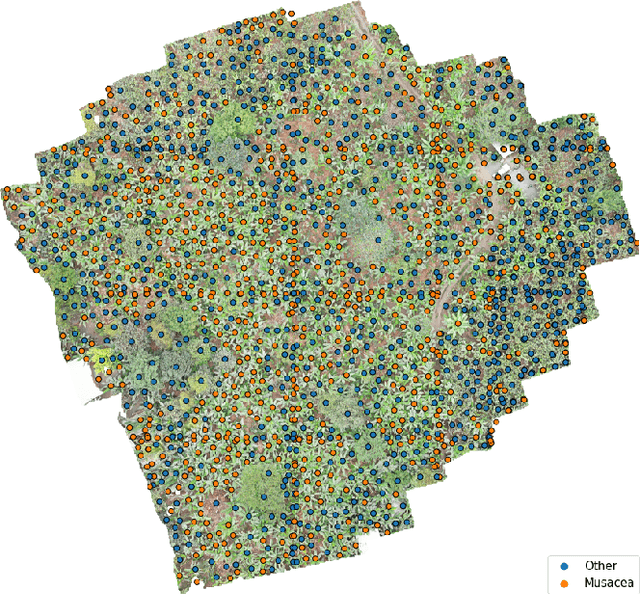
Forest carbon offsets are increasingly popular and can play a significant role in financing climate mitigation, forest conservation, and reforestation. Measuring how much carbon is stored in forests is, however, still largely done via expensive, time-consuming, and sometimes unaccountable field measurements. To overcome these limitations, many verification bodies are leveraging machine learning (ML) algorithms to estimate forest carbon from satellite or aerial imagery. Aerial imagery allows for tree species or family classification, which improves the satellite imagery-based forest type classification. However, aerial imagery is significantly more expensive to collect and it is unclear by how much the higher resolution improves the forest carbon estimation. This proposal paper describes the first systematic comparison of forest carbon estimation from aerial imagery, satellite imagery, and ground-truth field measurements via deep learning-based algorithms for a tropical reforestation project. Our initial results show that forest carbon estimates from satellite imagery can overestimate above-ground biomass by up to 10-times for tropical reforestation projects. The significant difference between aerial and satellite-derived forest carbon measurements shows the potential for aerial imagery-based ML algorithms and raises the importance to extend this study to a global benchmark between options for carbon measurements.
VolcanoML: Speeding up End-to-End AutoML via Scalable Search Space Decomposition
Jul 20, 2021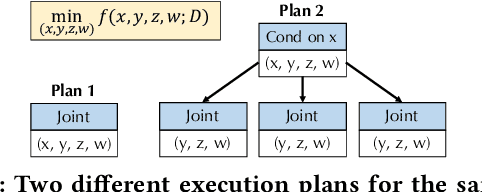
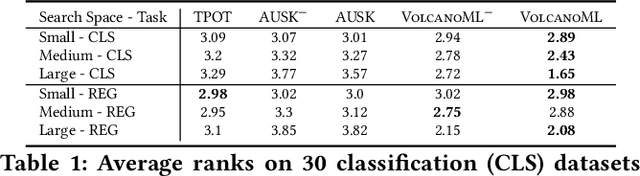
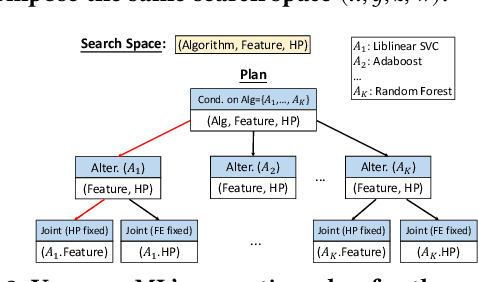
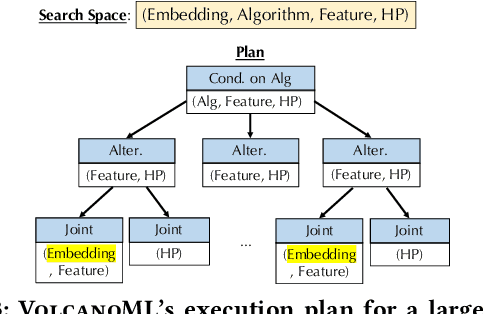
End-to-end AutoML has attracted intensive interests from both academia and industry, which automatically searches for ML pipelines in a space induced by feature engineering, algorithm/model selection, and hyper-parameter tuning. Existing AutoML systems, however, suffer from scalability issues when applying to application domains with large, high-dimensional search spaces. We present VolcanoML, a scalable and extensible framework that facilitates systematic exploration of large AutoML search spaces. VolcanoML introduces and implements basic building blocks that decompose a large search space into smaller ones, and allows users to utilize these building blocks to compose an execution plan for the AutoML problem at hand. VolcanoML further supports a Volcano-style execution model - akin to the one supported by modern database systems - to execute the plan constructed. Our evaluation demonstrates that, not only does VolcanoML raise the level of expressiveness for search space decomposition in AutoML, it also leads to actual findings of decomposition strategies that are significantly more efficient than the ones employed by state-of-the-art AutoML systems such as auto-sklearn.
BAGUA: Scaling up Distributed Learning with System Relaxations
Jul 12, 2021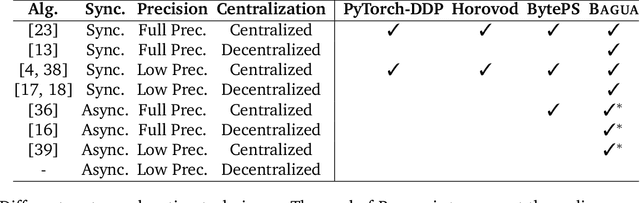
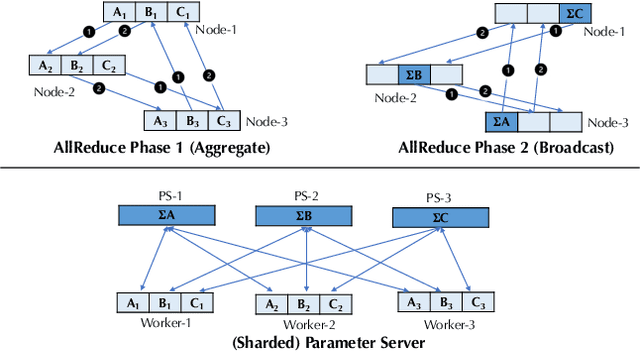
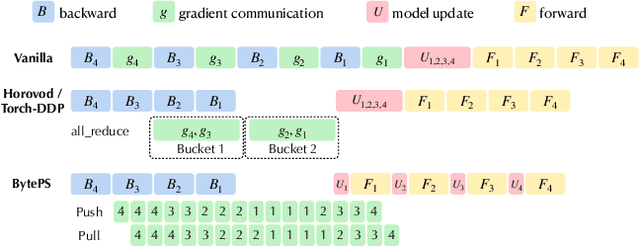

Recent years have witnessed a growing list of systems for distributed data-parallel training. Existing systems largely fit into two paradigms, i.e., parameter server and MPI-style collective operations. On the algorithmic side, researchers have proposed a wide range of techniques to lower the communication via system relaxations: quantization, decentralization, and communication delay. However, most, if not all, existing systems only rely on standard synchronous and asynchronous stochastic gradient (SG) based optimization, therefore, cannot take advantage of all possible optimizations that the machine learning community has been developing recently. Given this emerging gap between the current landscapes of systems and theory, we build BAGUA, a communication framework whose design goal is to provide a system abstraction that is both flexible and modular to support state-of-the-art system relaxation techniques of distributed training. Powered by the new system design, BAGUA has a great ability to implement and extend various state-of-the-art distributed learning algorithms. In a production cluster with up to 16 machines (128 GPUs), BAGUA can outperform PyTorch-DDP, Horovod and BytePS in the end-to-end training time by a significant margin (up to 1.95 times) across a diverse range of tasks. Moreover, we conduct a rigorous tradeoff exploration showing that different algorithms and system relaxations achieve the best performance over different network conditions.
Attention-based Neural Network for Driving Environment Complexity Perception
Jun 21, 2021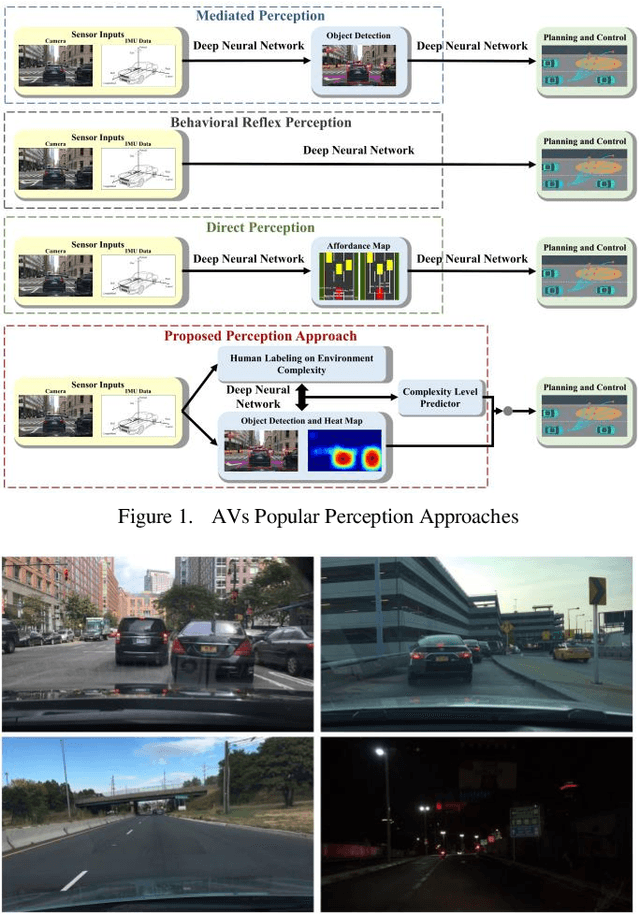
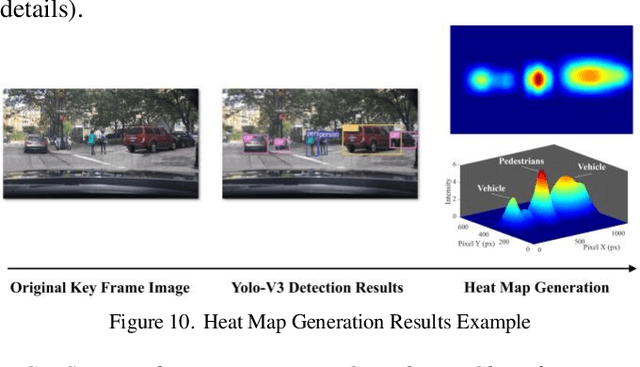

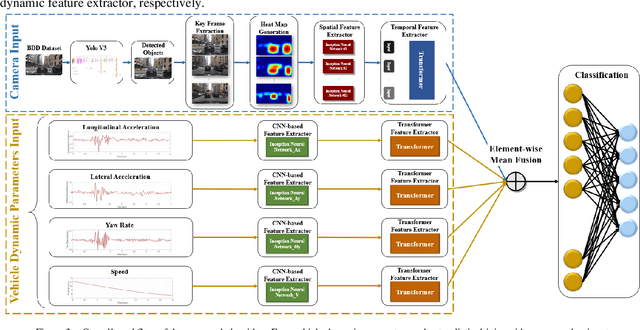
Environment perception is crucial for autonomous vehicle (AV) safety. Most existing AV perception algorithms have not studied the surrounding environment complexity and failed to include the environment complexity parameter. This paper proposes a novel attention-based neural network model to predict the complexity level of the surrounding driving environment. The proposed model takes naturalistic driving videos and corresponding vehicle dynamics parameters as input. It consists of a Yolo-v3 object detection algorithm, a heat map generation algorithm, CNN-based feature extractors, and attention-based feature extractors for both video and time-series vehicle dynamics data inputs to extract features. The output from the proposed algorithm is a surrounding environment complexity parameter. The Berkeley DeepDrive dataset (BDD Dataset) and subjectively labeled surrounding environment complexity levels are used for model training and validation to evaluate the algorithm. The proposed attention-based network achieves 91.22% average classification accuracy to classify the surrounding environment complexity. It proves that the environment complexity level can be accurately predicted and applied for future AVs' environment perception studies.
Knowledge Enhanced Machine Learning Pipeline against Diverse Adversarial Attacks
Jun 11, 2021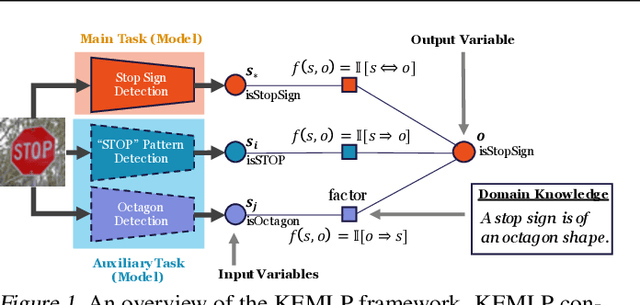
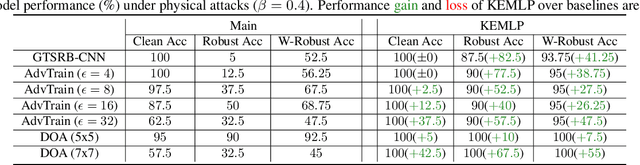
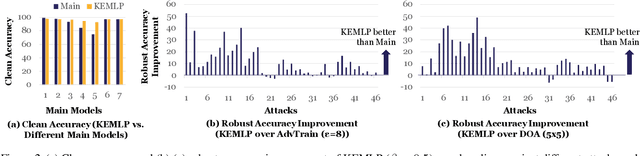
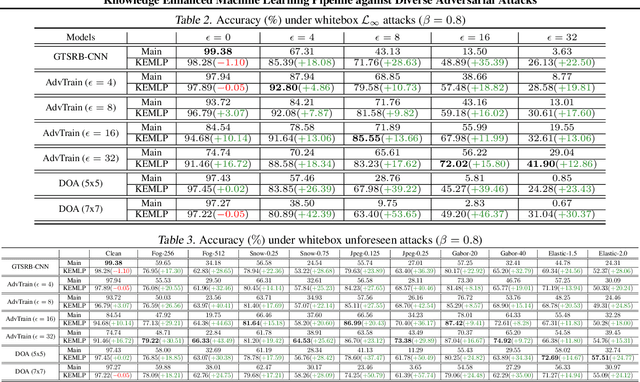
Despite the great successes achieved by deep neural networks (DNNs), recent studies show that they are vulnerable against adversarial examples, which aim to mislead DNNs by adding small adversarial perturbations. Several defenses have been proposed against such attacks, while many of them have been adaptively attacked. In this work, we aim to enhance the ML robustness from a different perspective by leveraging domain knowledge: We propose a Knowledge Enhanced Machine Learning Pipeline (KEMLP) to integrate domain knowledge (i.e., logic relationships among different predictions) into a probabilistic graphical model via first-order logic rules. In particular, we develop KEMLP by integrating a diverse set of weak auxiliary models based on their logical relationships to the main DNN model that performs the target task. Theoretically, we provide convergence results and prove that, under mild conditions, the prediction of KEMLP is more robust than that of the main DNN model. Empirically, we take road sign recognition as an example and leverage the relationships between road signs and their shapes and contents as domain knowledge. We show that compared with adversarial training and other baselines, KEMLP achieves higher robustness against physical attacks, $\mathcal{L}_p$ bounded attacks, unforeseen attacks, and natural corruptions under both whitebox and blackbox settings, while still maintaining high clean accuracy.