 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Representation Learning Beyond Pixels: Unifying Raster Data and Vector Semantics for Human-Centric Geospatial Foundation Models
Jun 01, 2026Earth Observation (EO) has fundamentally transformed the monitoring of environmental processes and human activities up to planetary scale. Recent advances in self-supervised learning have given rise to Earth Observation Foundation Models (EOFMs), which leverage petabyte-scale unlabeled EO data to learn transferable representations across a wide range of downstream geospatial tasks. Despite these advances, current EOFMs remain largely confined to raster modalities, overlooking the rich, structured information encoded in openly-accessible vector data sources such as OpenStreetMap and Overture. Vector data provides explicit and compact representations of geographic entities, including geometry, topology, and semantic relationships, offering critical contextual signals that are often ambiguous or inaccessible in imagery alone. Raster and vector data thus represent complementary views of geographic space: raster data captures continuous physical and spectral patterns, while vector data encodes discrete objects and their relational structure and often represents more of the human rather than the physical systems (e.g. social or demographic data). However, existing geospatial representation learning paradigms treat these modalities in isolation, relying on imperfect and often lossy transformations to bridge them. This perspective paper calls for a paradigm shift toward joint Spatial Representation Learning (SRL) in an unified embedding space that integrate raster perception with vector-based reasoning. Building on emerging efforts in multimodal geospatial learning, we highlight conceptual foundations, technical challenges, and promising directions for aligning heterogeneous spatial data sources. We contend that such integration is essential for developing next-generation geospatial AI systems capable of more accurate, interpretable, and semantically grounded understanding of the Earth.
EarthEmbeddingExplorer: A Web Application for Cross-Modal Retrieval of Global Satellite Images
Mar 31, 2026While the Earth observation community has witnessed a surge in high-impact foundation models and global Earth embedding datasets, a significant barrier remains in translating these academic assets into freely accessible tools. This tutorial introduces EarthEmbeddingExplorer, an interactive web application designed to bridge this gap, transforming static research artifacts into dynamic, practical workflows for discovery. We will provide a comprehensive hands-on guide to the system, detailing its cloud-native software architecture, demonstrating cross-modal queries (natural language, visual, and geolocation), and showcasing how to derive scientific insights from retrieval results. By democratizing access to precomputed Earth embeddings, this tutorial empowers researchers to seamlessly transition from state-of-the-art models and data archives to real-world application and analysis. The web application is available at https://modelscope.ai/studios/Major-TOM/EarthEmbeddingExplorer.
Localized, High-resolution Geographic Representations with Slepian Functions
Jan 30, 2026Geographic data is fundamentally local. Disease outbreaks cluster in population centers, ecological patterns emerge along coastlines, and economic activity concentrates within country borders. Machine learning models that encode geographic location, however, distribute representational capacity uniformly across the globe, struggling at the fine-grained resolutions that localized applications require. We propose a geographic location encoder built from spherical Slepian functions that concentrate representational capacity inside a region-of-interest and scale to high resolutions without extensive computational demands. For settings requiring global context, we present a hybrid Slepian-Spherical Harmonic encoder that efficiently bridges the tradeoff between local-global performance, while retaining desirable properties such as pole-safety and spherical-surface-distance preservation. Across five tasks spanning classification, regression, and image-augmented prediction, Slepian encodings outperform baselines and retain performance advantages across a wide range of neural network architectures.
Mission Critical -- Satellite Data is a Distinct Modality in Machine Learning
Feb 02, 2024Satellite data has the potential to inspire a seismic shift for machine learning -- one in which we rethink existing practices designed for traditional data modalities. As machine learning for satellite data (SatML) gains traction for its real-world impact, our field is at a crossroads. We can either continue applying ill-suited approaches, or we can initiate a new research agenda that centers around the unique characteristics and challenges of satellite data. This position paper argues that satellite data constitutes a distinct modality for machine learning research and that we must recognize it as such to advance the quality and impact of SatML research across theory, methods, and deployment. We outline critical discussion questions and actionable suggestions to transform SatML from merely an intriguing application area to a dedicated research discipline that helps move the needle on big challenges for machine learning and society.
SatCLIP: Global, General-Purpose Location Embeddings with Satellite Imagery
Nov 30, 2023



Geographic location is essential for modeling tasks in fields ranging from ecology to epidemiology to the Earth system sciences. However, extracting relevant and meaningful characteristics of a location can be challenging, often entailing expensive data fusion or data distillation from global imagery datasets. To address this challenge, we introduce Satellite Contrastive Location-Image Pretraining (SatCLIP), a global, general-purpose geographic location encoder that learns an implicit representation of locations from openly available satellite imagery. Trained location encoders provide vector embeddings summarizing the characteristics of any given location for convenient usage in diverse downstream tasks. We show that SatCLIP embeddings, pretrained on globally sampled multi-spectral Sentinel-2 satellite data, can be used in various predictive tasks that depend on location information but not necessarily satellite imagery, including temperature prediction, animal recognition in imagery, and population density estimation. Across tasks, SatCLIP embeddings consistently outperform embeddings from existing pretrained location encoders, ranging from models trained on natural images to models trained on semantic context. SatCLIP embeddings also help to improve geographic generalization. This demonstrates the potential of general-purpose location encoders and opens the door to learning meaningful representations of our planet from the vast, varied, and largely untapped modalities of geospatial data.
Geographic Location Encoding with Spherical Harmonics and Sinusoidal Representation Networks
Oct 10, 2023



Learning feature representations of geographical space is vital for any machine learning model that integrates geolocated data, spanning application domains such as remote sensing, ecology, or epidemiology. Recent work mostly embeds coordinates using sine and cosine projections based on Double Fourier Sphere (DFS) features -- these embeddings assume a rectangular data domain even on global data, which can lead to artifacts, especially at the poles. At the same time, relatively little attention has been paid to the exact design of the neural network architectures these functional embeddings are combined with. This work proposes a novel location encoder for globally distributed geographic data that combines spherical harmonic basis functions, natively defined on spherical surfaces, with sinusoidal representation networks (SirenNets) that can be interpreted as learned Double Fourier Sphere embedding. We systematically evaluate the cross-product of positional embeddings and neural network architectures across various classification and regression benchmarks and synthetic evaluation datasets. In contrast to previous approaches that require the combination of both positional encoding and neural networks to learn meaningful representations, we show that both spherical harmonics and sinusoidal representation networks are competitive on their own but set state-of-the-art performances across tasks when combined. We provide source code at www.github.com/marccoru/locationencoder
Reflections from the Workshop on AI-Assisted Decision Making for Conservation
Jul 17, 2023



In this white paper, we synthesize key points made during presentations and discussions from the AI-Assisted Decision Making for Conservation workshop, hosted by the Center for Research on Computation and Society at Harvard University on October 20-21, 2022. We identify key open research questions in resource allocation, planning, and interventions for biodiversity conservation, highlighting conservation challenges that not only require AI solutions, but also require novel methodological advances. In addition to providing a summary of the workshop talks and discussions, we hope this document serves as a call-to-action to orient the expansion of algorithmic decision-making approaches to prioritize real-world conservation challenges, through collaborative efforts of ecologists, conservation decision-makers, and AI researchers.
Proceedings of the NeurIPS 2021 Workshop on Machine Learning for the Developing World: Global Challenges
Jan 10, 2023These are the proceedings of the 5th workshop on Machine Learning for the Developing World (ML4D), held as part of the Thirty-fifth Conference on Neural Information Processing Systems (NeurIPS) on December 14th, 2021.
GeoPointGAN: Synthetic Spatial Data with Local Label Differential Privacy
May 18, 2022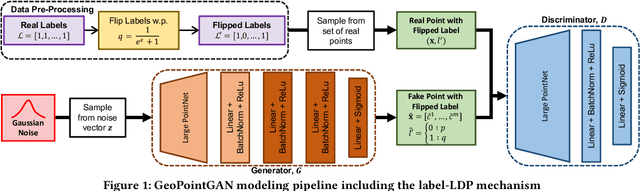
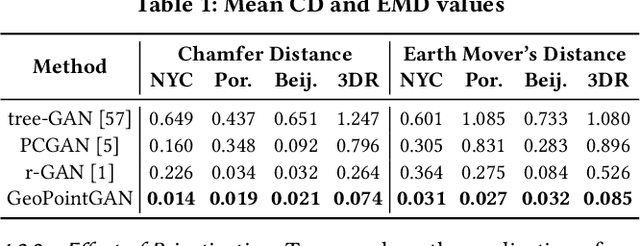
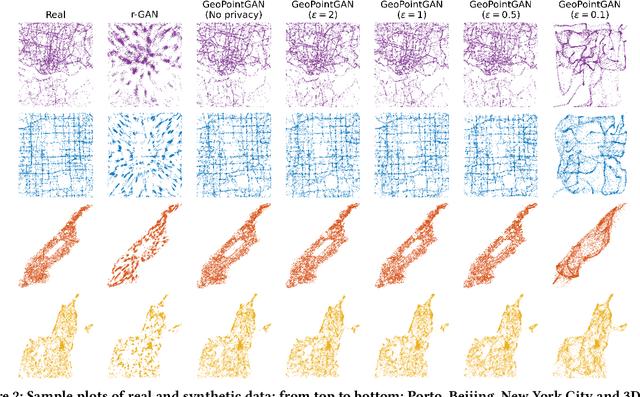
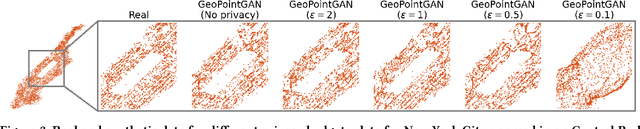
Synthetic data generation is a fundamental task for many data management and data science applications. Spatial data is of particular interest, and its sensitive nature often leads to privacy concerns. We introduce GeoPointGAN, a novel GAN-based solution for generating synthetic spatial point datasets with high utility and strong individual level privacy guarantees. GeoPointGAN's architecture includes a novel point transformation generator that learns to project randomly generated point co-ordinates into meaningful synthetic co-ordinates that capture both microscopic (e.g., junctions, squares) and macroscopic (e.g., parks, lakes) geographic features. We provide our privacy guarantees through label local differential privacy, which is more practical than traditional local differential privacy. We seamlessly integrate this level of privacy into GeoPointGAN by augmenting the discriminator to the point level and implementing a randomized response-based mechanism that flips the labels associated with the 'real' and 'fake' points used in training. Extensive experiments show that GeoPointGAN significantly outperforms recent solutions, improving by up to 10 times compared to the most competitive baseline. We also evaluate GeoPointGAN using range, hotspot, and facility location queries, which confirm the practical effectiveness of GeoPointGAN for privacy-preserving querying. The results illustrate that a strong level of privacy is achieved with little-to-no adverse utility cost, which we explain through the generalization and regularization effects that are realized by flipping the labels of the data during training.
ReforesTree: A Dataset for Estimating Tropical Forest Carbon Stock with Deep Learning and Aerial Imagery
Jan 26, 2022
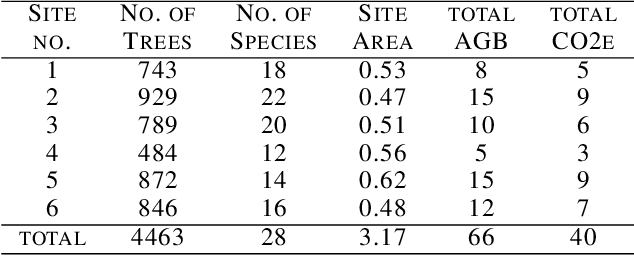
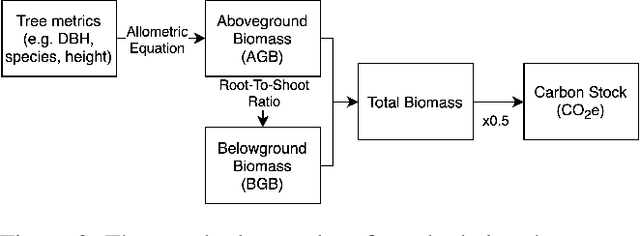
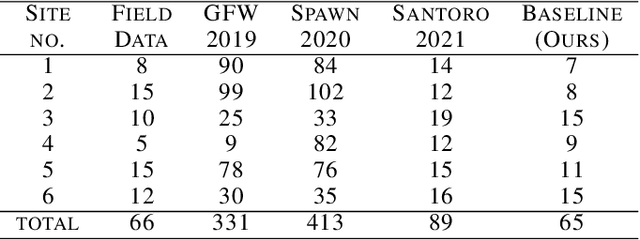
Forest biomass is a key influence for future climate, and the world urgently needs highly scalable financing schemes, such as carbon offsetting certifications, to protect and restore forests. Current manual forest carbon stock inventory methods of measuring single trees by hand are time, labour, and cost-intensive and have been shown to be subjective. They can lead to substantial overestimation of the carbon stock and ultimately distrust in forest financing. The potential for impact and scale of leveraging advancements in machine learning and remote sensing technologies is promising but needs to be of high quality in order to replace the current forest stock protocols for certifications. In this paper, we present ReforesTree, a benchmark dataset of forest carbon stock in six agro-forestry carbon offsetting sites in Ecuador. Furthermore, we show that a deep learning-based end-to-end model using individual tree detection from low cost RGB-only drone imagery is accurately estimating forest carbon stock within official carbon offsetting certification standards. Additionally, our baseline CNN model outperforms state-of-the-art satellite-based forest biomass and carbon stock estimates for this type of small-scale, tropical agro-forestry sites. We present this dataset to encourage machine learning research in this area to increase accountability and transparency of monitoring, verification and reporting (MVR) in carbon offsetting projects, as well as scaling global reforestation financing through accurate remote sensing.