 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe 1st PortraitCraft Challenge: A CVPR 2026 Workshop Competition on Portrait Composition Understanding and Generation
Jun 09, 2026This paper presents an overview of the inaugural PortraitCraft Challenge, held as one of the official competitions at CVPR 2026. The challenge focuses on portrait composition understanding and generation, aiming to advance AI research in portrait aesthetics analysis and controllable image synthesis. Unlike existing datasets and tasks that primarily focus on global aesthetic scoring, PortraitCraft introduces a unified evaluation framework comprising two complementary tracks. Track 1 requires models to perform structured portrait composition understanding, and Track 2 requires models to generate portrait images from structured composition descriptions under explicit compositional constraints. To support the challenge, we constructed and publicly released a large-scale portrait composition dataset consisting of approximately 50,000 curated real portrait images, providing multi-level supervision. This report describes the challenge setup, evaluation protocols, dataset composition, and final results, along with an analysis of the technical characteristics of the submitted solutions. The PortraitCraft Challenge provides a standardized and reproducible platform for research on portrait composition understanding and generation, and is expected to foster further progress in the fields of portrait aesthetics and controllable image generation.
Omne-R1: Learning to Reason with Memory for Multi-hop Question Answering
Aug 24, 2025This paper introduces Omne-R1, a novel approach designed to enhance multi-hop question answering capabilities on schema-free knowledge graphs by integrating advanced reasoning models. Our method employs a multi-stage training workflow, including two reinforcement learning phases and one supervised fine-tuning phase. We address the challenge of limited suitable knowledge graphs and QA data by constructing domain-independent knowledge graphs and auto-generating QA pairs. Experimental results show significant improvements in answering multi-hop questions, with notable performance gains on more complex 3+ hop questions. Our proposed training framework demonstrates strong generalization abilities across diverse knowledge domains.
ContentV: Efficient Training of Video Generation Models with Limited Compute
Jun 05, 2025Recent advances in video generation demand increasingly efficient training recipes to mitigate escalating computational costs. In this report, we present ContentV, an 8B-parameter text-to-video model that achieves state-of-the-art performance (85.14 on VBench) after training on 256 x 64GB Neural Processing Units (NPUs) for merely four weeks. ContentV generates diverse, high-quality videos across multiple resolutions and durations from text prompts, enabled by three key innovations: (1) A minimalist architecture that maximizes reuse of pre-trained image generation models for video generation; (2) A systematic multi-stage training strategy leveraging flow matching for enhanced efficiency; and (3) A cost-effective reinforcement learning with human feedback framework that improves generation quality without requiring additional human annotations. All the code and models are available at: https://contentv.github.io.
Towards Self-Improvement of Diffusion Models via Group Preference Optimization
May 16, 2025Aligning text-to-image (T2I) diffusion models with Direct Preference Optimization (DPO) has shown notable improvements in generation quality. However, applying DPO to T2I faces two challenges: the sensitivity of DPO to preference pairs and the labor-intensive process of collecting and annotating high-quality data. In this work, we demonstrate that preference pairs with marginal differences can degrade DPO performance. Since DPO relies exclusively on relative ranking while disregarding the absolute difference of pairs, it may misclassify losing samples as wins, or vice versa. We empirically show that extending the DPO from pairwise to groupwise and incorporating reward standardization for reweighting leads to performance gains without explicit data selection. Furthermore, we propose Group Preference Optimization (GPO), an effective self-improvement method that enhances performance by leveraging the model's own capabilities without requiring external data. Extensive experiments demonstrate that GPO is effective across various diffusion models and tasks. Specifically, combining with widely used computer vision models, such as YOLO and OCR, the GPO improves the accurate counting and text rendering capabilities of the Stable Diffusion 3.5 Medium by 20 percentage points. Notably, as a plug-and-play method, no extra overhead is introduced during inference.
CascadeV: An Implementation of Wurstchen Architecture for Video Generation
Jan 28, 2025Recently, with the tremendous success of diffusion models in the field of text-to-image (T2I) generation, increasing attention has been directed toward their potential in text-to-video (T2V) applications. However, the computational demands of diffusion models pose significant challenges, particularly in generating high-resolution videos with high frame rates. In this paper, we propose CascadeV, a cascaded latent diffusion model (LDM), that is capable of producing state-of-the-art 2K resolution videos. Experiments demonstrate that our cascaded model achieves a higher compression ratio, substantially reducing the computational challenges associated with high-quality video generation. We also implement a spatiotemporal alternating grid 3D attention mechanism, which effectively integrates spatial and temporal information, ensuring superior consistency across the generated video frames. Furthermore, our model can be cascaded with existing T2V models, theoretically enabling a 4$\times$ increase in resolution or frames per second without any fine-tuning. Our code is available at https://github.com/bytedance/CascadeV.
Drug-target affinity prediction method based on consistent expression of heterogeneous data
Nov 13, 2022



The first step in drug discovery is finding drug molecule moieties with medicinal activity against specific targets. Therefore, it is crucial to investigate the interaction between drug-target proteins and small chemical molecules. However, traditional experimental methods for discovering potential small drug molecules are labor-intensive and time-consuming. There is currently a lot of interest in building computational models to screen small drug molecules using drug molecule-related databases. In this paper, we propose a method for predicting drug-target binding affinity using deep learning models. This method uses a modified GRU and GNN to extract features from the drug-target protein sequences and the drug molecule map, respectively, to obtain their feature vectors. The combined vectors are used as vector representations of drug-target molecule pairs and then fed into a fully connected network to predict drug-target binding affinity. This proposed model demonstrates its accuracy and effectiveness in predicting drug-target binding affinity on the DAVIS and KIBA datasets.
Multi-Forgery Detection Challenge 2022: Push the Frontier of Unconstrained and Diverse Forgery Detection
Jul 27, 2022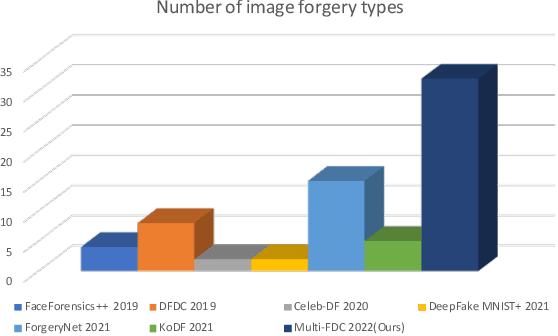

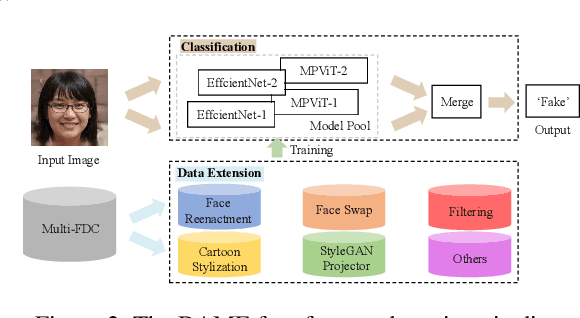
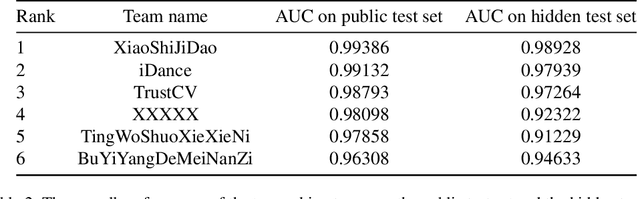
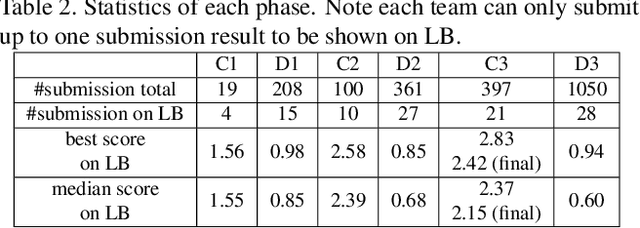
In this paper, we present the Multi-Forgery Detection Challenge held concurrently with the IEEE Computer Society Workshop on Biometrics at CVPR 2022. Our Multi-Forgery Detection Challenge aims to detect automatic image manipulations including but not limited to image editing, image synthesis, image generation, image photoshop, etc. Our challenge has attracted 674 teams from all over the world, with about 2000 valid result submission counts. We invited the Top 10 teams to present their solutions to the challenge, from which three teams are awarded prizes in the grand finale. In this paper, we present the solutions from the Top 3 teams, in order to boost the research work in the field of image forgery detection.
DFGC 2021: A DeepFake Game Competition
Jun 02, 2021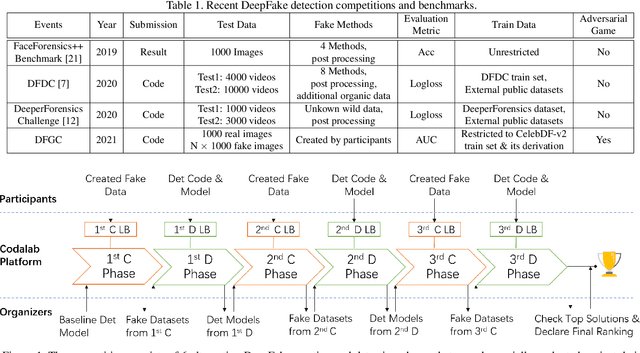
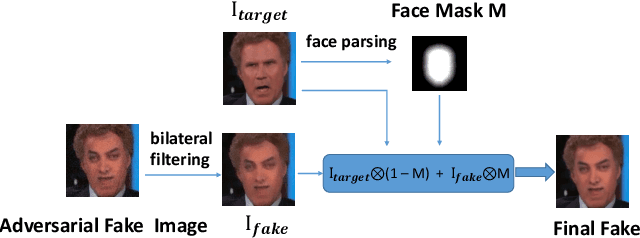
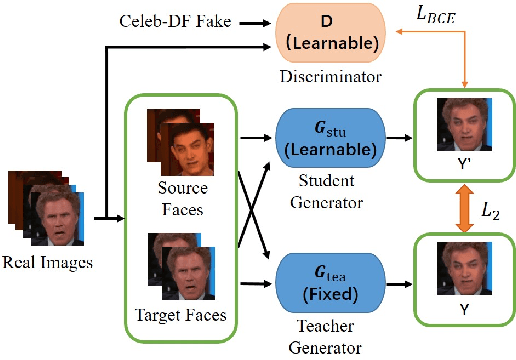
This paper presents a summary of the DFGC 2021 competition. DeepFake technology is developing fast, and realistic face-swaps are increasingly deceiving and hard to detect. At the same time, DeepFake detection methods are also improving. There is a two-party game between DeepFake creators and detectors. This competition provides a common platform for benchmarking the adversarial game between current state-of-the-art DeepFake creation and detection methods. In this paper, we present the organization, results and top solutions of this competition and also share our insights obtained during this event. We also release the DFGC-21 testing dataset collected from our participants to further benefit the research community.
Coherent optical communications using coherence-cloned Kerr soliton microcombs
Jan 01, 2021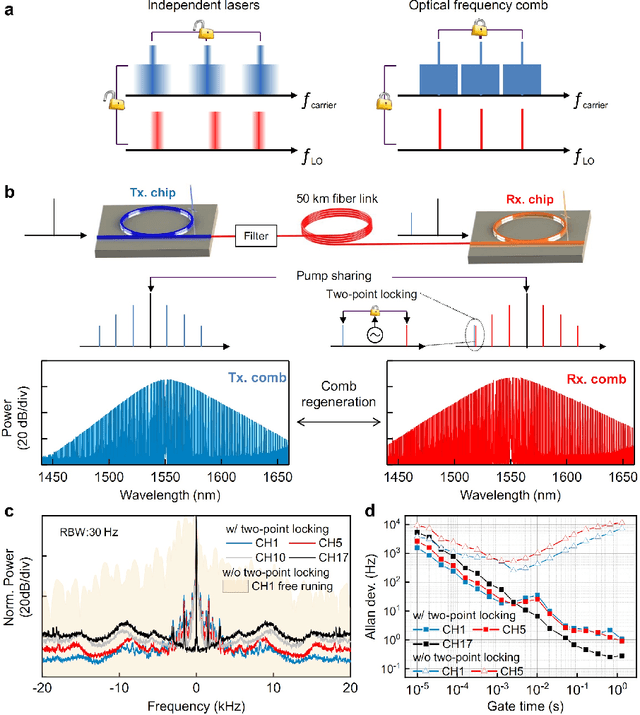
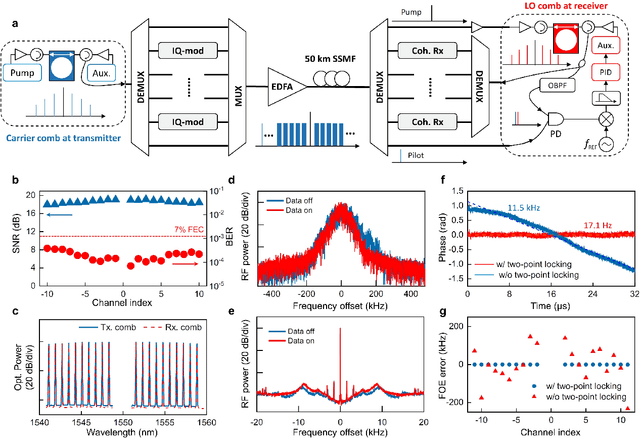
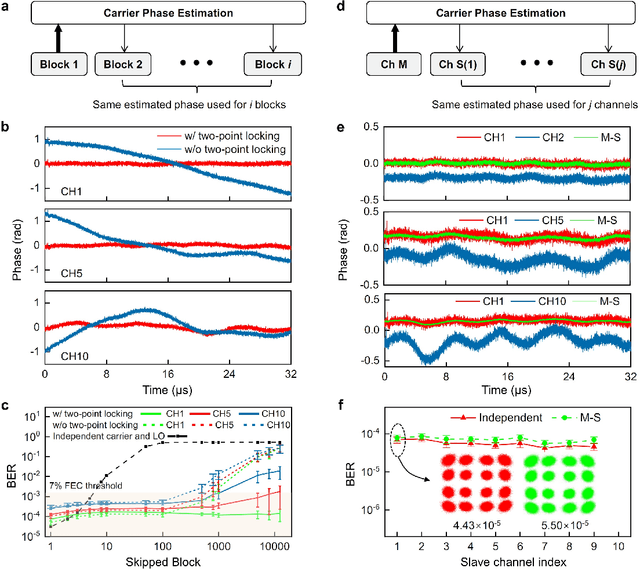
Dissipative Kerr soliton microcomb has been recognized as a promising on-chip multi-wavelength laser source for fiber optical communications, as its comb lines possess frequency and phase stability far beyond independent lasers. In the scenarios of coherent optical transmission and interconnect, a highly beneficial but rarely explored target is to re-generate a Kerr soliton microcomb at the receiver side as local oscillators that conserve the frequency and phase property of the incoming data carriers, so that to enable coherent detection with minimized optical and electrical compensations. Here, by using the techniques of pump laser conveying and two-point locking, we implement re-generation of a Kerr soliton microcomb that faithfully clones the frequency and phase coherence of another microcomb sent from 50 km away. Moreover, leveraging the coherence-cloned soliton microcombs as carriers and local oscillators, we demonstrate terabit coherent data interconnect, wherein traditional digital processes for frequency offset estimation is totally dispensed with, and carrier phase estimation is substantially simplified via slowed-down phase estimation rate per channel and joint phase estimation among multiple channels. Our work reveals that, in addition to providing a multitude of laser tones, regulating the frequency and phase of Kerr soliton microcombs among transmitters and receivers can significantly improve coherent communication in terms of performance, power consumption, and simplicity.