 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Training-Free Guess What Vision Language Model from Snippets to Open-Vocabulary Object Detection
Jan 21, 2026Open-Vocabulary Object Detection (OVOD) aims to develop the capability to detect anything. Although myriads of large-scale pre-training efforts have built versatile foundation models that exhibit impressive zero-shot capabilities to facilitate OVOD, the necessity of creating a universal understanding for any object cognition according to already pretrained foundation models is usually overlooked. Therefore, in this paper, a training-free Guess What Vision Language Model, called GW-VLM, is proposed to form a universal understanding paradigm based on our carefully designed Multi-Scale Visual Language Searching (MS-VLS) coupled with Contextual Concept Prompt (CCP) for OVOD. This approach can engage a pre-trained Vision Language Model (VLM) and a Large Language Model (LLM) in the game of "guess what". Wherein, MS-VLS leverages multi-scale visual-language soft-alignment for VLM to generate snippets from the results of class-agnostic object detection, while CCP can form the concept of flow referring to MS-VLS and then make LLM understand snippets for OVOD. Finally, the extensive experiments are carried out on natural and remote sensing datasets, including COCO val, Pascal VOC, DIOR, and NWPU-10, and the results indicate that our proposed GW-VLM can achieve superior OVOD performance compared to the-state-of-the-art methods without any training step.
OS-Symphony: A Holistic Framework for Robust and Generalist Computer-Using Agent
Jan 12, 2026While Vision-Language Models (VLMs) have significantly advanced Computer-Using Agents (CUAs), current frameworks struggle with robustness in long-horizon workflows and generalization in novel domains. These limitations stem from a lack of granular control over historical visual context curation and the absence of visual-aware tutorial retrieval. To bridge these gaps, we introduce OS-Symphony, a holistic framework that comprises an Orchestrator coordinating two key innovations for robust automation: (1) a Reflection-Memory Agent that utilizes milestone-driven long-term memory to enable trajectory-level self-correction, effectively mitigating visual context loss in long-horizon tasks; (2) Versatile Tool Agents featuring a Multimodal Searcher that adopts a SeeAct paradigm to navigate a browser-based sandbox to synthesize live, visually aligned tutorials, thereby resolving fidelity issues in unseen scenarios. Experimental results demonstrate that OS-Symphony delivers substantial performance gains across varying model scales, establishing new state-of-the-art results on three online benchmarks, notably achieving 65.84% on OSWorld.
OS-Oracle: A Comprehensive Framework for Cross-Platform GUI Critic Models
Dec 18, 2025



With VLM-powered computer-using agents (CUAs) becoming increasingly capable at graphical user interface (GUI) navigation and manipulation, reliable step-level decision-making has emerged as a key bottleneck for real-world deployment. In long-horizon workflows, errors accumulate quickly and irreversible actions can cause unintended consequences, motivating critic models that assess each action before execution. While critic models offer a promising solution, their effectiveness is hindered by the lack of diverse, high-quality GUI feedback data and public critic benchmarks for step-level evaluation in computer use. To bridge these gaps, we introduce OS-Oracle that makes three core contributions: (1) a scalable data pipeline for synthesizing cross-platform GUI critic data; (2) a two-stage training paradigm combining supervised fine-tuning (SFT) and consistency-preserving group relative policy optimization (CP-GRPO); (3) OS-Critic Bench, a holistic benchmark for evaluating critic model performance across Mobile, Web, and Desktop platforms. Leveraging this framework, we curate a high-quality dataset containing 310k critic samples. The resulting critic model, OS-Oracle-7B, achieves state-of-the-art performance among open-source VLMs on OS-Critic Bench, and surpasses proprietary models on the mobile domain. Furthermore, when serving as a pre-critic, OS-Oracle-7B improves the performance of native GUI agents such as UI-TARS-1.5-7B in OSWorld and AndroidWorld environments. The code is open-sourced at https://github.com/numbmelon/OS-Oracle.
Translating Informal Proofs into Formal Proofs Using a Chain of States
Dec 12, 2025



We address the problem of translating informal mathematical proofs expressed in natural language into formal proofs in Lean4 under a constrained computational budget. Our approach is grounded in two key insights. First, informal proofs tend to proceed via a sequence of logical transitions - often implications or equivalences - without explicitly specifying intermediate results or auxiliary lemmas. In contrast, formal systems like Lean require an explicit representation of each proof state and the tactics that connect them. Second, each informal reasoning step can be viewed as an abstract transformation between proof states, but identifying the corresponding formal tactics often requires nontrivial domain knowledge and precise control over proof context. To bridge this gap, we propose a two stage framework. Rather than generating formal tactics directly, we first extract a Chain of States (CoS), a sequence of intermediate formal proof states aligned with the logical structure of the informal argument. We then generate tactics to transition between adjacent states in the CoS, thereby constructing the full formal proof. This intermediate representation significantly reduces the complexity of tactic generation and improves alignment with informal reasoning patterns. We build dedicated datasets and benchmarks for training and evaluation, and introduce an interactive framework to support tactic generation from formal states. Empirical results show that our method substantially outperforms existing baselines, achieving higher proof success rates.
LiePrune: Lie Group and Quantum Geometric Dual Representation for One-Shot Structured Pruning of Quantum Neural Networks
Dec 10, 2025Quantum neural networks (QNNs) and parameterized quantum circuits (PQCs) are key building blocks for near-term quantum machine learning. However, their scalability is constrained by excessive parameters, barren plateaus, and hardware limitations. We propose LiePrune, the first mathematically grounded one-shot structured pruning framework for QNNs that leverages Lie group structure and quantum geometric information. Each gate is jointly represented in a Lie group--Lie algebra dual space and a quantum geometric feature space, enabling principled redundancy detection and aggressive compression. Experiments on quantum classification (MNIST, FashionMNIST), quantum generative modeling (Bars-and-Stripes), and quantum chemistry (LiH VQE) show that LiePrune achieves over $10\times$ compression with negligible or even improved task performance, while providing provable guarantees on redundancy detection, functional approximation, and computational complexity.
ScaleCUA: Scaling Open-Source Computer Use Agents with Cross-Platform Data
Sep 18, 2025



Vision-Language Models (VLMs) have enabled computer use agents (CUAs) that operate GUIs autonomously, showing great potential, yet progress is limited by the lack of large-scale, open-source computer use data and foundation models. In this work, we introduce ScaleCUA, a step toward scaling open-source CUAs. It offers a large-scale dataset spanning 6 operating systems and 3 task domains, built via a closed-loop pipeline uniting automated agents with human experts. Trained on this scaled-up data, ScaleCUA can operate seamlessly across platforms. Specifically, it delivers strong gains over baselines (+26.6 on WebArena-Lite-v2, +10.7 on ScreenSpot-Pro) and sets new state-of-the-art results (94.4% on MMBench-GUI L1-Hard, 60.6% on OSWorld-G, 47.4% on WebArena-Lite-v2). These findings underscore the power of data-driven scaling for general-purpose computer use agents. We will release data, models, and code to advance future research: https://github.com/OpenGVLab/ScaleCUA.
OmniEVA: Embodied Versatile Planner via Task-Adaptive 3D-Grounded and Embodiment-aware Reasoning
Sep 11, 2025Recent advances in multimodal large language models (MLLMs) have opened new opportunities for embodied intelligence, enabling multimodal understanding, reasoning, and interaction, as well as continuous spatial decision-making. Nevertheless, current MLLM-based embodied systems face two critical limitations. First, Geometric Adaptability Gap: models trained solely on 2D inputs or with hard-coded 3D geometry injection suffer from either insufficient spatial information or restricted 2D generalization, leading to poor adaptability across tasks with diverse spatial demands. Second, Embodiment Constraint Gap: prior work often neglects the physical constraints and capacities of real robots, resulting in task plans that are theoretically valid but practically infeasible.To address these gaps, we introduce OmniEVA -- an embodied versatile planner that enables advanced embodied reasoning and task planning through two pivotal innovations: (1) a Task-Adaptive 3D Grounding mechanism, which introduces a gated router to perform explicit selective regulation of 3D fusion based on contextual requirements, enabling context-aware 3D grounding for diverse embodied tasks. (2) an Embodiment-Aware Reasoning framework that jointly incorporates task goals and embodiment constraints into the reasoning loop, resulting in planning decisions that are both goal-directed and executable. Extensive experimental results demonstrate that OmniEVA not only achieves state-of-the-art general embodied reasoning performance, but also exhibits a strong ability across a wide range of downstream scenarios. Evaluations of a suite of proposed embodied benchmarks, including both primitive and composite tasks, confirm its robust and versatile planning capabilities. Project page: https://omnieva.github.io
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Aug 25, 2025



We introduce InternVL 3.5, a new family of open-source multimodal models that significantly advances versatility, reasoning capability, and inference efficiency along the InternVL series. A key innovation is the Cascade Reinforcement Learning (Cascade RL) framework, which enhances reasoning through a two-stage process: offline RL for stable convergence and online RL for refined alignment. This coarse-to-fine training strategy leads to substantial improvements on downstream reasoning tasks, e.g., MMMU and MathVista. To optimize efficiency, we propose a Visual Resolution Router (ViR) that dynamically adjusts the resolution of visual tokens without compromising performance. Coupled with ViR, our Decoupled Vision-Language Deployment (DvD) strategy separates the vision encoder and language model across different GPUs, effectively balancing computational load. These contributions collectively enable InternVL3.5 to achieve up to a +16.0\% gain in overall reasoning performance and a 4.05$\times$ inference speedup compared to its predecessor, i.e., InternVL3. In addition, InternVL3.5 supports novel capabilities such as GUI interaction and embodied agency. Notably, our largest model, i.e., InternVL3.5-241B-A28B, attains state-of-the-art results among open-source MLLMs across general multimodal, reasoning, text, and agentic tasks -- narrowing the performance gap with leading commercial models like GPT-5. All models and code are publicly released.
MoCHA: Advanced Vision-Language Reasoning with MoE Connector and Hierarchical Group Attention
Jul 30, 2025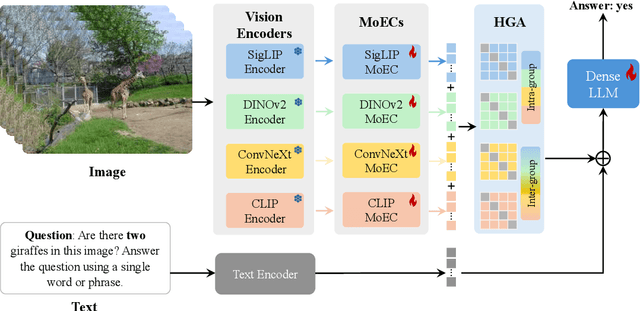
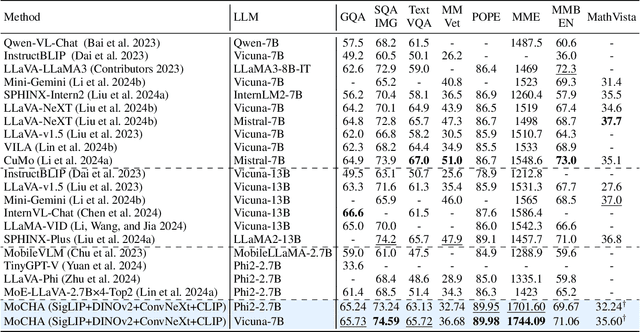
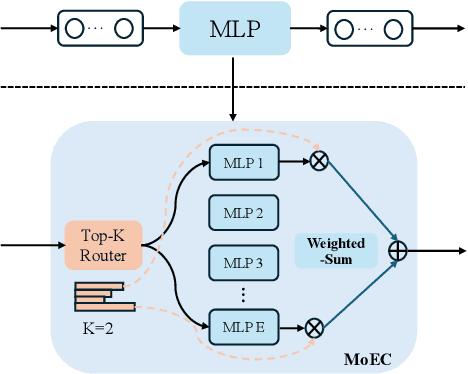
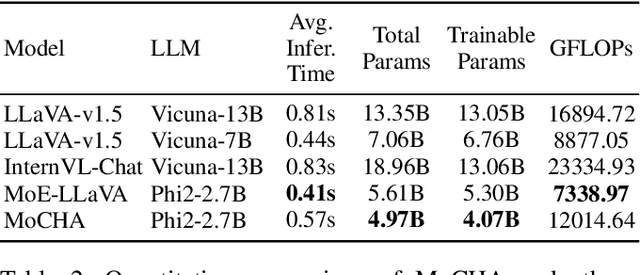
Vision large language models (VLLMs) are focusing primarily on handling complex and fine-grained visual information by incorporating advanced vision encoders and scaling up visual models. However, these approaches face high training and inference costs, as well as challenges in extracting visual details, effectively bridging across modalities. In this work, we propose a novel visual framework, MoCHA, to address these issues. Our framework integrates four vision backbones (i.e., CLIP, SigLIP, DINOv2 and ConvNeXt) to extract complementary visual features and is equipped with a sparse Mixture of Experts Connectors (MoECs) module to dynamically select experts tailored to different visual dimensions. To mitigate redundant or insufficient use of the visual information encoded by the MoECs module, we further design a Hierarchical Group Attention (HGA) with intra- and inter-group operations and an adaptive gating strategy for encoded visual features. We train MoCHA on two mainstream LLMs (e.g., Phi2-2.7B and Vicuna-7B) and evaluate their performance across various benchmarks. Notably, MoCHA outperforms state-of-the-art open-weight models on various tasks. For example, compared to CuMo (Mistral-7B), our MoCHA (Phi2-2.7B) presents outstanding abilities to mitigate hallucination by showing improvements of 3.25% in POPE and to follow visual instructions by raising 153 points on MME. Finally, ablation studies further confirm the effectiveness and robustness of the proposed MoECs and HGA in improving the overall performance of MoCHA.
Can GPT tell us why these images are synthesized? Empowering Multimodal Large Language Models for Forensics
Apr 16, 2025The rapid development of generative AI facilitates content creation and makes image manipulation easier and more difficult to detect. While multimodal Large Language Models (LLMs) have encoded rich world knowledge, they are not inherently tailored for combating AI-generated Content (AIGC) and struggle to comprehend local forgery details. In this work, we investigate the application of multimodal LLMs in forgery detection. We propose a framework capable of evaluating image authenticity, localizing tampered regions, providing evidence, and tracing generation methods based on semantic tampering clues. Our method demonstrates that the potential of LLMs in forgery analysis can be effectively unlocked through meticulous prompt engineering and the application of few-shot learning techniques. We conduct qualitative and quantitative experiments and show that GPT4V can achieve an accuracy of 92.1% in Autosplice and 86.3% in LaMa, which is competitive with state-of-the-art AIGC detection methods. We further discuss the limitations of multimodal LLMs in such tasks and propose potential improvements.