 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoCHA: Advanced Vision-Language Reasoning with MoE Connector and Hierarchical Group Attention
Jul 30, 2025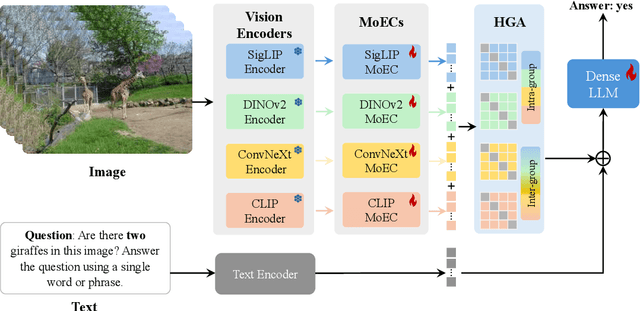
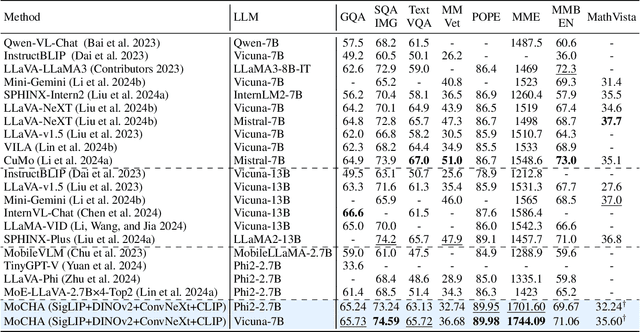
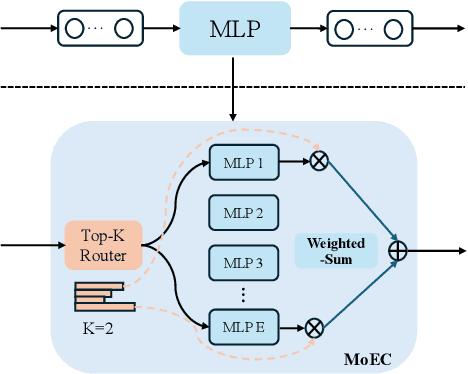
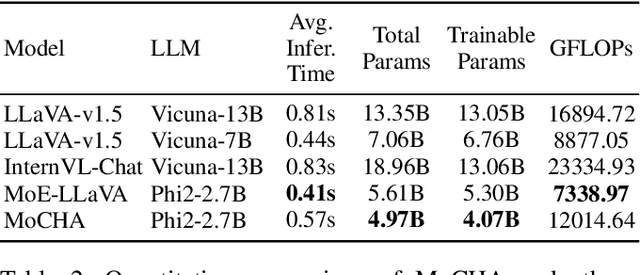
Vision large language models (VLLMs) are focusing primarily on handling complex and fine-grained visual information by incorporating advanced vision encoders and scaling up visual models. However, these approaches face high training and inference costs, as well as challenges in extracting visual details, effectively bridging across modalities. In this work, we propose a novel visual framework, MoCHA, to address these issues. Our framework integrates four vision backbones (i.e., CLIP, SigLIP, DINOv2 and ConvNeXt) to extract complementary visual features and is equipped with a sparse Mixture of Experts Connectors (MoECs) module to dynamically select experts tailored to different visual dimensions. To mitigate redundant or insufficient use of the visual information encoded by the MoECs module, we further design a Hierarchical Group Attention (HGA) with intra- and inter-group operations and an adaptive gating strategy for encoded visual features. We train MoCHA on two mainstream LLMs (e.g., Phi2-2.7B and Vicuna-7B) and evaluate their performance across various benchmarks. Notably, MoCHA outperforms state-of-the-art open-weight models on various tasks. For example, compared to CuMo (Mistral-7B), our MoCHA (Phi2-2.7B) presents outstanding abilities to mitigate hallucination by showing improvements of 3.25% in POPE and to follow visual instructions by raising 153 points on MME. Finally, ablation studies further confirm the effectiveness and robustness of the proposed MoECs and HGA in improving the overall performance of MoCHA.
Language Models Can See Better: Visual Contrastive Decoding For LLM Multimodal Reasoning
Feb 17, 2025



Although Large Language Models (LLMs) excel in reasoning and generation for language tasks, they are not specifically designed for multimodal challenges. Training Multimodal Large Language Models (MLLMs), however, is resource-intensive and constrained by various training limitations. In this paper, we propose the Modular-based Visual Contrastive Decoding (MVCD) framework to move this obstacle. Our framework leverages LLMs' In-Context Learning (ICL) capability and the proposed visual contrastive-example decoding (CED), specifically tailored for this framework, without requiring any additional training. By converting visual signals into text and focusing on contrastive output distributions during decoding, we can highlight the new information introduced by contextual examples, explore their connections, and avoid over-reliance on prior encoded knowledge. MVCD enhances LLMs' visual perception to make it see and reason over the input visuals. To demonstrate MVCD's effectiveness, we conduct experiments with four LLMs across five question answering datasets. Our results not only show consistent improvement in model accuracy but well explain the effective components inside our decoding strategy. Our code will be available at https://github.com/Pbhgit/MVCD.