 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Autoencoders for Few-shot Image Generation in Hyperbolic Space
Nov 27, 2024



Few-shot image generation aims to generate diverse and high-quality images for an unseen class given only a few examples in that class. However, existing methods often suffer from a trade-off between image quality and diversity while offering limited control over the attributes of newly generated images. In this work, we propose Hyperbolic Diffusion Autoencoders (HypDAE), a novel approach that operates in hyperbolic space to capture hierarchical relationships among images and texts from seen categories. By leveraging pre-trained foundation models, HypDAE generates diverse new images for unseen categories with exceptional quality by varying semantic codes or guided by textual instructions. Most importantly, the hyperbolic representation introduces an additional degree of control over semantic diversity through the adjustment of radii within the hyperbolic disk. Extensive experiments and visualizations demonstrate that HypDAE significantly outperforms prior methods by achieving a superior balance between quality and diversity with limited data and offers a highly controllable and interpretable generation process.
Extending Video Masked Autoencoders to 128 frames
Nov 20, 2024



Video understanding has witnessed significant progress with recent video foundation models demonstrating strong performance owing to self-supervised pre-training objectives; Masked Autoencoders (MAE) being the design of choice. Nevertheless, the majority of prior works that leverage MAE pre-training have focused on relatively short video representations (16 / 32 frames in length) largely due to hardware memory and compute limitations that scale poorly with video length due to the dense memory-intensive self-attention decoding. One natural strategy to address these challenges is to subsample tokens to reconstruct during decoding (or decoder masking). In this work, we propose an effective strategy for prioritizing tokens which allows training on longer video sequences (128 frames) and gets better performance than, more typical, random and uniform masking strategies. The core of our approach is an adaptive decoder masking strategy that prioritizes the most important tokens and uses quantized tokens as reconstruction objectives. Our adaptive strategy leverages a powerful MAGVIT-based tokenizer that jointly learns the tokens and their priority. We validate our design choices through exhaustive ablations and observe improved performance of the resulting long-video (128 frames) encoders over short-video (32 frames) counterparts. With our long-video masked autoencoder (LVMAE) strategy, we surpass state-of-the-art on Diving48 by 3.9 points and EPIC-Kitchens-100 verb classification by 2.5 points while relying on a simple core architecture and video-only pre-training (unlike some of the prior works that require millions of labeled video-text pairs or specialized encoders).
OmnixR: Evaluating Omni-modality Language Models on Reasoning across Modalities
Oct 16, 2024We introduce OmnixR, an evaluation suite designed to benchmark SoTA Omni-modality Language Models, such as GPT-4o and Gemini. Evaluating OLMs, which integrate multiple modalities such as text, vision, and audio, presents unique challenges. Particularly, the user message might often consist of multiple modalities, such that OLMs have to establish holistic understanding and reasoning across modalities to accomplish the task. Existing benchmarks are limited to single modality or dual-modality tasks, overlooking comprehensive multi-modal assessments of model reasoning. To address this, OmnixR offers two evaluation variants: (1)synthetic subset: a synthetic dataset generated automatically by translating text into multiple modalities--audio, images, video, and hybrids (Omnify). (2)realistic subset: a real-world dataset, manually curated and annotated by experts, for evaluating cross-modal reasoning in natural settings. OmnixR presents a unique evaluation towards assessing OLMs over a diverse mix of modalities, such as a question that involves video, audio, and text, providing a rigorous cross-modal reasoning testbed unlike any existing benchmarks. Our experiments find that all state-of-the-art OLMs struggle with OmnixR questions that require integrating information from multiple modalities to answer. Further analysis highlights differences in reasoning behavior, underscoring the challenges of omni-modal AI alignment.
$ε$-VAE: Denoising as Visual Decoding
Oct 05, 2024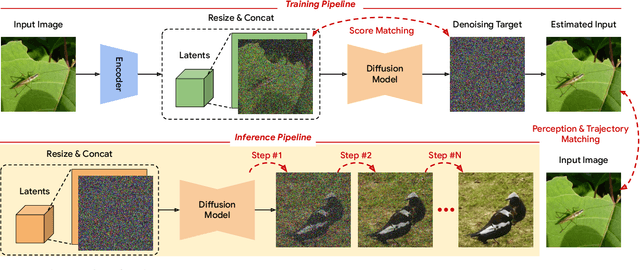
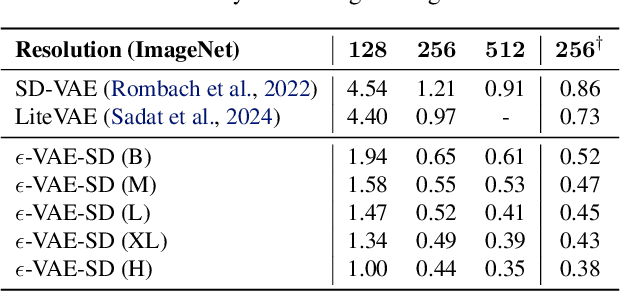
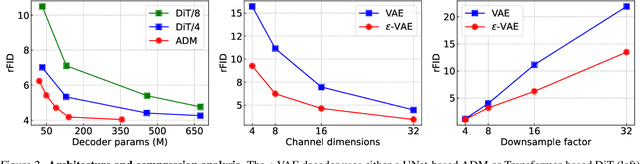
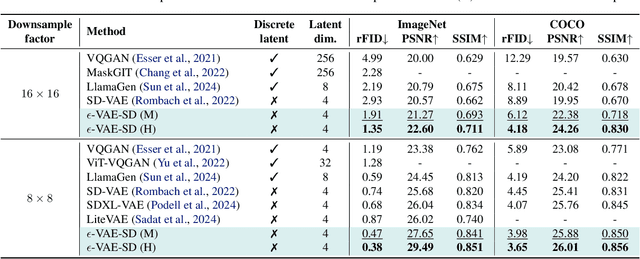
In generative modeling, tokenization simplifies complex data into compact, structured representations, creating a more efficient, learnable space. For high-dimensional visual data, it reduces redundancy and emphasizes key features for high-quality generation. Current visual tokenization methods rely on a traditional autoencoder framework, where the encoder compresses data into latent representations, and the decoder reconstructs the original input. In this work, we offer a new perspective by proposing denoising as decoding, shifting from single-step reconstruction to iterative refinement. Specifically, we replace the decoder with a diffusion process that iteratively refines noise to recover the original image, guided by the latents provided by the encoder. We evaluate our approach by assessing both reconstruction (rFID) and generation quality (FID), comparing it to state-of-the-art autoencoding approach. We hope this work offers new insights into integrating iterative generation and autoencoding for improved compression and generation.
SOAR: Self-supervision Optimized UAV Action Recognition with Efficient Object-Aware Pretraining
Sep 26, 2024



We introduce SOAR, a novel Self-supervised pretraining algorithm for aerial footage captured by Unmanned Aerial Vehicles (UAVs). We incorporate human object knowledge throughout the pretraining process to enhance UAV video pretraining efficiency and downstream action recognition performance. This is in contrast to prior works that primarily incorporate object information during the fine-tuning stage. Specifically, we first propose a novel object-aware masking strategy designed to retain the visibility of certain patches related to objects throughout the pretraining phase. Second, we introduce an object-aware loss function that utilizes object information to adjust the reconstruction loss, preventing bias towards less informative background patches. In practice, SOAR with a vanilla ViT backbone, outperforms best UAV action recognition models, recording a 9.7% and 21.4% boost in top-1 accuracy on the NEC-Drone and UAV-Human datasets, while delivering an inference speed of 18.7ms per video, making it 2x to 5x faster. Additionally, SOAR obtains comparable accuracy to prior self-supervised learning (SSL) methods while requiring 87.5% less pretraining time and 25% less memory usage
On Discrete Prompt Optimization for Diffusion Models
Jun 27, 2024



This paper introduces the first gradient-based framework for prompt optimization in text-to-image diffusion models. We formulate prompt engineering as a discrete optimization problem over the language space. Two major challenges arise in efficiently finding a solution to this problem: (1) Enormous Domain Space: Setting the domain to the entire language space poses significant difficulty to the optimization process. (2) Text Gradient: Efficiently computing the text gradient is challenging, as it requires backpropagating through the inference steps of the diffusion model and a non-differentiable embedding lookup table. Beyond the problem formulation, our main technical contributions lie in solving the above challenges. First, we design a family of dynamically generated compact subspaces comprised of only the most relevant words to user input, substantially restricting the domain space. Second, we introduce "Shortcut Text Gradient" -- an effective replacement for the text gradient that can be obtained with constant memory and runtime. Empirical evaluation on prompts collected from diverse sources (DiffusionDB, ChatGPT, COCO) suggests that our method can discover prompts that substantially improve (prompt enhancement) or destroy (adversarial attack) the faithfulness of images generated by the text-to-image diffusion model.
* ICML 2024. Code available at https://github.com/ruocwang/dpo-diffusion
Understanding the Impact of Negative Prompts: When and How Do They Take Effect?
Jun 05, 2024



The concept of negative prompts, emerging from conditional generation models like Stable Diffusion, allows users to specify what to exclude from the generated images.%, demonstrating significant practical efficacy. Despite the widespread use of negative prompts, their intrinsic mechanisms remain largely unexplored. This paper presents the first comprehensive study to uncover how and when negative prompts take effect. Our extensive empirical analysis identifies two primary behaviors of negative prompts. Delayed Effect: The impact of negative prompts is observed after positive prompts render corresponding content. Deletion Through Neutralization: Negative prompts delete concepts from the generated image through a mutual cancellation effect in latent space with positive prompts. These insights reveal significant potential real-world applications; for example, we demonstrate that negative prompts can facilitate object inpainting with minimal alterations to the background via a simple adaptive algorithm. We believe our findings will offer valuable insights for the community in capitalizing on the potential of negative prompts.
The Crystal Ball Hypothesis in diffusion models: Anticipating object positions from initial noise
Jun 04, 2024



Diffusion models have achieved remarkable success in text-to-image generation tasks; however, the role of initial noise has been rarely explored. In this study, we identify specific regions within the initial noise image, termed trigger patches, that play a key role for object generation in the resulting images. Notably, these patches are ``universal'' and can be generalized across various positions, seeds, and prompts. To be specific, extracting these patches from one noise and injecting them into another noise leads to object generation in targeted areas. We identify these patches by analyzing the dispersion of object bounding boxes across generated images, leading to the development of a posterior analysis technique. Furthermore, we create a dataset consisting of Gaussian noises labeled with bounding boxes corresponding to the objects appearing in the generated images and train a detector that identifies these patches from the initial noise. To explain the formation of these patches, we reveal that they are outliers in Gaussian noise, and follow distinct distributions through two-sample tests. Finally, we find the misalignment between prompts and the trigger patch patterns can result in unsuccessful image generations. The study proposes a reject-sampling strategy to obtain optimal noise, aiming to improve prompt adherence and positional diversity in image generation.
Automatic Jailbreaking of the Text-to-Image Generative AI Systems
May 28, 2024



Recent AI systems have shown extremely powerful performance, even surpassing human performance, on various tasks such as information retrieval, language generation, and image generation based on large language models (LLMs). At the same time, there are diverse safety risks that can cause the generation of malicious contents by circumventing the alignment in LLMs, which are often referred to as jailbreaking. However, most of the previous works only focused on the text-based jailbreaking in LLMs, and the jailbreaking of the text-to-image (T2I) generation system has been relatively overlooked. In this paper, we first evaluate the safety of the commercial T2I generation systems, such as ChatGPT, Copilot, and Gemini, on copyright infringement with naive prompts. From this empirical study, we find that Copilot and Gemini block only 12% and 17% of the attacks with naive prompts, respectively, while ChatGPT blocks 84% of them. Then, we further propose a stronger automated jailbreaking pipeline for T2I generation systems, which produces prompts that bypass their safety guards. Our automated jailbreaking framework leverages an LLM optimizer to generate prompts to maximize degree of violation from the generated images without any weight updates or gradient computation. Surprisingly, our simple yet effective approach successfully jailbreaks the ChatGPT with 11.0% block rate, making it generate copyrighted contents in 76% of the time. Finally, we explore various defense strategies, such as post-generation filtering and machine unlearning techniques, but found that they were inadequate, which suggests the necessity of stronger defense mechanisms.
Large-Scale Multi-Center CT and MRI Segmentation of Pancreas with Deep Learning
May 20, 2024



Automated volumetric segmentation of the pancreas on cross-sectional imaging is needed for diagnosis and follow-up of pancreatic diseases. While CT-based pancreatic segmentation is more established, MRI-based segmentation methods are understudied, largely due to a lack of publicly available datasets, benchmarking research efforts, and domain-specific deep learning methods. In this retrospective study, we collected a large dataset (767 scans from 499 participants) of T1-weighted (T1W) and T2-weighted (T2W) abdominal MRI series from five centers between March 2004 and November 2022. We also collected CT scans of 1,350 patients from publicly available sources for benchmarking purposes. We developed a new pancreas segmentation method, called PanSegNet, combining the strengths of nnUNet and a Transformer network with a new linear attention module enabling volumetric computation. We tested PanSegNet's accuracy in cross-modality (a total of 2,117 scans) and cross-center settings with Dice and Hausdorff distance (HD95) evaluation metrics. We used Cohen's kappa statistics for intra and inter-rater agreement evaluation and paired t-tests for volume and Dice comparisons, respectively. For segmentation accuracy, we achieved Dice coefficients of 88.3% (std: 7.2%, at case level) with CT, 85.0% (std: 7.9%) with T1W MRI, and 86.3% (std: 6.4%) with T2W MRI. There was a high correlation for pancreas volume prediction with R^2 of 0.91, 0.84, and 0.85 for CT, T1W, and T2W, respectively. We found moderate inter-observer (0.624 and 0.638 for T1W and T2W MRI, respectively) and high intra-observer agreement scores. All MRI data is made available at https://osf.io/kysnj/. Our source code is available at https://github.com/NUBagciLab/PaNSegNet.