 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL2GNet: Optimal Local-to-Global Representation of Anatomical Structures for Generalized Medical Image Segmentation
Feb 06, 2025



Continuous Latent Space (CLS) and Discrete Latent Space (DLS) models, like AttnUNet and VQUNet, have excelled in medical image segmentation. In contrast, Synergistic Continuous and Discrete Latent Space (CDLS) models show promise in handling fine and coarse-grained information. However, they struggle with modeling long-range dependencies. CLS or CDLS-based models, such as TransUNet or SynergyNet are adept at capturing long-range dependencies. Since they rely heavily on feature pooling or aggregation using self-attention, they may capture dependencies among redundant regions. This hinders comprehension of anatomical structure content, poses challenges in modeling intra-class and inter-class dependencies, increases false negatives and compromises generalization. Addressing these issues, we propose L2GNet, which learns global dependencies by relating discrete codes obtained from DLS using optimal transport and aligning codes on a trainable reference. L2GNet achieves discriminative on-the-fly representation learning without an additional weight matrix in self-attention models, making it computationally efficient for medical applications. Extensive experiments on multi-organ segmentation and cardiac datasets demonstrate L2GNet's superiority over state-of-the-art methods, including the CDLS method SynergyNet, offering an novel approach to enhance deep learning models' performance in medical image analysis.
Towards Synergistic Deep Learning Models for Volumetric Cirrhotic Liver Segmentation in MRIs
Aug 08, 2024



Liver cirrhosis, a leading cause of global mortality, requires precise segmentation of ROIs for effective disease monitoring and treatment planning. Existing segmentation models often fail to capture complex feature interactions and generalize across diverse datasets. To address these limitations, we propose a novel synergistic theory that leverages complementary latent spaces for enhanced feature interaction modeling. Our proposed architecture, nnSynergyNet3D integrates continuous and discrete latent spaces for 3D volumes and features auto-configured training. This approach captures both fine-grained and coarse features, enabling effective modeling of intricate feature interactions. We empirically validated nnSynergyNet3D on a private dataset of 628 high-resolution T1 abdominal MRI scans from 339 patients. Our model outperformed the baseline nnUNet3D by approximately 2%. Additionally, zero-shot testing on healthy liver CT scans from the public LiTS dataset demonstrated superior cross-modal generalization capabilities. These results highlight the potential of synergistic latent space models to improve segmentation accuracy and robustness, thereby enhancing clinical workflows by ensuring consistency across CT and MRI modalities.
Large-Scale Multi-Center CT and MRI Segmentation of Pancreas with Deep Learning
May 20, 2024



Automated volumetric segmentation of the pancreas on cross-sectional imaging is needed for diagnosis and follow-up of pancreatic diseases. While CT-based pancreatic segmentation is more established, MRI-based segmentation methods are understudied, largely due to a lack of publicly available datasets, benchmarking research efforts, and domain-specific deep learning methods. In this retrospective study, we collected a large dataset (767 scans from 499 participants) of T1-weighted (T1W) and T2-weighted (T2W) abdominal MRI series from five centers between March 2004 and November 2022. We also collected CT scans of 1,350 patients from publicly available sources for benchmarking purposes. We developed a new pancreas segmentation method, called PanSegNet, combining the strengths of nnUNet and a Transformer network with a new linear attention module enabling volumetric computation. We tested PanSegNet's accuracy in cross-modality (a total of 2,117 scans) and cross-center settings with Dice and Hausdorff distance (HD95) evaluation metrics. We used Cohen's kappa statistics for intra and inter-rater agreement evaluation and paired t-tests for volume and Dice comparisons, respectively. For segmentation accuracy, we achieved Dice coefficients of 88.3% (std: 7.2%, at case level) with CT, 85.0% (std: 7.9%) with T1W MRI, and 86.3% (std: 6.4%) with T2W MRI. There was a high correlation for pancreas volume prediction with R^2 of 0.91, 0.84, and 0.85 for CT, T1W, and T2W, respectively. We found moderate inter-observer (0.624 and 0.638 for T1W and T2W MRI, respectively) and high intra-observer agreement scores. All MRI data is made available at https://osf.io/kysnj/. Our source code is available at https://github.com/NUBagciLab/PaNSegNet.
PAM-UNet: Shifting Attention on Region of Interest in Medical Images
May 02, 2024



Computer-aided segmentation methods can assist medical personnel in improving diagnostic outcomes. While recent advancements like UNet and its variants have shown promise, they face a critical challenge: balancing accuracy with computational efficiency. Shallow encoder architectures in UNets often struggle to capture crucial spatial features, leading in inaccurate and sparse segmentation. To address this limitation, we propose a novel \underline{P}rogressive \underline{A}ttention based \underline{M}obile \underline{UNet} (\underline{PAM-UNet}) architecture. The inverted residual (IR) blocks in PAM-UNet help maintain a lightweight framework, while layerwise \textit{Progressive Luong Attention} ($\mathcal{PLA}$) promotes precise segmentation by directing attention toward regions of interest during synthesis. Our approach prioritizes both accuracy and speed, achieving a commendable balance with a mean IoU of 74.65 and a dice score of 82.87, while requiring only 1.32 floating-point operations per second (FLOPS) on the Liver Tumor Segmentation Benchmark (LiTS) 2017 dataset. These results highlight the importance of developing efficient segmentation models to accelerate the adoption of AI in clinical practice.
OPTiML: Dense Semantic Invariance Using Optimal Transport for Self-Supervised Medical Image Representation
Apr 18, 2024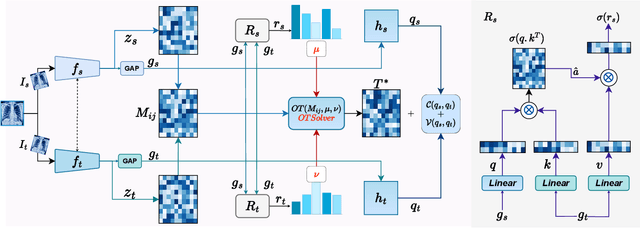

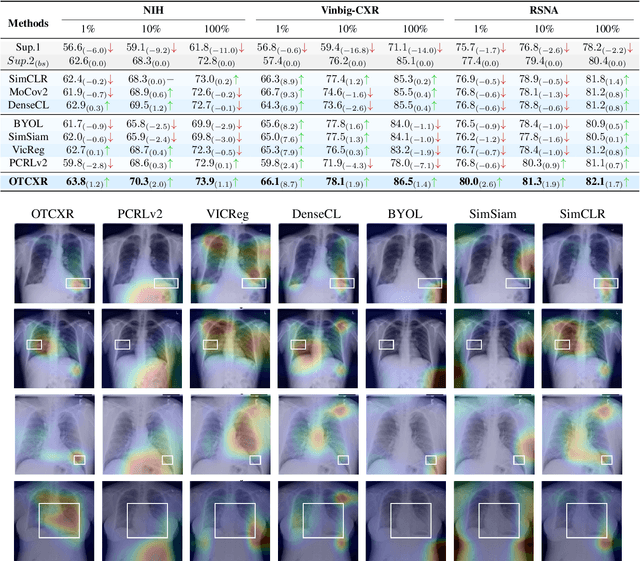
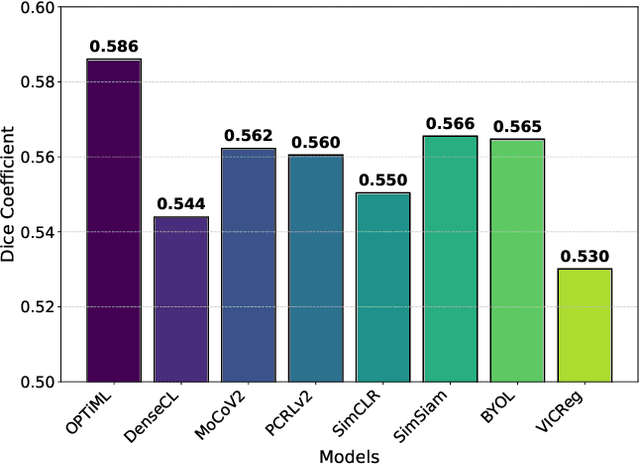
Self-supervised learning (SSL) has emerged as a promising technique for medical image analysis due to its ability to learn without annotations. However, despite the promising potential, conventional SSL methods encounter limitations, including challenges in achieving semantic alignment and capturing subtle details. This leads to suboptimal representations, which fail to accurately capture the underlying anatomical structures and pathological details. In response to these constraints, we introduce a novel SSL framework OPTiML, employing optimal transport (OT), to capture the dense semantic invariance and fine-grained details, thereby enhancing the overall effectiveness of SSL in medical image representation learning. The core idea is to integrate OT with a cross-viewpoint semantics infusion module (CV-SIM), which effectively captures complex, fine-grained details inherent in medical images across different viewpoints. In addition to the CV-SIM module, OPTiML imposes the variance and covariance regularizations within OT framework to force the model focus on clinically relevant information while discarding less informative features. Through these, the proposed framework demonstrates its capacity to learn semantically rich representations that can be applied to various medical imaging tasks. To validate its effectiveness, we conduct experimental studies on three publicly available datasets from chest X-ray modality. Our empirical results reveal OPTiML's superiority over state-of-the-art methods across all evaluated tasks.
MLVICX: Multi-Level Variance-Covariance Exploration for Chest X-ray Self-Supervised Representation Learning
Mar 18, 2024Self-supervised learning (SSL) is potentially useful in reducing the need for manual annotation and making deep learning models accessible for medical image analysis tasks. By leveraging the representations learned from unlabeled data, self-supervised models perform well on tasks that require little to no fine-tuning. However, for medical images, like chest X-rays, which are characterized by complex anatomical structures and diverse clinical conditions, there arises a need for representation learning techniques that can encode fine-grained details while preserving the broader contextual information. In this context, we introduce MLVICX (Multi-Level Variance-Covariance Exploration for Chest X-ray Self-Supervised Representation Learning), an approach to capture rich representations in the form of embeddings from chest X-ray images. Central to our approach is a novel multi-level variance and covariance exploration strategy that empowers the model to detect diagnostically meaningful patterns while reducing redundancy effectively. By enhancing the variance and covariance of the learned embeddings, MLVICX promotes the retention of critical medical insights by adapting both global and local contextual details. We demonstrate the performance of MLVICX in advancing self-supervised chest X-ray representation learning through comprehensive experiments. The performance enhancements we observe across various downstream tasks highlight the significance of the proposed approach in enhancing the utility of chest X-ray embeddings for precision medical diagnosis and comprehensive image analysis. For pertaining, we used the NIH-Chest X-ray dataset, while for downstream tasks, we utilized NIH-Chest X-ray, Vinbig-CXR, RSNA pneumonia, and SIIM-ACR Pneumothorax datasets. Overall, we observe more than 3% performance gains over SOTA SSL approaches in various downstream tasks.
Harmonized Spatial and Spectral Learning for Robust and Generalized Medical Image Segmentation
Jan 18, 2024



Deep learning has demonstrated remarkable achievements in medical image segmentation. However, prevailing deep learning models struggle with poor generalization due to (i) intra-class variations, where the same class appears differently in different samples, and (ii) inter-class independence, resulting in difficulties capturing intricate relationships between distinct objects, leading to higher false negative cases. This paper presents a novel approach that synergies spatial and spectral representations to enhance domain-generalized medical image segmentation. We introduce the innovative Spectral Correlation Coefficient objective to improve the model's capacity to capture middle-order features and contextual long-range dependencies. This objective complements traditional spatial objectives by incorporating valuable spectral information. Extensive experiments reveal that optimizing this objective with existing architectures like UNet and TransUNet significantly enhances generalization, interpretability, and noise robustness, producing more confident predictions. For instance, in cardiac segmentation, we observe a 0.81 pp and 1.63 pp (pp = percentage point) improvement in DSC over UNet and TransUNet, respectively. Our interpretability study demonstrates that, in most tasks, objectives optimized with UNet outperform even TransUNet by introducing global contextual information alongside local details. These findings underscore the versatility and effectiveness of our proposed method across diverse imaging modalities and medical domains.
Rethinking Intermediate Layers design in Knowledge Distillation for Kidney and Liver Tumor Segmentation
Nov 28, 2023



Knowledge distillation(KD) has demonstrated remarkable success across various domains, but its application to medical imaging tasks, such as kidney and liver tumor segmentation, has encountered challenges. Many existing KD methods are not specifically tailored for these tasks. Moreover, prevalent KD methods often lack a careful consideration of what and from where to distill knowledge from the teacher to the student. This oversight may lead to issues like the accumulation of training bias within shallower student layers, potentially compromising the effectiveness of KD. To address these challenges, we propose Hierarchical Layer-selective Feedback Distillation (HLFD). HLFD strategically distills knowledge from a combination of middle layers to earlier layers and transfers final layer knowledge to intermediate layers at both the feature and pixel levels. This design allows the model to learn higher-quality representations from earlier layers, resulting in a robust and compact student model. Extensive quantitative evaluations reveal that HLFD outperforms existing methods by a significant margin. For example, in the kidney segmentation task, HLFD surpasses the student model (without KD) by over 10pp, significantly improving its focus on tumor-specific features. From a qualitative standpoint, the student model trained using HLFD excels at suppressing irrelevant information and can focus sharply on tumor-specific details, which opens a new pathway for more efficient and accurate diagnostic tools.
SynergyNet: Bridging the Gap between Discrete and Continuous Representations for Precise Medical Image Segmentation
Oct 26, 2023In recent years, continuous latent space (CLS) and discrete latent space (DLS) deep learning models have been proposed for medical image analysis for improved performance. However, these models encounter distinct challenges. CLS models capture intricate details but often lack interpretability in terms of structural representation and robustness due to their emphasis on low-level features. Conversely, DLS models offer interpretability, robustness, and the ability to capture coarse-grained information thanks to their structured latent space. However, DLS models have limited efficacy in capturing fine-grained details. To address the limitations of both DLS and CLS models, we propose SynergyNet, a novel bottleneck architecture designed to enhance existing encoder-decoder segmentation frameworks. SynergyNet seamlessly integrates discrete and continuous representations to harness complementary information and successfully preserves both fine and coarse-grained details in the learned representations. Our extensive experiment on multi-organ segmentation and cardiac datasets demonstrates that SynergyNet outperforms other state of the art methods, including TransUNet: dice scores improving by 2.16%, and Hausdorff scores improving by 11.13%, respectively. When evaluating skin lesion and brain tumor segmentation datasets, we observe a remarkable improvement of 1.71% in Intersection-over Union scores for skin lesion segmentation and of 8.58% for brain tumor segmentation. Our innovative approach paves the way for enhancing the overall performance and capabilities of deep learning models in the critical domain of medical image analysis.
Large Scale Time-Series Representation Learning via Simultaneous Low and High Frequency Feature Bootstrapping
Apr 24, 2022


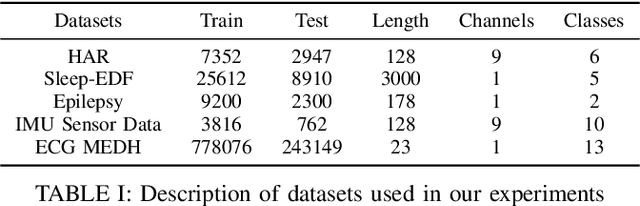
Learning representation from unlabeled time series data is a challenging problem. Most existing self-supervised and unsupervised approaches in the time-series domain do not capture low and high-frequency features at the same time. Further, some of these methods employ large scale models like transformers or rely on computationally expensive techniques such as contrastive learning. To tackle these problems, we propose a non-contrastive self-supervised learning approach efficiently captures low and high-frequency time-varying features in a cost-effective manner. Our method takes raw time series data as input and creates two different augmented views for two branches of the model, by randomly sampling the augmentations from same family. Following the terminology of BYOL, the two branches are called online and target network which allows bootstrapping of the latent representation. In contrast to BYOL, where a backbone encoder is followed by multilayer perceptron (MLP) heads, the proposed model contains additional temporal convolutional network (TCN) heads. As the augmented views are passed through large kernel convolution blocks of the encoder, the subsequent combination of MLP and TCN enables an effective representation of low as well as high-frequency time-varying features due to the varying receptive fields. The two modules (MLP and TCN) act in a complementary manner. We train an online network where each module learns to predict the outcome of the respective module of target network branch. To demonstrate the robustness of our model we performed extensive experiments and ablation studies on five real-world time-series datasets. Our method achieved state-of-art performance on all five real-world datasets.