 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Generalization of End-to-End Driving through Procedural Generation
Dec 26, 2020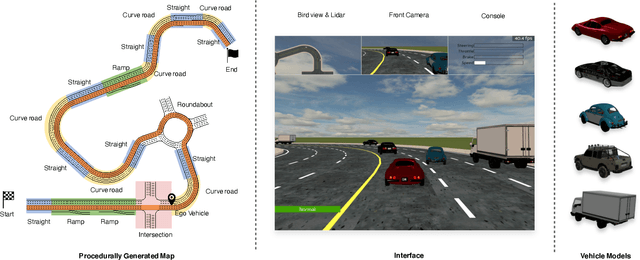

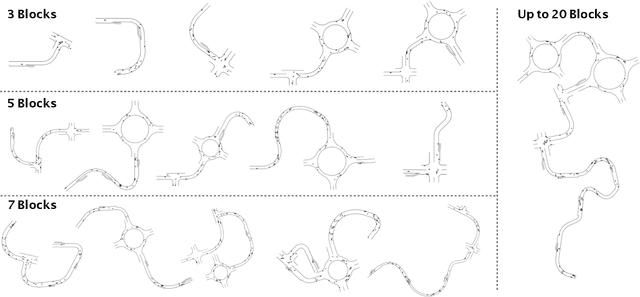
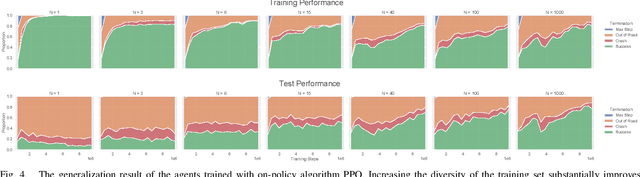
Recently there is a growing interest in the end-to-end training of autonomous driving where the entire driving pipeline from perception to control is modeled as a neural network and jointly optimized. The end-to-end driving is usually first developed and validated in simulators. However, most of the existing driving simulators only contain a fixed set of maps and a limited number of configurations. As a result the deep models are prone to overfitting training scenarios. Furthermore it is difficult to assess how well the trained models generalize to unseen scenarios. To better evaluate and improve the generalization of end-to-end driving, we introduce an open-ended and highly configurable driving simulator called PGDrive. PGDrive first defines multiple basic road blocks such as ramp, fork, and roundabout with configurable settings. Then a range of diverse maps can be assembled from those blocks with procedural generation, which are further turned into interactive environments. The experiments show that the driving agent trained by reinforcement learning on a small fixed set of maps generalizes poorly to unseen maps. We further validate that training with the increasing number of procedurally generated maps significantly improves the generalization of the agent across scenarios of different traffic densities and map structures. Code is available at: https://decisionforce.github.io/pgdrive
Positional Encoding as Spatial Inductive Bias in GANs
Dec 09, 2020
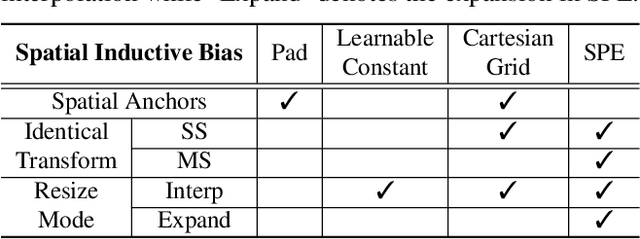
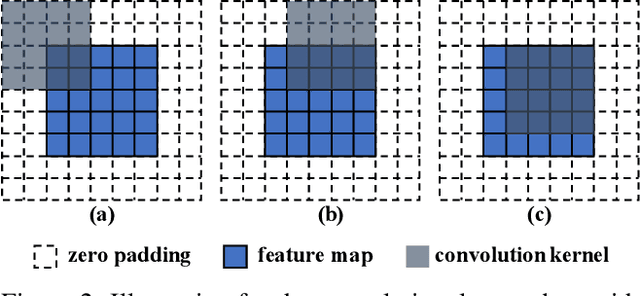
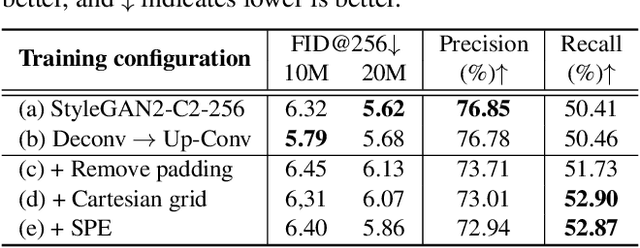
SinGAN shows impressive capability in learning internal patch distribution despite its limited effective receptive field. We are interested in knowing how such a translation-invariant convolutional generator could capture the global structure with just a spatially i.i.d. input. In this work, taking SinGAN and StyleGAN2 as examples, we show that such capability, to a large extent, is brought by the implicit positional encoding when using zero padding in the generators. Such positional encoding is indispensable for generating images with high fidelity. The same phenomenon is observed in other generative architectures such as DCGAN and PGGAN. We further show that zero padding leads to an unbalanced spatial bias with a vague relation between locations. To offer a better spatial inductive bias, we investigate alternative positional encodings and analyze their effects. Based on a more flexible positional encoding explicitly, we propose a new multi-scale training strategy and demonstrate its effectiveness in the state-of-the-art unconditional generator StyleGAN2. Besides, the explicit spatial inductive bias substantially improve SinGAN for more versatile image manipulation.
Improving the Fairness of Deep Generative Models without Retraining
Dec 09, 2020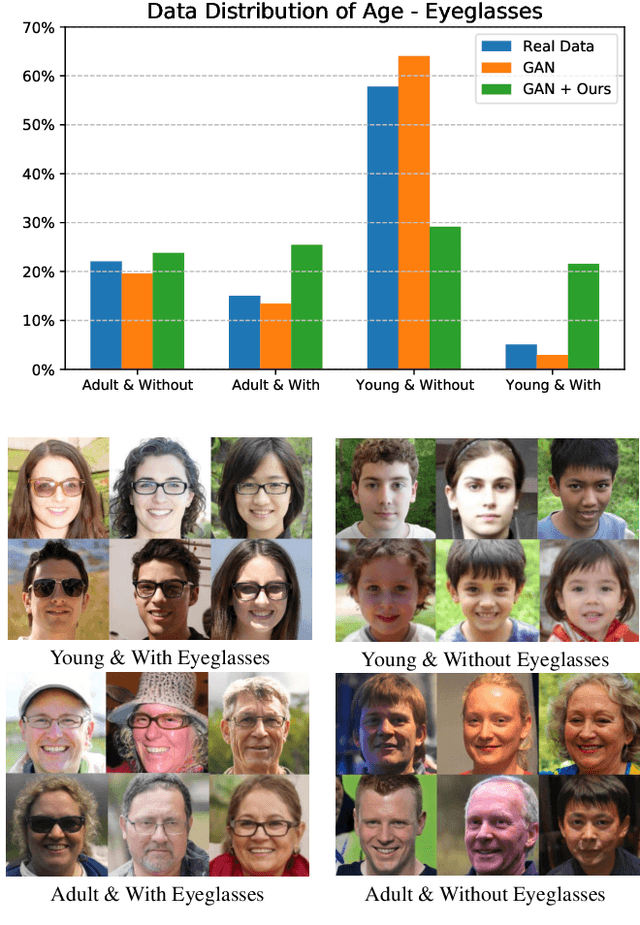
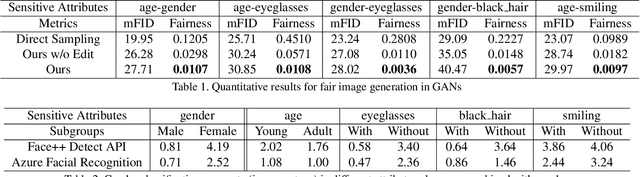
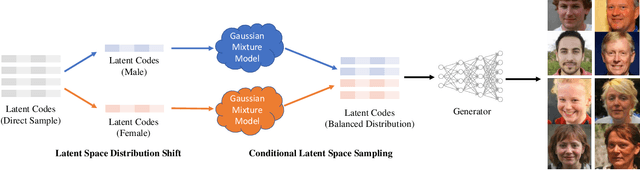

Generative Adversarial Networks (GANs) have recently advanced face synthesis by learning the underlying distribution of observed data. However, it will lead to a biased image generation due to the imbalanced training data or the mode collapse issue. Prior work typically addresses the fairness of data generation by balancing the training data that correspond to the concerned attributes. In this work, we propose a simple yet effective method to improve the fairness of image generation for a pre-trained GAN model without retraining. We utilize the recent work of GAN interpretation to identify the directions in the latent space corresponding to the target attributes, and then manipulate a set of latent codes with balanced attribute distributions over output images. We learn a Gaussian Mixture Model (GMM) to fit a distribution of the latent code set, which supports the sampling of latent codes for producing images with a more fair attribute distribution. Experiments show that our method can substantially improve the fairness of image generation, outperforming potential baselines both quantitatively and qualitatively. The images generated from our method are further applied to reveal and quantify the biases in commercial face classifiers and face super-resolution model.
Texture Memory-Augmented Deep Patch-Based Image Inpainting
Sep 28, 2020



Patch-based methods and deep networks have been employed to tackle image inpainting problem, with their own strengths and weaknesses. Patch-based methods are capable of restoring a missing region with high-quality texture through searching nearest neighbor patches from the unmasked regions. However, these methods bring problematic contents when recovering large missing regions. Deep networks, on the other hand, show promising results in completing large regions. Nonetheless, the results often lack faithful and sharp details that resemble the surrounding area. By bringing together the best of both paradigms, we propose a new deep inpainting framework where texture generation is guided by a texture memory of patch samples extracted from unmasked regions. The framework has a novel design that allows texture memory retrieval to be trained end-to-end with the deep inpainting network. In addition, we introduce a patch distribution loss to encourage high-quality patch synthesis. The proposed method shows superior performance both qualitatively and quantitatively on three challenging image benchmarks, i.e., Places, CelebA-HQ, and Paris Street-View datasets.
Understanding the Role of Individual Units in a Deep Neural Network
Sep 12, 2020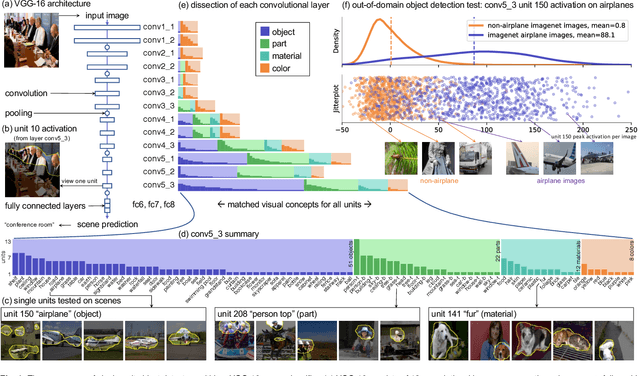
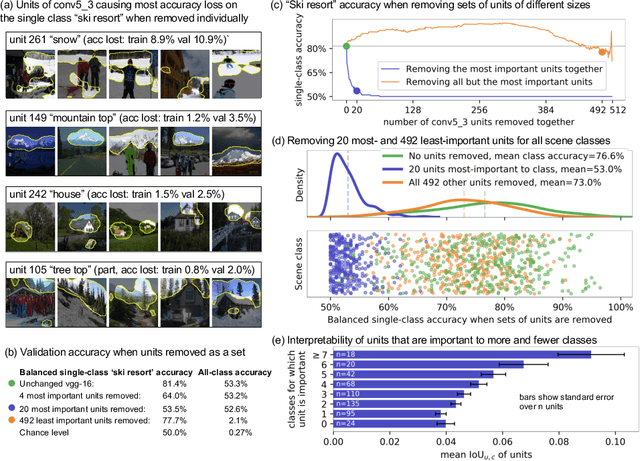
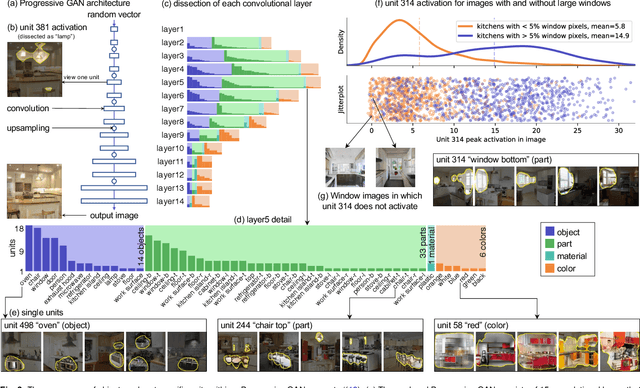
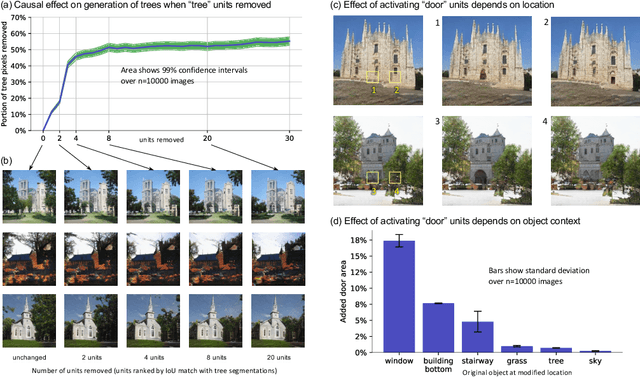
Deep neural networks excel at finding hierarchical representations that solve complex tasks over large data sets. How can we humans understand these learned representations? In this work, we present network dissection, an analytic framework to systematically identify the semantics of individual hidden units within image classification and image generation networks. First, we analyze a convolutional neural network (CNN) trained on scene classification and discover units that match a diverse set of object concepts. We find evidence that the network has learned many object classes that play crucial roles in classifying scene classes. Second, we use a similar analytic method to analyze a generative adversarial network (GAN) model trained to generate scenes. By analyzing changes made when small sets of units are activated or deactivated, we find that objects can be added and removed from the output scenes while adapting to the context. Finally, we apply our analytic framework to understanding adversarial attacks and to semantic image editing.
A Unified Framework for Shot Type Classification Based on Subject Centric Lens
Aug 08, 2020

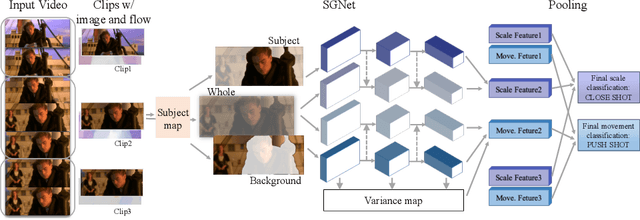
Shots are key narrative elements of various videos, e.g. movies, TV series, and user-generated videos that are thriving over the Internet. The types of shots greatly influence how the underlying ideas, emotions, and messages are expressed. The technique to analyze shot types is important to the understanding of videos, which has seen increasing demand in real-world applications in this era. Classifying shot type is challenging due to the additional information required beyond the video content, such as the spatial composition of a frame and camera movement. To address these issues, we propose a learning framework Subject Guidance Network (SGNet) for shot type recognition. SGNet separates the subject and background of a shot into two streams, serving as separate guidance maps for scale and movement type classification respectively. To facilitate shot type analysis and model evaluations, we build a large-scale dataset MovieShots, which contains 46K shots from 7K movie trailers with annotations of their scale and movement types. Experiments show that our framework is able to recognize these two attributes of shot accurately, outperforming all the previous methods.
Generative Hierarchical Features from Synthesizing Images
Jul 20, 2020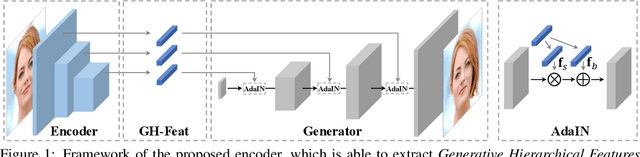
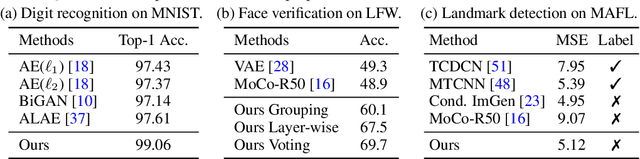
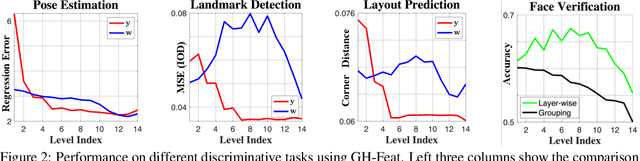
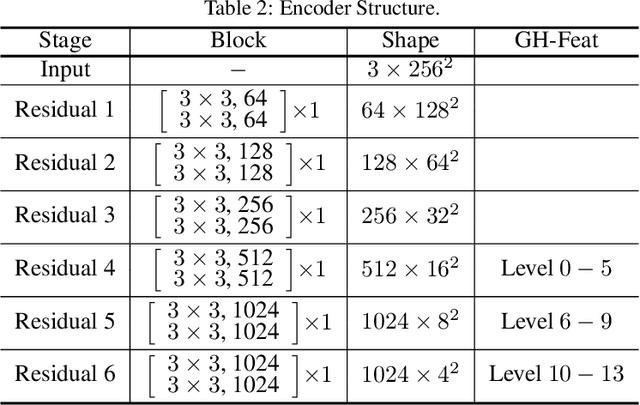
Generative Adversarial Networks (GANs) have recently advanced image synthesis by learning the underlying distribution of observed data in an unsupervised manner. However, how the features trained from solving the task of image synthesis are applicable to visual tasks remains seldom explored. In this work, we show that learning to synthesize images is able to bring remarkable hierarchical visual features that are generalizable across a wide range of visual tasks. Specifically, we consider the pre-trained StyleGAN generator as a learned loss function and utilize its layer-wise disentangled representation to train a novel hierarchical encoder. As a result, the visual feature produced by our encoder, termed as Generative Hierarchical Feature (GH-Feat), has compelling discriminative and disentangled properties, facilitating a range of both discriminative and generative tasks. Extensive experiments on face verification, landmark detection, layout prediction, transfer learning, style mixing, and image editing show the appealing performance of the GH-Feat learned from synthesizing images, outperforming existing unsupervised feature learning methods.
Closed-Form Factorization of Latent Semantics in GANs
Jul 15, 2020
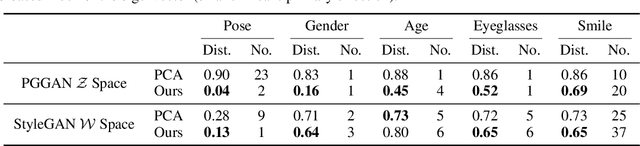


A rich set of semantic attributes has been shown to emerge in the latent space of the Generative Adversarial Networks (GANs) trained for synthesizing images. In order to identify such latent semantics for image manipulation, previous methods annotate a collection of synthesized samples and then train supervised classifiers in the latent space. However, they require a clear definition of the target attribute as well as the corresponding manual annotations, severely limiting their applications in practice. In this work, we examine the internal representation learned by GANs to reveal the underlying variation factors in an unsupervised manner. By studying the essential role of the fully-connected layer that takes the latent code into the generator of GANs, we propose a general closed-form factorization method for latent semantic discovery. The properties of the identified semantics are further analyzed both theoretically and empirically. With its fast and efficient implementation, our approach is capable of not only finding latent semantics as accurately as the state-of-the-art supervised methods, but also resulting in far more versatile semantic classes across multiple GAN models trained on a wide range of datasets.
Unsupervised Landmark Learning from Unpaired Data
Jun 29, 2020
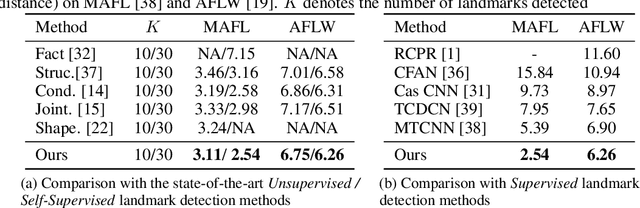
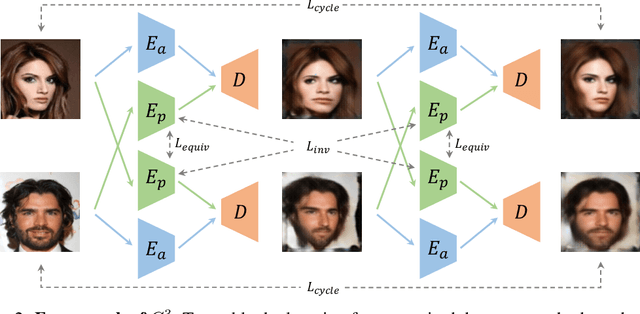
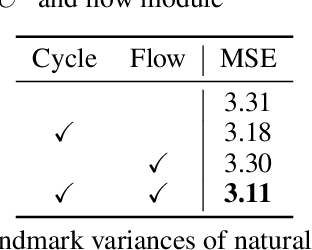
Recent attempts for unsupervised landmark learning leverage synthesized image pairs that are similar in appearance but different in poses. These methods learn landmarks by encouraging the consistency between the original images and the images reconstructed from swapped appearances and poses. While synthesized image pairs are created by applying pre-defined transformations, they can not fully reflect the real variances in both appearances and poses. In this paper, we aim to open the possibility of learning landmarks on unpaired data (i.e. unaligned image pairs) sampled from a natural image collection, so that they can be different in both appearances and poses. To this end, we propose a cross-image cycle consistency framework ($C^3$) which applies the swapping-reconstruction strategy twice to obtain the final supervision. Moreover, a cross-image flow module is further introduced to impose the equivariance between estimated landmarks across images. Through comprehensive experiments, our proposed framework is shown to outperform strong baselines by a large margin. Besides quantitative results, we also provide visualization and interpretation on our learned models, which not only verifies the effectiveness of the learned landmarks, but also leads to important insights that are beneficial for future research.
Video Representation Learning with Visual Tempo Consistency
Jun 28, 2020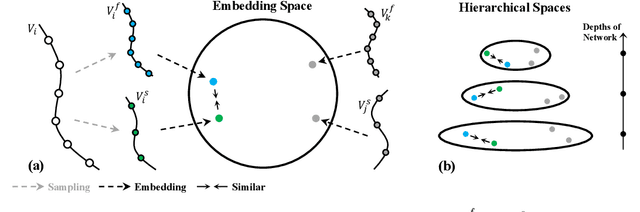
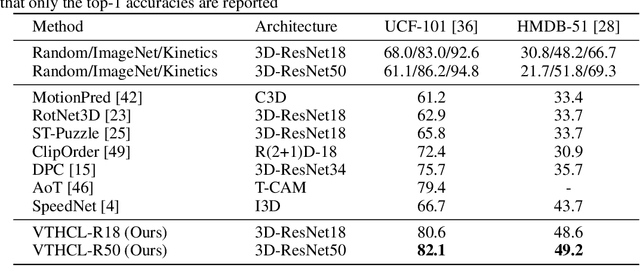


Visual tempo, which describes how fast an action goes, has shown its potential in supervised action recognition. In this work, we demonstrate that visual tempo can also serve as a self-supervision signal for video representation learning. We propose to maximize the mutual information between representations of slow and fast videos via hierarchical contrastive learning (VTHCL). Specifically, by sampling the same instance at slow and fast frame rates respectively, we can obtain slow and fast video frames which share the same semantics but contain different visual tempos. Video representations learned from VTHCL achieve the competitive performances under the self-supervision evaluation protocol for action recognition on UCF-101 (82.1\%) and HMDB-51 (49.2\%). Moreover, we show that the learned representations are also generalized well to other downstream tasks including action detection on AVA and action anticipation on Epic-Kitchen. Finally, our empirical analysis suggests that a more thorough evaluation protocol is needed to verify the effectiveness of the self-supervised video representations across network structures and downstream tasks.