 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTL-GRPO: Turn-Level RL for Reasoning-Guided Iterative Optimization
Jan 23, 2026Large language models have demonstrated strong reasoning capabilities in complex tasks through tool integration, which is typically framed as a Markov Decision Process and optimized with trajectory-level RL algorithms such as GRPO. However, a common class of reasoning tasks, iterative optimization, presents distinct challenges: the agent interacts with the same underlying environment state across turns, and the value of a trajectory is determined by the best turn-level reward rather than cumulative returns. Existing GRPO-based methods cannot perform fine-grained, turn-level optimization in such settings, while black-box optimization methods discard prior knowledge and reasoning capabilities. To address this gap, we propose Turn-Level GRPO (TL-GRPO), a lightweight RL algorithm that performs turn-level group sampling for fine-grained optimization. We evaluate TL-GRPO on analog circuit sizing (ACS), a challenging scientific optimization task requiring multiple simulations and domain expertise. Results show that TL-GRPO outperforms standard GRPO and Bayesian optimization methods across various specifications. Furthermore, our 30B model trained with TL-GRPO achieves state-of-the-art performance on ACS tasks under same simulation budget, demonstrating both strong generalization and practical utility.
Beyond the Dirac Delta: Mitigating Diversity Collapse in Reinforcement Fine-Tuning for Versatile Image Generation
Jan 18, 2026Reinforcement learning (RL) has emerged as a powerful paradigm for fine-tuning large-scale generative models, such as diffusion and flow models, to align with complex human preferences and user-specified tasks. A fundamental limitation remains \textit{the curse of diversity collapse}, where the objective formulation and optimization landscape inherently collapse the policy to a Dirac delta distribution. To address this challenge, we propose \textbf{DRIFT} (\textbf{D}ive\textbf{R}sity-\textbf{I}ncentivized Reinforcement \textbf{F}ine-\textbf{T}uning for Versatile Image Generation), an innovative framework that systematically incentivizes output diversity throughout the on-policy fine-tuning process, reconciling strong task alignment with high generation diversity to enhance versatility essential for applications that demand diverse candidate generations. We approach the problem across three representative perspectives: i) \textbf{sampling} a reward-concentrated subset that filters out reward outliers to prevent premature collapse; ii) \textbf{prompting} with stochastic variations to expand the conditioning space, and iii) \textbf{optimization} of the intra-group diversity with a potential-based reward shaping mechanism. Experimental results show that DRIFT achieves superior Pareto dominance regarding task alignment and generation diversity, yielding a $ 9.08\%\!\sim\! 43.46\%$ increase in diversity at equivalent alignment levels and a $ 59.65\% \!\sim\! 65.86\%$ increase in alignment at equivalent levels of diversity.
ABC-Bench: Benchmarking Agentic Backend Coding in Real-World Development
Jan 16, 2026The evolution of Large Language Models (LLMs) into autonomous agents has expanded the scope of AI coding from localized code generation to complex, repository-level, and execution-driven problem solving. However, current benchmarks predominantly evaluate code logic in static contexts, neglecting the dynamic, full-process requirements of real-world engineering, particularly in backend development which demands rigorous environment configuration and service deployment. To address this gap, we introduce ABC-Bench, a benchmark explicitly designed to evaluate agentic backend coding within a realistic, executable workflow. Using a scalable automated pipeline, we curated 224 practical tasks spanning 8 languages and 19 frameworks from open-source repositories. Distinct from previous evaluations, ABC-Bench require the agents to manage the entire development lifecycle from repository exploration to instantiating containerized services and pass the external end-to-end API tests. Our extensive evaluation reveals that even state-of-the-art models struggle to deliver reliable performance on these holistic tasks, highlighting a substantial disparity between current model capabilities and the demands of practical backend engineering. Our code is available at https://github.com/OpenMOSS/ABC-Bench.
From Performance to Practice: Knowledge-Distilled Segmentator for On-Premises Clinical Workflows
Jan 14, 2026Deploying medical image segmentation models in routine clinical workflows is often constrained by on-premises infrastructure, where computational resources are fixed and cloud-based inference may be restricted by governance and security policies. While high-capacity models achieve strong segmentation accuracy, their computational demands hinder practical deployment and long-term maintainability in hospital environments. We present a deployment-oriented framework that leverages knowledge distillation to translate a high-performing segmentation model into a scalable family of compact student models, without modifying the inference pipeline. The proposed approach preserves architectural compatibility with existing clinical systems while enabling systematic capacity reduction. The framework is evaluated on a multi-site brain MRI dataset comprising 1,104 3D volumes, with independent testing on 101 curated cases, and is further examined on abdominal CT to assess cross-modality generalizability. Under aggressive parameter reduction (94%), the distilled student model preserves nearly all of the teacher's segmentation accuracy (98.7%), while achieving substantial efficiency gains, including up to a 67% reduction in CPU inference latency without additional deployment overhead. These results demonstrate that knowledge distillation provides a practical and reliable pathway for converting research-grade segmentation models into maintainable, deployment-ready components for on-premises clinical workflows in real-world health systems.
Deconstructing Pre-training: Knowledge Attribution Analysis in MoE and Dense Models
Jan 13, 2026Mixture-of-Experts (MoE) architectures decouple model capacity from per-token computation, enabling scaling beyond the computational limits imposed by dense scaling laws. Yet how MoE architectures shape knowledge acquisition during pre-training, and how this process differs from dense architectures, remains unknown. To address this issue, we introduce Gated-LPI (Log-Probability Increase), a neuron-level attribution metric that decomposes log-probability increase across neurons. We present a time-resolved comparison of knowledge acquisition dynamics in MoE and dense architectures, tracking checkpoints over 1.2M training steps (~ 5.0T tokens) and 600K training steps (~ 2.5T tokens), respectively. Our experiments uncover three patterns: (1) Low-entropy backbone. The top approximately 1% of MoE neurons capture over 45% of positive updates, forming a high-utility core, which is absent in the dense baseline. (2) Early consolidation. The MoE model locks into a stable importance profile within < 100K steps, whereas the dense model remains volatile throughout training. (3) Functional robustness. Masking the ten most important MoE attention heads reduces relational HIT@10 by < 10%, compared with > 50% for the dense model, showing that sparsity fosters distributed -- rather than brittle -- knowledge storage. These patterns collectively demonstrate that sparsity fosters an intrinsically stable and distributed computational backbone from early in training, helping bridge the gap between sparse architectures and training-time interpretability.
Multi-hop Reasoning via Early Knowledge Alignment
Dec 23, 2025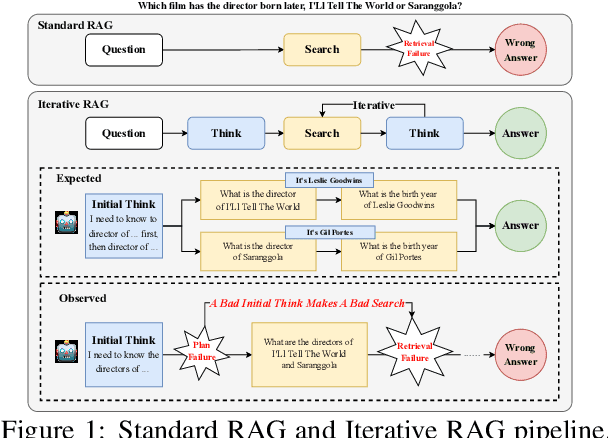

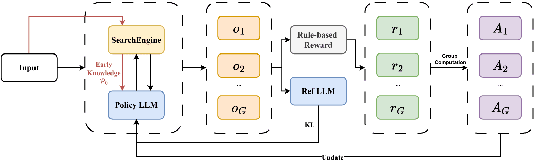
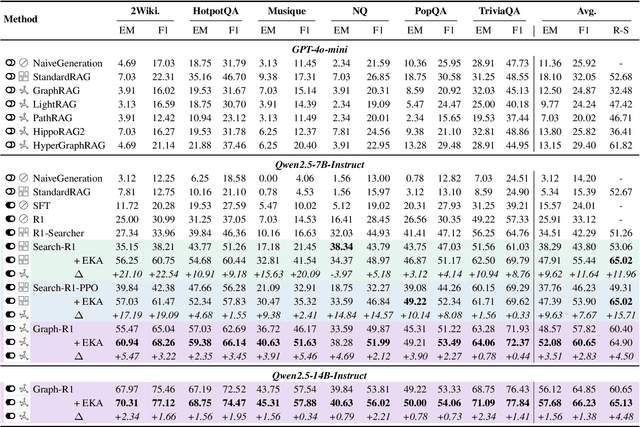
Retrieval-Augmented Generation (RAG) has emerged as a powerful paradigm for Large Language Models (LLMs) to address knowledge-intensive queries requiring domain-specific or up-to-date information. To handle complex multi-hop questions that are challenging for single-step retrieval, iterative RAG approaches incorporating reinforcement learning have been proposed. However, existing iterative RAG systems typically plan to decompose questions without leveraging information about the available retrieval corpus, leading to inefficient retrieval and reasoning chains that cascade into suboptimal performance. In this paper, we introduce Early Knowledge Alignment (EKA), a simple but effective module that aligns LLMs with retrieval set before planning in iterative RAG systems with contextually relevant retrieved knowledge. Extensive experiments on six standard RAG datasets demonstrate that by establishing a stronger reasoning foundation, EKA significantly improves retrieval precision, reduces cascading errors, and enhances both performance and efficiency. Our analysis from an entropy perspective demonstrate that incorporating early knowledge reduces unnecessary exploration during the reasoning process, enabling the model to focus more effectively on relevant information subsets. Moreover, EKA proves effective as a versatile, training-free inference strategy that scales seamlessly to large models. Generalization tests across diverse datasets and retrieval corpora confirm the robustness of our approach. Overall, EKA advances the state-of-the-art in iterative RAG systems while illuminating the critical interplay between structured reasoning and efficient exploration in reinforcement learning-augmented frameworks. The code is released at \href{https://github.com/yxzwang/EarlyKnowledgeAlignment}{Github}.
Grad: Guided Relation Diffusion Generation for Graph Augmentation in Graph Fraud Detection
Dec 19, 2025



Nowadays, Graph Fraud Detection (GFD) in financial scenarios has become an urgent research topic to protect online payment security. However, as organized crime groups are becoming more professional in real-world scenarios, fraudsters are employing more sophisticated camouflage strategies. Specifically, fraudsters disguise themselves by mimicking the behavioral data collected by platforms, ensuring that their key characteristics are consistent with those of benign users to a high degree, which we call Adaptive Camouflage. Consequently, this narrows the differences in behavioral traits between them and benign users within the platform's database, thereby making current GFD models lose efficiency. To address this problem, we propose a relation diffusion-based graph augmentation model Grad. In detail, Grad leverages a supervised graph contrastive learning module to enhance the fraud-benign difference and employs a guided relation diffusion generator to generate auxiliary homophilic relations from scratch. Based on these, weak fraudulent signals would be enhanced during the aggregation process, thus being obvious enough to be captured. Extensive experiments have been conducted on two real-world datasets provided by WeChat Pay, one of the largest online payment platforms with billions of users, and three public datasets. The results show that our proposed model Grad outperforms SOTA methods in both various scenarios, achieving at most 11.10% and 43.95% increases in AUC and AP, respectively. Our code is released at https://github.com/AI4Risk/antifraud and https://github.com/Muyiiiii/WWW25-Grad.
* Accepted by The Web Conference 2025 (WWW'25). 12 pages, includes implementation details. Code: https://github.com/AI4Risk/antifraud and https://github.com/Muyiiiiii/WWW25-Grad
Benchmarking and Adapting On-Device Large Language Models for Clinical Decision Support
Dec 18, 2025Large language models (LLMs) have rapidly advanced in clinical decision-making, yet the deployment of proprietary systems is hindered by privacy concerns and reliance on cloud-based infrastructure. Open-source alternatives allow local inference but often require large model sizes that limit their use in resource-constrained clinical settings. Here, we benchmark two on-device LLMs, gpt-oss-20b and gpt-oss-120b, across three representative clinical tasks: general disease diagnosis, specialty-specific (ophthalmology) diagnosis and management, and simulation of human expert grading and evaluation. We compare their performance with state-of-the-art proprietary models (GPT-5 and o4-mini) and a leading open-source model (DeepSeek-R1), and we further evaluate the adaptability of on-device systems by fine-tuning gpt-oss-20b on general diagnostic data. Across tasks, gpt-oss models achieve performance comparable to or exceeding DeepSeek-R1 and o4-mini despite being substantially smaller. In addition, fine-tuning remarkably improves the diagnostic accuracy of gpt-oss-20b, enabling it to approach the performance of GPT-5. These findings highlight the potential of on-device LLMs to deliver accurate, adaptable, and privacy-preserving clinical decision support, offering a practical pathway for broader integration of LLMs into routine clinical practice.
TF-MCL: Time-frequency Fusion and Multi-domain Cross-Loss for Self-supervised Depression Detection
Dec 14, 2025In recent years, there has been a notable increase in the use of supervised detection methods of major depressive disorder (MDD) based on electroencephalogram (EEG) signals. However, the process of labeling MDD remains challenging. As a self-supervised learning method, contrastive learning could address the shortcomings of supervised learning methods, which are unduly reliant on labels in the context of MDD detection. However, existing contrastive learning methods are not specifically designed to characterize the time-frequency distribution of EEG signals, and their capacity to acquire low-semantic data representations is still inadequate for MDD detection tasks. To address the problem of contrastive learning method, we propose a time-frequency fusion and multi-domain cross-loss (TF-MCL) model for MDD detection. TF-MCL generates time-frequency hybrid representations through the use of a fusion mapping head (FMH), which efficiently remaps time-frequency domain information to the fusion domain, and thus can effectively enhance the model's capacity to synthesize time-frequency information. Moreover, by optimizing the multi-domain cross-loss function, the distribution of the representations in the time-frequency domain and the fusion domain is reconstructed, thereby improving the model's capacity to acquire fusion representations. We evaluated the performance of our model on the publicly available datasets MODMA and PRED+CT and show a significant improvement in accuracy, outperforming the existing state-of-the-art (SOTA) method by 5.87% and 9.96%, respectively.
A 96pJ/Frame/Pixel and 61pJ/Event Anti-UAV System with Hybrid Object Tracking Modes
Dec 12, 2025We present an energy-efficient anti-UAV system that integrates frame-based and event-driven object tracking to enable reliable detection of small and fast-moving drones. The system reconstructs binary event frames using run-length encoding, generates region proposals, and adaptively switches between frame mode and event mode based on object size and velocity. A Fast Object Tracking Unit improves robustness for high-speed targets through adaptive thresholding and trajectory-based classification. The neural processing unit supports both grayscale-patch and trajectory inference with a custom instruction set and a zero-skipping MAC architecture, reducing redundant neural computations by more than 97 percent. Implemented in 40 nm CMOS technology, the 2 mm^2 chip achieves 96 pJ per frame per pixel and 61 pJ per event at 0.8 V, and reaches 98.2 percent recognition accuracy on public UAV datasets across 50 to 400 m ranges and 5 to 80 pixels per second speeds. The results demonstrate state-of-the-art end-to-end energy efficiency for anti-UAV systems.