 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecodingTrust: A Comprehensive Assessment of Trustworthiness in GPT Models
Jun 20, 2023



Generative Pre-trained Transformer (GPT) models have exhibited exciting progress in capabilities, capturing the interest of practitioners and the public alike. Yet, while the literature on the trustworthiness of GPT models remains limited, practitioners have proposed employing capable GPT models for sensitive applications to healthcare and finance - where mistakes can be costly. To this end, this work proposes a comprehensive trustworthiness evaluation for large language models with a focus on GPT-4 and GPT-3.5, considering diverse perspectives - including toxicity, stereotype bias, adversarial robustness, out-of-distribution robustness, robustness on adversarial demonstrations, privacy, machine ethics, and fairness. Based on our evaluations, we discover previously unpublished vulnerabilities to trustworthiness threats. For instance, we find that GPT models can be easily misled to generate toxic and biased outputs and leak private information in both training data and conversation history. We also find that although GPT-4 is usually more trustworthy than GPT-3.5 on standard benchmarks, GPT-4 is more vulnerable given jailbreaking system or user prompts, potentially due to the reason that GPT-4 follows the (misleading) instructions more precisely. Our work illustrates a comprehensive trustworthiness evaluation of GPT models and sheds light on the trustworthiness gaps. Our benchmark is publicly available at https://decodingtrust.github.io/.
Prior-knowledge-informed deep learning for lacune detection and quantification using multi-site brain MRI
Jun 18, 2023

Lacunes of presumed vascular origin, also referred to as lacunar infarcts, are important to assess cerebral small vessel disease and cognitive diseases such as dementia. However, visual rating of lacunes from imaging data is challenging, time-consuming, and rater-dependent, owing to their small size, sparsity, and mimics. Whereas recent developments in automatic algorithms have shown to make the detection of lacunes faster while preserving sensitivity, they also showed a large number of false positives, which makes them impractical for use in clinical practice or large-scale studies. Here, we develop a novel framework that, in addition to lacune detection, outputs a categorical burden score. This score could provide a more practical estimate of lacune presence that simplifies and effectively accelerates the imaging assessment of lacunes. We hypothesize that the combination of detection and the categorical score makes the procedure less sensitive to noisy labels.
Deep learning-based group-wise registration for longitudinal MRI analysis in glioma
Jun 18, 2023



Glioma growth may be quantified with longitudinal image registration. However, the large mass-effects and tissue changes across images pose an added challenge. Here, we propose a longitudinal, learning-based, and groupwise registration method for the accurate and unbiased registration of glioma MRI. We evaluate on a dataset from the Glioma Longitudinal AnalySiS consortium and compare it to classical registration methods. We achieve comparable Dice coefficients, with more detailed registrations, while significantly reducing the runtime to under a minute. The proposed methods may serve as an alternative to classical toolboxes, to provide further insight into glioma growth.
Evaluation and Optimization of Gradient Compression for Distributed Deep Learning
Jun 15, 2023To accelerate distributed training, many gradient compression methods have been proposed to alleviate the communication bottleneck in synchronous stochastic gradient descent (S-SGD), but their efficacy in real-world applications still remains unclear. In this work, we first evaluate the efficiency of three representative compression methods (quantization with Sign-SGD, sparsification with Top-k SGD, and low-rank with Power-SGD) on a 32-GPU cluster. The results show that they cannot always outperform well-optimized S-SGD or even worse due to their incompatibility with three key system optimization techniques (all-reduce, pipelining, and tensor fusion) in S-SGD. To this end, we propose a novel gradient compression method, called alternate compressed Power-SGD (ACP-SGD), which alternately compresses and communicates low-rank matrices. ACP-SGD not only significantly reduces the communication volume, but also enjoys the three system optimizations like S-SGD. Compared with Power-SGD, the optimized ACP-SGD can largely reduce the compression and communication overheads, while achieving similar model accuracy. In our experiments, ACP-SGD achieves an average of 4.06x and 1.43x speedups over S-SGD and Power-SGD, respectively, and it consistently outperforms other baselines across different setups (from 8 GPUs to 64 GPUs and from 1Gb/s Ethernet to 100Gb/s InfiniBand).
MIMIC-IT: Multi-Modal In-Context Instruction Tuning
Jun 08, 2023



High-quality instructions and responses are essential for the zero-shot performance of large language models on interactive natural language tasks. For interactive vision-language tasks involving intricate visual scenes, a large quantity of diverse and creative instruction-response pairs should be imperative to tune vision-language models (VLMs). Nevertheless, the current availability of vision-language instruction-response pairs in terms of quantity, diversity, and creativity remains limited, posing challenges to the generalization of interactive VLMs. Here we present MultI-Modal In-Context Instruction Tuning (MIMIC-IT), a dataset comprising 2.8 million multimodal instruction-response pairs, with 2.2 million unique instructions derived from images and videos. Each pair is accompanied by multi-modal in-context information, forming conversational contexts aimed at empowering VLMs in perception, reasoning, and planning. The instruction-response collection process, dubbed as Syphus, is scaled using an automatic annotation pipeline that combines human expertise with GPT's capabilities. Using the MIMIC-IT dataset, we train a large VLM named Otter. Based on extensive evaluations conducted on vision-language benchmarks, it has been observed that Otter demonstrates remarkable proficiency in multi-modal perception, reasoning, and in-context learning. Human evaluation reveals it effectively aligns with the user's intentions. We release the MIMIC-IT dataset, instruction-response collection pipeline, benchmarks, and the Otter model.
MultiSum: A Dataset for Multimodal Summarization and Thumbnail Generation of Videos
Jun 07, 2023
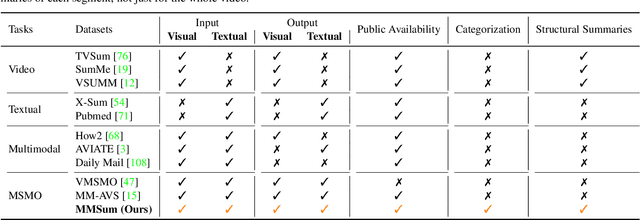
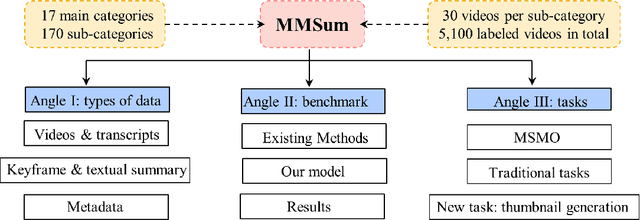
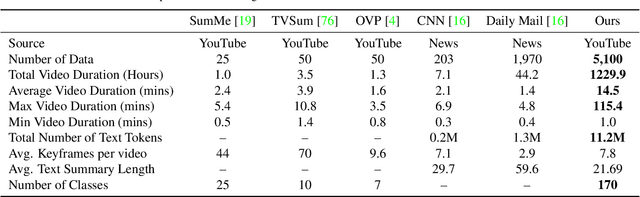
Multimodal summarization with multimodal output (MSMO) has emerged as a promising research direction. Nonetheless, numerous limitations exist within existing public MSMO datasets, including insufficient upkeep, data inaccessibility, limited size, and the absence of proper categorization, which pose significant challenges to effective research. To address these challenges and provide a comprehensive dataset for this new direction, we have meticulously curated the MultiSum dataset. Our new dataset features (1) Human-validated summaries for both video and textual content, providing superior human instruction and labels for multimodal learning. (2) Comprehensively and meticulously arranged categorization, spanning 17 principal categories and 170 subcategories to encapsulate a diverse array of real-world scenarios. (3) Benchmark tests performed on the proposed dataset to assess varied tasks and methods, including video temporal segmentation, video summarization, text summarization, and multimodal summarization. To champion accessibility and collaboration, we release the MultiSum dataset and the data collection tool as fully open-source resources, fostering transparency and accelerating future developments. Our project website can be found at https://multisum-dataset.github.io/.
UMD: Unsupervised Model Detection for X2X Backdoor Attacks
Jun 02, 2023



Backdoor (Trojan) attack is a common threat to deep neural networks, where samples from one or more source classes embedded with a backdoor trigger will be misclassified to adversarial target classes. Existing methods for detecting whether a classifier is backdoor attacked are mostly designed for attacks with a single adversarial target (e.g., all-to-one attack). To the best of our knowledge, without supervision, no existing methods can effectively address the more general X2X attack with an arbitrary number of source classes, each paired with an arbitrary target class. In this paper, we propose UMD, the first Unsupervised Model Detection method that effectively detects X2X backdoor attacks via a joint inference of the adversarial (source, target) class pairs. In particular, we first define a novel transferability statistic to measure and select a subset of putative backdoor class pairs based on a proposed clustering approach. Then, these selected class pairs are jointly assessed based on an aggregation of their reverse-engineered trigger size for detection inference, using a robust and unsupervised anomaly detector we proposed. We conduct comprehensive evaluations on CIFAR-10, GTSRB, and Imagenette dataset, and show that our unsupervised UMD outperforms SOTA detectors (even with supervision) by 17%, 4%, and 8%, respectively, in terms of the detection accuracy against diverse X2X attacks. We also show the strong detection performance of UMD against several strong adaptive attacks.
How to Estimate Model Transferability of Pre-Trained Speech Models?
Jun 01, 2023In this work, we introduce a ``score-based assessment'' framework for estimating the transferability of pre-trained speech models (PSMs) for fine-tuning target tasks. We leverage upon two representation theories, Bayesian likelihood estimation and optimal transport, to generate rank scores for the PSM candidates using the extracted representations. Our framework efficiently computes transferability scores without actual fine-tuning of candidate models or layers by making a temporal independent hypothesis. We evaluate some popular supervised speech models (e.g., Conformer RNN-Transducer) and self-supervised speech models (e.g., HuBERT) in cross-layer and cross-model settings using public data. Experimental results show a high Spearman's rank correlation and low $p$-value between our estimation framework and fine-tuning ground truth. Our proposed transferability framework requires less computational time and resources, making it a resource-saving and time-efficient approach for tuning speech foundation models.
Competing for Shareable Arms in Multi-Player Multi-Armed Bandits
May 30, 2023

Competitions for shareable and limited resources have long been studied with strategic agents. In reality, agents often have to learn and maximize the rewards of the resources at the same time. To design an individualized competing policy, we model the competition between agents in a novel multi-player multi-armed bandit (MPMAB) setting where players are selfish and aim to maximize their own rewards. In addition, when several players pull the same arm, we assume that these players averagely share the arms' rewards by expectation. Under this setting, we first analyze the Nash equilibrium when arms' rewards are known. Subsequently, we propose a novel SelfishMPMAB with Averaging Allocation (SMAA) approach based on the equilibrium. We theoretically demonstrate that SMAA could achieve a good regret guarantee for each player when all players follow the algorithm. Additionally, we establish that no single selfish player can significantly increase their rewards through deviation, nor can they detrimentally affect other players' rewards without incurring substantial losses for themselves. We finally validate the effectiveness of the method in extensive synthetic experiments.
GrowSP: Unsupervised Semantic Segmentation of 3D Point Clouds
May 25, 2023



We study the problem of 3D semantic segmentation from raw point clouds. Unlike existing methods which primarily rely on a large amount of human annotations for training neural networks, we propose the first purely unsupervised method, called GrowSP, to successfully identify complex semantic classes for every point in 3D scenes, without needing any type of human labels or pretrained models. The key to our approach is to discover 3D semantic elements via progressive growing of superpoints. Our method consists of three major components, 1) the feature extractor to learn per-point features from input point clouds, 2) the superpoint constructor to progressively grow the sizes of superpoints, and 3) the semantic primitive clustering module to group superpoints into semantic elements for the final semantic segmentation. We extensively evaluate our method on multiple datasets, demonstrating superior performance over all unsupervised baselines and approaching the classic fully-supervised PointNet. We hope our work could inspire more advanced methods for unsupervised 3D semantic learning.