 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeechEQ: Benchmarking Emotional Intelligence Quotient in Socially Aware Voice Conversational Models
Jun 24, 2026As multimodal conversational systems increasingly engage in spoken interaction, their ability to navigate paralinguistic social cues has become a critical bottleneck for natural human-AI communication. However, existing evaluations of machine emotional intelligence assess reasoning exclusively through isolated text or passive acoustic perception, overlooking the complex cross-modal reasoning required for active, multi-turn dialogue. We introduce \textsc{SpeechEQ}, a comprehensive framework designed to evaluate the sociolinguistic reasoning of Speech-Language Models (SLMs). The framework includes a validated dataset of 2,265 dialogues across 15 Emotional Quotient (EQ) subscales grounded in EQ-i 2.0 theory, along with a multi-turn evaluation protocol measured by our proposed Spoken EQ (SEQ) score inspired by human EQ assessments. Experiments show limitations in how both existing Speech Emotion Recognition and end-to-end Speech-Language Models understand and apply paralinguistic cues through speech. While end-to-end architectures outperform cascaded systems, \textsc{SpeechEQ} reveals that current multimodal models remain bottlenecked by a text-reliant ``modality shortcut,'' an alignment-induced ``safety trap,'' and ``contextual amnesia,'' highlighting the barriers to truly emotionally aware AI. Our benchmark can be accessed at https://huggingface.co/datasets/SpeechEQ/SpeechEQ and demo page at https://binomial14.github.io/speecheq-demo/
TW-LegalBench: Measuring Taiwanese Legal Understanding
Jun 17, 2026Large language models (LLMs) have shown impressive capabilities across diverse tasks, yet their performance on jurisdiction-specific legal reasoning remains underexplored. We present TW-LegalBench that utilizes Taiwanese legal system's rich official corpus open to the public to fill the gap in evaluating LLMs on Taiwanese law, among common-law benchmarks that focus on English sources and civil-law benchmarks focusing on sources of Simplified Chinese. TW-LegalBench comprises three task types: (1) over 16,000 multiple-choice questions (MCQs) across five years of official examinations in 18 professional domains; (2) 117 open-ended essay questions (OEQs) from examinations for legal professionals with official scoring rubrics; and (3) more than 14,000 legal judgment prediction (LJP) instances covering hundreds of crime categories. We evaluate 13 LLMs using accuracy for MCQs, a decomposed LLM-as-Judge framework based on the scoring rubric points for OEQs, and metrics for sentencing accuracy and statute citation for LJP. Our results reveal that top-performing models exceed the passing threshold for qualified lawyers (passing rate: 11%) but fall short of that for judges and prosecutors (passing rate: 1~2%). For LJP, while models demonstrate reasonable verdict type accuracy and sentence prediction capability, they struggle to cite exact legal articles. These findings highlight that reliable legal text generation remains challenging for LLMs, even though their performance on qualification examinations approaches human level.
The First Drop of Ink: Nonlinear Impact of Misleading Information in Long-Context Reasoning
May 11, 2026As large language models are increasingly deployed in retrieval-augmented generation and agentic systems that accumulate extensive context, understanding how distracting information affects long-context performance becomes critical. Prior work shows that semantically relevant yet misleading documents degrade performance, but the quantitative relationship between the proportion of distractors and performance remains unstudied. In this work, we systematically vary the hard-distractor proportion in fixed-length contexts, revealing a striking nonlinear pattern: as the proportion of hard distractors increases, performance drops sharply within the first small fraction, while the remainder of the range yields only marginal additional decline. We term this ''The First Drop of Ink'' effect, analogous to how a single drop of ink contaminates water. Our theoretical and empirical analyses grounded in attention mechanics show that hard distractors capture disproportionate attention even at small proportions, with diminishing marginal impact as their proportion grows. Controlled experiments further show that filtering gains mainly come from context-length reduction rather than distractor removal; substantial recovery requires reducing the hard-distractor proportion to near zero, highlighting the importance of upstream retrieval precision.
Continual Pre-Training is (not) What You Need in Domain Adaption
Apr 18, 2025The recent advances in Legal Large Language Models (LLMs) have transformed the landscape of legal research and practice by automating tasks, enhancing research precision, and supporting complex decision-making processes. However, effectively adapting LLMs to the legal domain remains challenging due to the complexity of legal reasoning, the need for precise interpretation of specialized language, and the potential for hallucinations. This paper examines the efficacy of Domain-Adaptive Continual Pre-Training (DACP) in improving the legal reasoning capabilities of LLMs. Through a series of experiments on legal reasoning tasks within the Taiwanese legal framework, we demonstrate that while DACP enhances domain-specific knowledge, it does not uniformly improve performance across all legal tasks. We discuss the trade-offs involved in DACP, particularly its impact on model generalization and performance in prompt-based tasks, and propose directions for future research to optimize domain adaptation strategies in legal AI.
How to Learn a New Language? An Efficient Solution for Self-Supervised Learning Models Unseen Languages Adaption in Low-Resource Scenario
Nov 27, 2024



The utilization of speech Self-Supervised Learning (SSL) models achieves impressive performance on Automatic Speech Recognition (ASR). However, in low-resource language ASR, they encounter the domain mismatch problem between pre-trained and low-resource languages. Typical solutions like fine-tuning the SSL model suffer from high computation costs while using frozen SSL models as feature extractors comes with poor performance. To handle these issues, we extend a conventional efficient fine-tuning scheme based on the adapter. We add an extra intermediate adaptation to warm up the adapter and downstream model initialization. Remarkably, we update only 1-5% of the total model parameters to achieve the adaptation. Experimental results on the ML-SUPERB dataset show that our solution outperforms conventional efficient fine-tuning. It achieves up to a 28% relative improvement in the Character/Phoneme error rate when adapting to unseen languages.
NeKo: Toward Post Recognition Generative Correction Large Language Models with Task-Oriented Experts
Nov 08, 2024
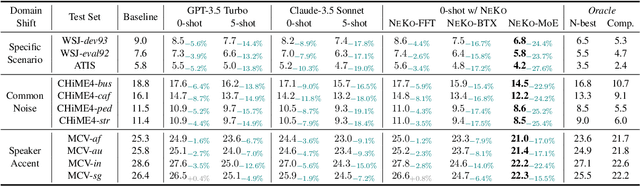
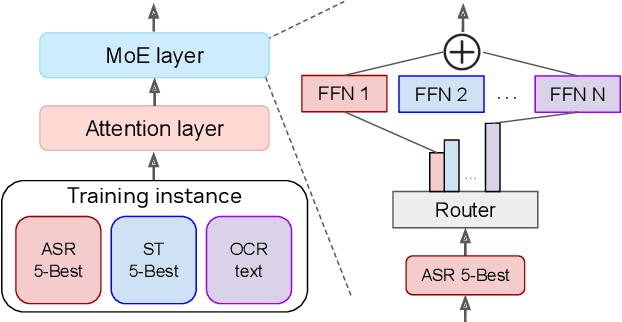
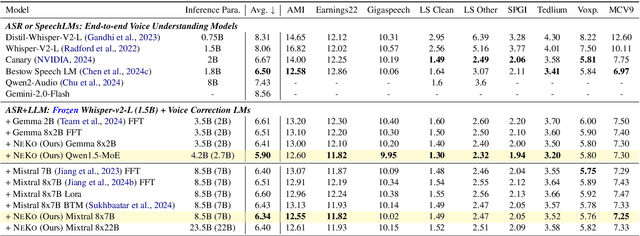
Construction of a general-purpose post-recognition error corrector poses a crucial question: how can we most effectively train a model on a large mixture of domain datasets? The answer would lie in learning dataset-specific features and digesting their knowledge in a single model. Previous methods achieve this by having separate correction language models, resulting in a significant increase in parameters. In this work, we present Mixture-of-Experts as a solution, highlighting that MoEs are much more than a scalability tool. We propose a Multi-Task Correction MoE, where we train the experts to become an ``expert'' of speech-to-text, language-to-text and vision-to-text datasets by learning to route each dataset's tokens to its mapped expert. Experiments on the Open ASR Leaderboard show that we explore a new state-of-the-art performance by achieving an average relative $5.0$% WER reduction and substantial improvements in BLEU scores for speech and translation tasks. On zero-shot evaluation, NeKo outperforms GPT-3.5 and Claude-Opus with $15.5$% to $27.6$% relative WER reduction in the Hyporadise benchmark. NeKo performs competitively on grammar and post-OCR correction as a multi-task model.
Leave No Knowledge Behind During Knowledge Distillation: Towards Practical and Effective Knowledge Distillation for Code-Switching ASR Using Realistic Data
Jul 15, 2024



Recent advances in automatic speech recognition (ASR) often rely on large speech foundation models for generating high-quality transcriptions. However, these models can be impractical due to limited computing resources. The situation is even more severe in terms of more realistic or difficult scenarios, such as code-switching ASR (CS-ASR). To address this, we present a framework for developing more efficient models for CS-ASR through knowledge distillation using realistic speech-only data. Our proposed method, Leave No Knowledge Behind During Knowledge Distillation (K$^2$D), leverages both the teacher model's knowledge and additional insights from a small auxiliary model. We evaluate our approach on two in-domain and two out-domain datasets, demonstrating that K$^2$D is effective. By conducting K$^2$D on the unlabeled realistic data, we have successfully obtained a 2-time smaller model with 5-time faster generation speed while outperforming the baseline methods and the teacher model on all the testing sets. We have made our model publicly available on Hugging Face (https://huggingface.co/andybi7676/k2d-whisper.zh-en).
PEFT for Speech: Unveiling Optimal Placement, Merging Strategies, and Ensemble Techniques
Jan 04, 2024



Parameter-Efficient Fine-Tuning (PEFT) is increasingly recognized as an effective method in speech processing. However, the optimal approach and the placement of PEFT methods remain inconclusive. Our study conducts extensive experiments to compare different PEFT methods and their layer-wise placement adapting Differentiable Architecture Search (DARTS). We also explore the use of ensemble learning to leverage diverse PEFT strategies. The results reveal that DARTS does not outperform the baseline approach, which involves inserting the same PEFT method into all layers of a Self-Supervised Learning (SSL) model. In contrast, an ensemble learning approach, particularly one employing majority voting, demonstrates superior performance. Our statistical evidence indicates that different PEFT methods learn in varied ways. This variation might explain why the synergistic integration of various PEFT methods through ensemble learning can harness their unique learning capabilities more effectively compared to individual layer-wise optimization.
How to Estimate Model Transferability of Pre-Trained Speech Models?
Jun 01, 2023



In this work, we introduce a ``score-based assessment'' framework for estimating the transferability of pre-trained speech models (PSMs) for fine-tuning target tasks. We leverage upon two representation theories, Bayesian likelihood estimation and optimal transport, to generate rank scores for the PSM candidates using the extracted representations. Our framework efficiently computes transferability scores without actual fine-tuning of candidate models or layers by making a temporal independent hypothesis. We evaluate some popular supervised speech models (e.g., Conformer RNN-Transducer) and self-supervised speech models (e.g., HuBERT) in cross-layer and cross-model settings using public data. Experimental results show a high Spearman's rank correlation and low $p$-value between our estimation framework and fine-tuning ground truth. Our proposed transferability framework requires less computational time and resources, making it a resource-saving and time-efficient approach for tuning speech foundation models.
CHAPTER: Exploiting Convolutional Neural Network Adapters for Self-supervised Speech Models
Dec 01, 2022Self-supervised learning (SSL) is a powerful technique for learning representations from unlabeled data. Transformer based models such as HuBERT, which consist a feature extractor and transformer layers, are leading the field in the speech domain. SSL models are fine-tuned on a wide range of downstream tasks, which involves re-training the majority of the model for each task. Previous studies have introduced applying adapters, which are small lightweight modules commonly used in Natural Language Processing (NLP) to adapt pre-trained models to new tasks. However, such efficient tuning techniques only provide adaptation at the transformer layer, but failed to perform adaptation at the feature extractor. In this paper, we propose CHAPTER, an efficient tuning method specifically designed for SSL speech model, by applying CNN adapters at the feature extractor. Using this method, we can only fine-tune fewer than 5% of parameters per task compared to fully fine-tuning and achieve better and more stable performance. We empirically found that adding CNN adapters to the feature extractor can help the adaptation on emotion and speaker tasks. For instance, the accuracy of SID is improved from 87.71 to 91.56, and the accuracy of ER is improved by 5%.