 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiRD: Reliable Set-Valued Prediction for Open-Ended Question Answering via Miscoverage Risk Decomposition
May 25, 2026Reliable set-valued prediction provides a principled way to mitigate hallucinations in open-ended question answering (QA), yet existing conformal approaches typically rely on a fragile premise: finite sampling must already produce at least one admissible candidate, or calibration examples violating this condition are discarded. In this paper, we introduce MiRD, a two-stage framework that decomposes overall miscoverage into sampling failure and conditional selection failure. In Stage I, MiRD establishes an expectation-level marginal upper bound on the probability that finite sampling produces no admissible answer under a fixed budget. In Stage II, conditioned on sampling success, MiRD calibrates a conformal selection threshold using admission-correlated nonconformity scores defined over the full calibration set, thereby preserving calibration-set integrity. Across three open-ended QA datasets and eight models, MiRD controls sampling risk, conditional selection risk, and overall miscoverage, while yielding tighter first-stage bounds than PAC-style alternatives and more adaptive prediction sets than successful-only calibration.
Set-Valued Prediction for Large Language Models with Feasibility-Aware Coverage Guarantees
Mar 24, 2026Large language models (LLMs) inherently operate over a large generation space, yet conventional usage typically reports the most likely generation (MLG) as a point prediction, which underestimates the model's capability: although the top-ranked response can be incorrect, valid answers may still exist within the broader output space and can potentially be discovered through repeated sampling. This observation motivates moving from point prediction to set-valued prediction, where the model produces a set of candidate responses rather than a single MLG. In this paper, we propose a principled framework for set-valued prediction, which provides feasibility-aware coverage guarantees. We show that, given the finite-sampling nature of LLM generation, coverage is not always achievable: even with multiple samplings, LLMs may fail to yield an acceptable response for certain questions within the sampled candidate set. To address this, we establish a minimum achievable risk level (MRL), below which statistical coverage guarantees cannot be satisfied. Building on this insight, we then develop a data-driven calibration procedure that constructs prediction sets from sampled responses by estimating a rigorous threshold, ensuring that the resulting set contains a correct answer with a desired probability whenever the target risk level is feasible. Extensive experiments on six language generation tasks with five LLMs demonstrate both the statistical validity and the predictive efficiency of our framework.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Green View Index Analysis and Optimal Green View Index Path Based on Street View and Deep Learning
Apr 26, 2021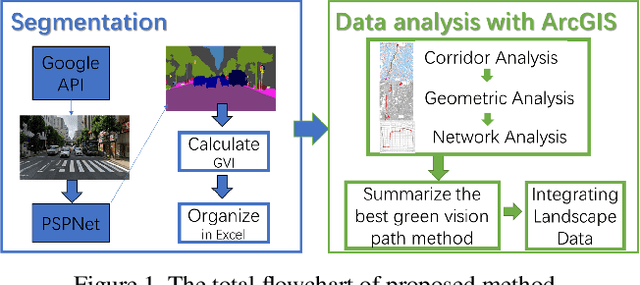
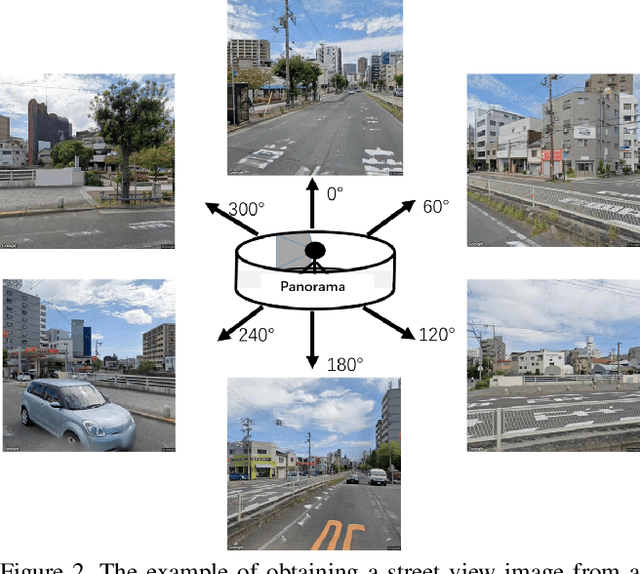


Streetscapes are an important part of the urban landscape, analysing and studying them can increase the understanding of the cities' infrastructure, which can lead to better planning and design of the urban living environment. In this paper, we used Google API to obtain street view images of Osaka City. The semantic segmentation model PSPNet is used to segment the Osaka City street view images and analyse the Green View Index (GVI) data of Osaka area. Based on the GVI data, three methods, namely corridor analysis, geometric network and a combination of them, were then used to calculate the optimal GVI paths in Osaka City. The corridor analysis and geometric network methods allow for a more detailed delineation of the optimal GVI path from general areas to specific routes. Our analysis not only allows for the calculation of specific routes for the optimal GVI paths, but also allows for the visualisation and integration of neighbourhood landscape data. By summarising all the data, a more specific and objective analysis of the landscape in the study area can be carried out and based on this, the available natural resources can be maximised for a better life.