 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Domain-Specific Post-Training for Multimodal Large Language Models
Nov 29, 2024



Recent years have witnessed the rapid development of general multimodal large language models (MLLMs). However, adapting general MLLMs to specific domains, such as scientific fields and industrial applications, remains less explored. This paper systematically investigates domain adaptation of MLLMs through post-training, focusing on data synthesis, training pipelines, and task evaluation. (1) Data Synthesis: Using open-source models, we develop a visual instruction synthesizer that effectively generates diverse visual instruction tasks from domain-specific image-caption pairs. Our synthetic tasks surpass those generated by manual rules, GPT-4, and GPT-4V in enhancing the domain-specific performance of MLLMs. (2) Training Pipeline: While the two-stage training--initially on image-caption pairs followed by visual instruction tasks--is commonly adopted for developing general MLLMs, we apply a single-stage training pipeline to enhance task diversity for domain-specific post-training. (3) Task Evaluation: We conduct experiments in two domains, biomedicine and food, by post-training MLLMs of different sources and scales (e.g., Qwen2-VL-2B, LLaVA-v1.6-8B, Llama-3.2-11B), and then evaluating MLLM performance on various domain-specific tasks. To support further research in MLLM domain adaptation, we will open-source our implementations.
DRiVE: Diffusion-based Rigging Empowers Generation of Versatile and Expressive Characters
Nov 26, 2024



Recent advances in generative models have enabled high-quality 3D character reconstruction from multi-modal. However, animating these generated characters remains a challenging task, especially for complex elements like garments and hair, due to the lack of large-scale datasets and effective rigging methods. To address this gap, we curate AnimeRig, a large-scale dataset with detailed skeleton and skinning annotations. Building upon this, we propose DRiVE, a novel framework for generating and rigging 3D human characters with intricate structures. Unlike existing methods, DRiVE utilizes a 3D Gaussian representation, facilitating efficient animation and high-quality rendering. We further introduce GSDiff, a 3D Gaussian-based diffusion module that predicts joint positions as spatial distributions, overcoming the limitations of regression-based approaches. Extensive experiments demonstrate that DRiVE achieves precise rigging results, enabling realistic dynamics for clothing and hair, and surpassing previous methods in both quality and versatility. The code and dataset will be made public for academic use upon acceptance.
Boosting 3D Object Generation through PBR Materials
Nov 25, 2024Automatic 3D content creation has gained increasing attention recently, due to its potential in various applications such as video games, film industry, and AR/VR. Recent advancements in diffusion models and multimodal models have notably improved the quality and efficiency of 3D object generation given a single RGB image. However, 3D objects generated even by state-of-the-art methods are still unsatisfactory compared to human-created assets. Considering only textures instead of materials makes these methods encounter challenges in photo-realistic rendering, relighting, and flexible appearance editing. And they also suffer from severe misalignment between geometry and high-frequency texture details. In this work, we propose a novel approach to boost the quality of generated 3D objects from the perspective of Physics-Based Rendering (PBR) materials. By analyzing the components of PBR materials, we choose to consider albedo, roughness, metalness, and bump maps. For albedo and bump maps, we leverage Stable Diffusion fine-tuned on synthetic data to extract these values, with novel usages of these fine-tuned models to obtain 3D consistent albedo UV and bump UV for generated objects. In terms of roughness and metalness maps, we adopt a semi-automatic process to provide room for interactive adjustment, which we believe is more practical. Extensive experiments demonstrate that our model is generally beneficial for various state-of-the-art generation methods, significantly boosting the quality and realism of their generated 3D objects, with natural relighting effects and substantially improved geometry.
GaussianAnything: Interactive Point Cloud Latent Diffusion for 3D Generation
Nov 12, 2024



While 3D content generation has advanced significantly, existing methods still face challenges with input formats, latent space design, and output representations. This paper introduces a novel 3D generation framework that addresses these challenges, offering scalable, high-quality 3D generation with an interactive Point Cloud-structured Latent space. Our framework employs a Variational Autoencoder (VAE) with multi-view posed RGB-D(epth)-N(ormal) renderings as input, using a unique latent space design that preserves 3D shape information, and incorporates a cascaded latent diffusion model for improved shape-texture disentanglement. The proposed method, GaussianAnything, supports multi-modal conditional 3D generation, allowing for point cloud, caption, and single/multi-view image inputs. Notably, the newly proposed latent space naturally enables geometry-texture disentanglement, thus allowing 3D-aware editing. Experimental results demonstrate the effectiveness of our approach on multiple datasets, outperforming existing methods in both text- and image-conditioned 3D generation.
Matryoshka: Learning to Drive Black-Box LLMs with LLMs
Oct 28, 2024Despite the impressive generative abilities of black-box large language models (LLMs), their inherent opacity hinders further advancements in capabilities such as reasoning, planning, and personalization. Existing works aim to enhance LLM capabilities via domain-specific adaptation or in-context learning, which require additional training on accessible model parameters, an infeasible option for black-box LLMs. To address this challenge, we introduce Matryoshika, a lightweight white-box LLM controller that guides a large-scale black-box LLM generator by decomposing complex tasks into a series of intermediate outputs. Specifically, we consider the black-box LLM as an environment, with Matryoshika serving as a policy to provide intermediate guidance through prompts for driving the black-box LLM. Matryoshika is trained to pivot the outputs of the black-box LLM aligning with preferences during iterative interaction, which enables controllable multi-turn generation and self-improvement in optimizing intermediate guidance. Empirical evaluations on three diverse tasks demonstrate that Matryoshika effectively enhances the capabilities of black-box LLMs in complex, long-horizon tasks, including reasoning, planning, and personalization. By leveraging this pioneering controller-generator framework to mitigate dependence on model parameters, Matryoshika provides a transparent and practical solution for improving black-box LLMs through controllable multi-turn generation using white-box LLMs.
Faster WIND: Accelerating Iterative Best-of-$N$ Distillation for LLM Alignment
Oct 28, 2024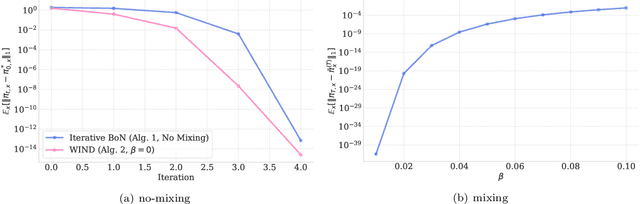
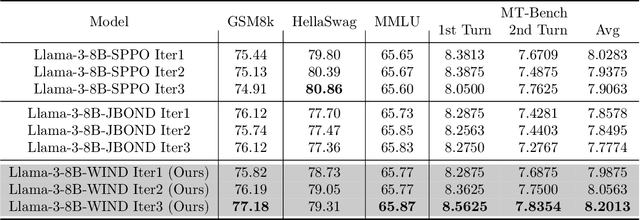
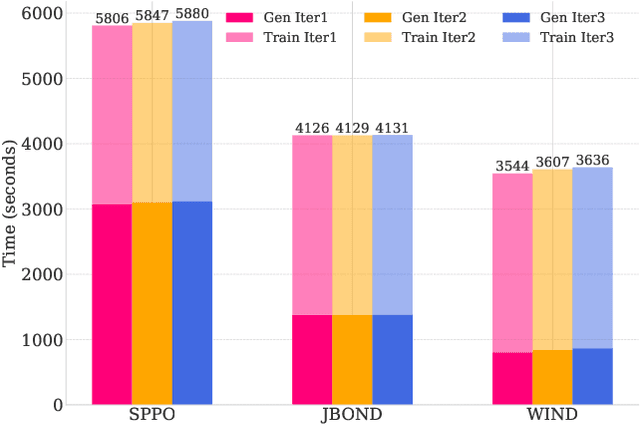
Recent advances in aligning large language models with human preferences have corroborated the growing importance of best-of-N distillation (BOND). However, the iterative BOND algorithm is prohibitively expensive in practice due to the sample and computation inefficiency. This paper addresses the problem by revealing a unified game-theoretic connection between iterative BOND and self-play alignment, which unifies seemingly disparate algorithmic paradigms. Based on the connection, we establish a novel framework, WIN rate Dominance (WIND), with a series of efficient algorithms for regularized win rate dominance optimization that approximates iterative BOND in the parameter space. We provides provable sample efficiency guarantee for one of the WIND variant with the square loss objective. The experimental results confirm that our algorithm not only accelerates the computation, but also achieves superior sample efficiency compared to existing methods.
Primal-Dual Spectral Representation for Off-policy Evaluation
Oct 23, 2024



Off-policy evaluation (OPE) is one of the most fundamental problems in reinforcement learning (RL) to estimate the expected long-term payoff of a given target policy with only experiences from another behavior policy that is potentially unknown. The distribution correction estimation (DICE) family of estimators have advanced the state of the art in OPE by breaking the curse of horizon. However, the major bottleneck of applying DICE estimators lies in the difficulty of solving the saddle-point optimization involved, especially with neural network implementations. In this paper, we tackle this challenge by establishing a linear representation of value function and stationary distribution correction ratio, i.e., primal and dual variables in the DICE framework, using the spectral decomposition of the transition operator. Such primal-dual representation not only bypasses the non-convex non-concave optimization in vanilla DICE, therefore enabling an computational efficient algorithm, but also paves the way for more efficient utilization of historical data. We highlight that our algorithm, SpectralDICE, is the first to leverage the linear representation of primal-dual variables that is both computation and sample efficient, the performance of which is supported by a rigorous theoretical sample complexity guarantee and a thorough empirical evaluation on various benchmarks.
Scalable spectral representations for network multiagent control
Oct 22, 2024



Network Markov Decision Processes (MDPs), a popular model for multi-agent control, pose a significant challenge to efficient learning due to the exponential growth of the global state-action space with the number of agents. In this work, utilizing the exponential decay property of network dynamics, we first derive scalable spectral local representations for network MDPs, which induces a network linear subspace for the local $Q$-function of each agent. Building on these local spectral representations, we design a scalable algorithmic framework for continuous state-action network MDPs, and provide end-to-end guarantees for the convergence of our algorithm. Empirically, we validate the effectiveness of our scalable representation-based approach on two benchmark problems, and demonstrate the advantages of our approach over generic function approximation approaches to representing the local $Q$-functions.
VideoAgent: Self-Improving Video Generation
Oct 15, 2024



Video generation has been used to generate visual plans for controlling robotic systems. Given an image observation and a language instruction, previous work has generated video plans which are then converted to robot controls to be executed. However, a major bottleneck in leveraging video generation for control lies in the quality of the generated videos, which often suffer from hallucinatory content and unrealistic physics, resulting in low task success when control actions are extracted from the generated videos. While scaling up dataset and model size provides a partial solution, integrating external feedback is both natural and essential for grounding video generation in the real world. With this observation, we propose VideoAgent for self-improving generated video plans based on external feedback. Instead of directly executing the generated video plan, VideoAgent first refines the generated video plans using a novel procedure which we call self-conditioning consistency, utilizing feedback from a pretrained vision-language model (VLM). As the refined video plan is being executed, VideoAgent collects additional data from the environment to further improve video plan generation. Experiments in simulated robotic manipulation from MetaWorld and iTHOR show that VideoAgent drastically reduces hallucination, thereby boosting success rate of downstream manipulation tasks. We further illustrate that VideoAgent can effectively refine real-robot videos, providing an early indicator that robotics can be an effective tool in grounding video generation in the physical world.
Scaling Laws For Diffusion Transformers
Oct 10, 2024



Diffusion transformers (DiT) have already achieved appealing synthesis and scaling properties in content recreation, e.g., image and video generation. However, scaling laws of DiT are less explored, which usually offer precise predictions regarding optimal model size and data requirements given a specific compute budget. Therefore, experiments across a broad range of compute budgets, from 1e17 to 6e18 FLOPs are conducted to confirm the existence of scaling laws in DiT for the first time. Concretely, the loss of pretraining DiT also follows a power-law relationship with the involved compute. Based on the scaling law, we can not only determine the optimal model size and required data but also accurately predict the text-to-image generation loss given a model with 1B parameters and a compute budget of 1e21 FLOPs. Additionally, we also demonstrate that the trend of pre-training loss matches the generation performances (e.g., FID), even across various datasets, which complements the mapping from compute to synthesis quality and thus provides a predictable benchmark that assesses model performance and data quality at a reduced cost.