 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeynman: Knowledge-Infused Diagramming Agent for Scalable Visual Designs
Mar 13, 2026Visual design is an essential application of state-of-the-art multi-modal AI systems. Improving these systems requires high-quality vision-language data at scale. Despite the abundance of internet image and text data, knowledge-rich and well-aligned image-text pairs are rare. In this paper, we present a scalable diagram generation pipeline built with our agent, Feynman. To create diagrams, Feynman first enumerates domain-specific knowledge components (''ideas'') and performs code planning based on the ideas. Given the plan, Feynman translates ideas into simple declarative programs and iterates to receives feedback and visually refine diagrams. Finally, the declarative programs are rendered by the Penrose diagramming system. The optimization-based rendering of Penrose preserves the visual semantics while injecting fresh randomness into the layout, thereby producing diagrams with visual consistency and diversity. As a result, Feynman can author diagrams along with grounded captions with very little cost and time. Using Feynman, we synthesized a dataset with more than 100k well-aligned diagram-caption pairs. We also curate a visual-language benchmark, Diagramma, from freshly generated data. Diagramma can be used for evaluating the visual reasoning capabilities of vision-language models. We plan to release the dataset, benchmark, and the full agent pipeline as an open-source project.
Learn Hard Problems During RL with Reference Guided Fine-tuning
Mar 05, 2026Reinforcement learning (RL) for mathematical reasoning can suffer from reward sparsity: for challenging problems, LLM fails to sample any correct trajectories, preventing RL from receiving meaningful positive feedback. At the same time, there often exist human-written reference solutions along with the problem (e.g., problems from AoPS), but directly fine-tuning on these solutions offers no benefit because models often cannot imitate human proofs that lie outside their own reasoning distribution. We introduce Reference-Guided Fine-Tuning (ReGFT), a simple and effective method that utilizes human-written reference solutions to synthesize positive trajectories on hard problems and train on them before RL. For each problem, we provide the model with a partial reference solution and let it generate its own reasoning trace, ensuring the resulting trajectories remain in the model's reasoning space while still benefiting from reference guidance. Fine-tuning on these reference-guided trajectories increases the number of solvable problems and produces a checkpoint that receives more positive rewards during RL. Across three benchmarks (AIME24, AIME25, BeyondAIME), ReGFT consistently improves supervised accuracy, accelerates DAPO training, and raises the final performance plateau of RL. Our results show that ReGFT effectively overcomes reward sparsity and unlocks stronger RL-based mathematical reasoning.
On the Learning Dynamics of RLVR at the Edge of Competence
Feb 16, 2026Reinforcement learning with verifiable rewards (RLVR) has been a main driver of recent breakthroughs in large reasoning models. Yet it remains a mystery how rewards based solely on final outcomes can help overcome the long-horizon barrier to extended reasoning. To understand this, we develop a theory of the training dynamics of RL for transformers on compositional reasoning tasks. Our theory characterizes how the effectiveness of RLVR is governed by the smoothness of the difficulty spectrum. When data contains abrupt discontinuities in difficulty, learning undergoes grokking-type phase transitions, producing prolonged plateaus before progress recurs. In contrast, a smooth difficulty spectrum leads to a relay effect: persistent gradient signals on easier problems elevate the model's capabilities to the point where harder ones become tractable, resulting in steady and continuous improvement. Our theory explains how RLVR can improve performance at the edge of competence, and suggests that appropriately designed data mixtures can yield scalable gains. As a technical contribution, our analysis develops and adapts tools from Fourier analysis on finite groups to our setting. We validate the predicted mechanisms empirically via synthetic experiments.
Transformers Provably Learn Chain-of-Thought Reasoning with Length Generalization
Nov 10, 2025The ability to reason lies at the core of artificial intelligence (AI), and challenging problems usually call for deeper and longer reasoning to tackle. A crucial question about AI reasoning is whether models can extrapolate learned reasoning patterns to solve harder tasks with longer chain-of-thought (CoT). In this work, we present a theoretical analysis of transformers learning on synthetic state-tracking tasks with gradient descent. We mathematically prove how the algebraic structure of state-tracking problems governs the degree of extrapolation of the learned CoT. Specifically, our theory characterizes the length generalization of transformers through the mechanism of attention concentration, linking the retrieval robustness of the attention layer to the state-tracking task structure of long-context reasoning. Moreover, for transformers with limited reasoning length, we prove that a recursive self-training scheme can progressively extend the range of solvable problem lengths. To our knowledge, we provide the first optimization guarantee that constant-depth transformers provably learn $\mathsf{NC}^1$-complete problems with CoT, significantly going beyond prior art confined in $\mathsf{TC}^0$, unless the widely held conjecture $\mathsf{TC}^0 \neq \mathsf{NC}^1$ fails. Finally, we present a broad set of experiments supporting our theoretical results, confirming the length generalization behaviors and the mechanism of attention concentration.
Scaling Latent Reasoning via Looped Language Models
Oct 29, 2025



Modern LLMs are trained to "think" primarily via explicit text generation, such as chain-of-thought (CoT), which defers reasoning to post-training and under-leverages pre-training data. We present and open-source Ouro, named after the recursive Ouroboros, a family of pre-trained Looped Language Models (LoopLM) that instead build reasoning into the pre-training phase through (i) iterative computation in latent space, (ii) an entropy-regularized objective for learned depth allocation, and (iii) scaling to 7.7T tokens. Ouro 1.4B and 2.6B models enjoy superior performance that match the results of up to 12B SOTA LLMs across a wide range of benchmarks. Through controlled experiments, we show this advantage stems not from increased knowledge capacity, but from superior knowledge manipulation capabilities. We also show that LoopLM yields reasoning traces more aligned with final outputs than explicit CoT. We hope our results show the potential of LoopLM as a novel scaling direction in the reasoning era. Our model could be found in: http://ouro-llm.github.io.
Faster WIND: Accelerating Iterative Best-of-$N$ Distillation for LLM Alignment
Oct 28, 2024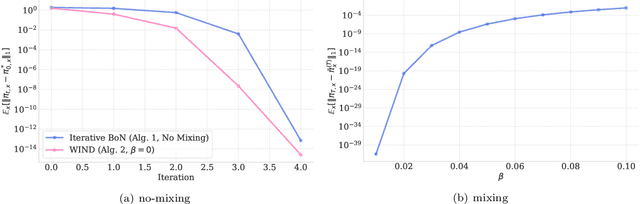
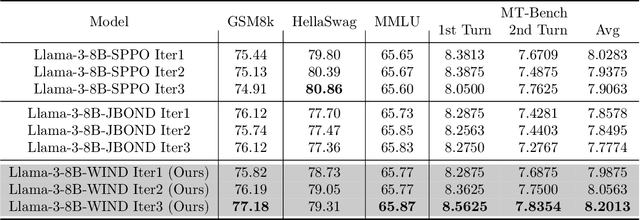
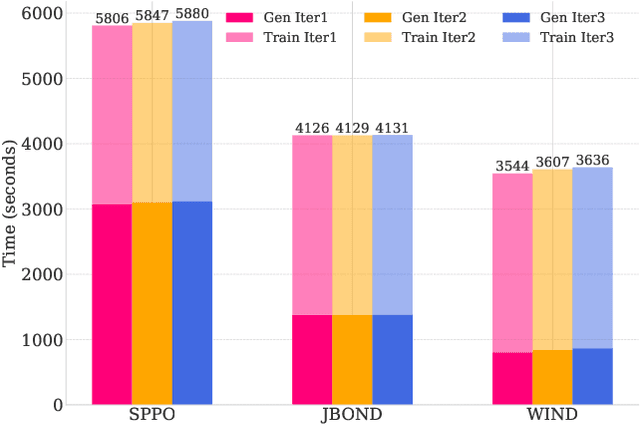
Recent advances in aligning large language models with human preferences have corroborated the growing importance of best-of-N distillation (BOND). However, the iterative BOND algorithm is prohibitively expensive in practice due to the sample and computation inefficiency. This paper addresses the problem by revealing a unified game-theoretic connection between iterative BOND and self-play alignment, which unifies seemingly disparate algorithmic paradigms. Based on the connection, we establish a novel framework, WIN rate Dominance (WIND), with a series of efficient algorithms for regularized win rate dominance optimization that approximates iterative BOND in the parameter space. We provides provable sample efficiency guarantee for one of the WIND variant with the square loss objective. The experimental results confirm that our algorithm not only accelerates the computation, but also achieves superior sample efficiency compared to existing methods.
Transformers Provably Learn Feature-Position Correlations in Masked Image Modeling
Mar 04, 2024



Masked image modeling (MIM), which predicts randomly masked patches from unmasked ones, has emerged as a promising approach in self-supervised vision pretraining. However, the theoretical understanding of MIM is rather limited, especially with the foundational architecture of transformers. In this paper, to the best of our knowledge, we provide the first end-to-end theory of learning one-layer transformers with softmax attention in MIM self-supervised pretraining. On the conceptual side, we posit a theoretical mechanism of how transformers, pretrained with MIM, produce empirically observed local and diverse attention patterns on data distributions with spatial structures that highlight feature-position correlations. On the technical side, our end-to-end analysis of the training dynamics of softmax-based transformers accommodates both input and position embeddings simultaneously, which is developed based on a novel approach to track the interplay between the attention of feature-position and position-wise correlations.
Revisiting Disentanglement in Downstream Tasks: A Study on Its Necessity for Abstract Visual Reasoning
Mar 01, 2024



In representation learning, a disentangled representation is highly desirable as it encodes generative factors of data in a separable and compact pattern. Researchers have advocated leveraging disentangled representations to complete downstream tasks with encouraging empirical evidence. This paper further investigates the necessity of disentangled representation in downstream applications. Specifically, we show that dimension-wise disentangled representations are unnecessary on a fundamental downstream task, abstract visual reasoning. We provide extensive empirical evidence against the necessity of disentanglement, covering multiple datasets, representation learning methods, and downstream network architectures. Furthermore, our findings suggest that the informativeness of representations is a better indicator of downstream performance than disentanglement. Finally, the positive correlation between informativeness and disentanglement explains the claimed usefulness of disentangled representations in previous works. The source code is available at https://github.com/Richard-coder-Nai/disentanglement-lib-necessity.git.
What Matters In The Structured Pruning of Generative Language Models?
Feb 07, 2023



Auto-regressive large language models such as GPT-3 require enormous computational resources to use. Traditionally, structured pruning methods are employed to reduce resource usage. However, their application to and efficacy for generative language models is heavily under-explored. In this paper we conduct an comprehensive evaluation of common structured pruning methods, including magnitude, random, and movement pruning on the feed-forward layers in GPT-type models. Unexpectedly, random pruning results in performance that is comparable to the best established methods, across multiple natural language generation tasks. To understand these results, we provide a framework for measuring neuron-level redundancy of models pruned by different methods, and discover that established structured pruning methods do not take into account the distinctiveness of neurons, leaving behind excess redundancies. In view of this, we introduce Globally Unique Movement (GUM) to improve the uniqueness of neurons in pruned models. We then discuss the effects of our techniques on different redundancy metrics to explain the improved performance.
The Mechanism of Prediction Head in Non-contrastive Self-supervised Learning
May 14, 2022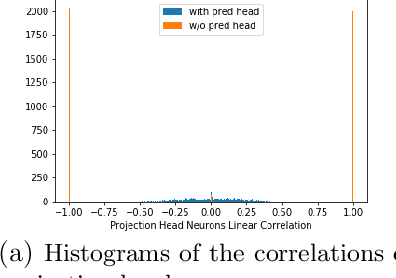
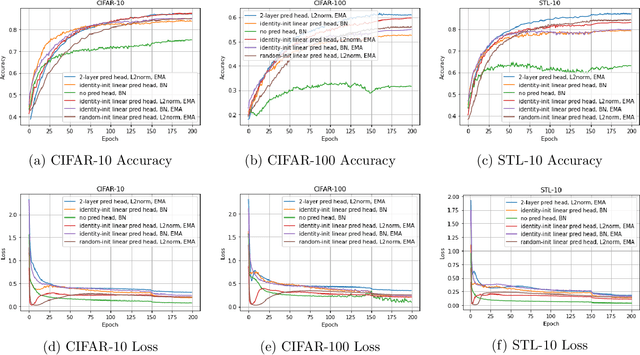
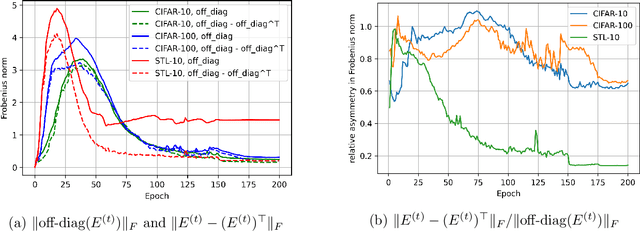
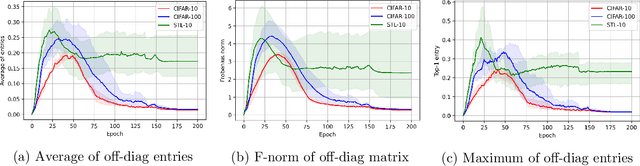
Recently the surprising discovery of the Bootstrap Your Own Latent (BYOL) method by Grill et al. shows the negative term in contrastive loss can be removed if we add the so-called prediction head to the network. This initiated the research of non-contrastive self-supervised learning. It is mysterious why even when there exist trivial collapsed global optimal solutions, neural networks trained by (stochastic) gradient descent can still learn competitive representations. This phenomenon is a typical example of implicit bias in deep learning and remains little understood. In this work, we present our empirical and theoretical discoveries on non-contrastive self-supervised learning. Empirically, we find that when the prediction head is initialized as an identity matrix with only its off-diagonal entries being trainable, the network can learn competitive representations even though the trivial optima still exist in the training objective. Theoretically, we present a framework to understand the behavior of the trainable, but identity-initialized prediction head. Under a simple setting, we characterized the substitution effect and acceleration effect of the prediction head. The substitution effect happens when learning the stronger features in some neurons can substitute for learning these features in other neurons through updating the prediction head. And the acceleration effect happens when the substituted features can accelerate the learning of other weaker features to prevent them from being ignored. These two effects enable the neural networks to learn all the features rather than focus only on learning the stronger features, which is likely the cause of the dimensional collapse phenomenon. To the best of our knowledge, this is also the first end-to-end optimization guarantee for non-contrastive methods using nonlinear neural networks with a trainable prediction head and normalization.