 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Fragments to Paths: Task-Level Context Recovery for Large Industrial Codebases
Jun 22, 2026Large language models have shown strong performance on software engineering (SE) tasks, yet understanding large industrial repositories remains challenging. Existing methods often retrieve only local fragments and fail to recover the broader task-relevant context needed for complex repository-level tasks. We present DeepDiscovery, a task-level repository-understanding method for large industrial codebases. DeepDiscovery uses a two-stage \textit{Location--Inference} framework to localize high-confidence task anchors and recover broader task-relevant context over multi-relational repository structure under budget constraints. Across controlled method-level evaluation, organization-internal industrial repository-understanding scenarios, and end-to-end evaluation on SWE-bench Verified, DeepDiscovery consistently improves task-relevant file recovery and downstream SE performance. On 27 medium-scale tasks, DeepDiscovery achieves the best file recovery quality among five representative baselines without offline preprocessing. On organization-internal industrial tasks from a production-scale integrated codebase ecosystem, including 27 medium-scale tasks and 40 large-scale tasks, DeepDiscovery improves Full Recall Rate across multiple AI coding systems, with absolute gains ranging from 1.6 to 9.2 percentage points on large subprojects and from 2.5 to 7.4 percentage points on medium-scale subprojects. In a controlled end-to-end evaluation on SWE-bench Verified, a system equipped with DeepDiscovery achieves a 78.6\% Solve Rate, outperforming the corresponding baseline by 8.2 percentage points. These results suggest that stronger task-level repository understanding can improve coding-agent performance on complex SE tasks.
Learning A Unified Risk Map for Autonomous Driving in Partially Observable Environments
May 21, 2026Occlusion-aware prediction remains a critical challenge in autonomous driving due to the inherent uncertainty of unobserved regions. Existing approaches either overestimate risk based on reachable states or struggle to predict accurate trajectories under high occlusion uncertainty. To address these limitations, we propose a unified risk map modeling and learning framework for partially observable environments. Our method integrates traffic flow risk and collision risk through spatiotemporal modeling, enabling fine-grained assessment of occlusion-induced hazards. To address the scarcity of scenarios involving occluded interactions, we introduce a diffusion-based scenario generation framework that produces realistic yet adversarial scenarios. We integrate the modeling and learning of a unified risk map into a framework that supports risk-aware planning under partial observability. Experiments on the Waymo Open Motion Dataset show that our method significantly outperforms the state-of-the-art occlusion-aware baseline, improving minimum time-to-collision by 0.78 times and average time-to-collision by 1.67 times. The proposed framework offers a comprehensive and practical solution for risk-aware planning in partially observable environments.
Learning Occlusion-aware Decision-making from Agent Interaction via Active Perception
Sep 26, 2024



Occlusion-aware decision-making is essential in autonomous driving due to the high uncertainty of various occlusions. Recent occlusion-aware decision-making methods encounter issues such as high computational complexity, scenario scalability challenges, or reliance on limited expert data. Benefiting from automatically generating data by exploration randomization, we uncover that reinforcement learning (RL) may show promise in occlusion-aware decision-making. However, previous occlusion-aware RL faces challenges in expanding to various dynamic and static occlusion scenarios, low learning efficiency, and lack of predictive ability. To address these issues, we introduce Pad-AI, a self-reinforcing framework to learn occlusion-aware decision-making through active perception. Pad-AI utilizes vectorized representation to represent occluded environments efficiently and learns over the semantic motion primitives to focus on high-level active perception exploration. Furthermore, Pad-AI integrates prediction and RL within a unified framework to provide risk-aware learning and security guarantees. Our framework was tested in challenging scenarios under both dynamic and static occlusions and demonstrated efficient and general perception-aware exploration performance to other strong baselines in closed-loop evaluations.
O2V-Mapping: Online Open-Vocabulary Mapping with Neural Implicit Representation
Apr 10, 2024



Online construction of open-ended language scenes is crucial for robotic applications, where open-vocabulary interactive scene understanding is required. Recently, neural implicit representation has provided a promising direction for online interactive mapping. However, implementing open-vocabulary scene understanding capability into online neural implicit mapping still faces three challenges: lack of local scene updating ability, blurry spatial hierarchical semantic segmentation and difficulty in maintaining multi-view consistency. To this end, we proposed O2V-mapping, which utilizes voxel-based language and geometric features to create an open-vocabulary field, thus allowing for local updates during online training process. Additionally, we leverage a foundational model for image segmentation to extract language features on object-level entities, achieving clear segmentation boundaries and hierarchical semantic features. For the purpose of preserving consistency in 3D object properties across different viewpoints, we propose a spatial adaptive voxel adjustment mechanism and a multi-view weight selection method. Extensive experiments on open-vocabulary object localization and semantic segmentation demonstrate that O2V-mapping achieves online construction of language scenes while enhancing accuracy, outperforming the previous SOTA method.
Improving Visual Speech Enhancement Network by Learning Audio-visual Affinity with Multi-head Attention
Jun 30, 2022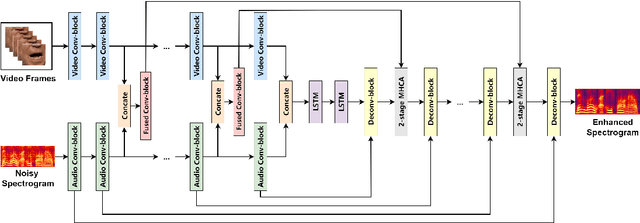
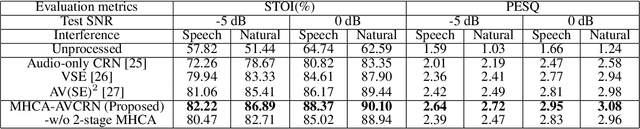
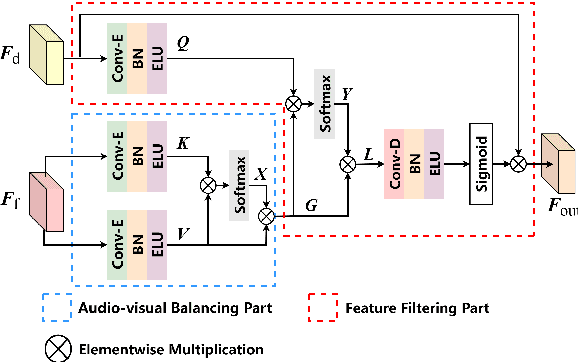

Audio-visual speech enhancement system is regarded as one of promising solutions for isolating and enhancing speech of desired speaker. Typical methods focus on predicting clean speech spectrum via a naive convolution neural network based encoder-decoder architecture, and these methods a) are not adequate to use data fully, b) are unable to effectively balance audio-visual features. The proposed model alleviates these drawbacks by a) applying a model that fuses audio and visual features layer by layer in encoding phase, and that feeds fused audio-visual features to each corresponding decoder layer, and more importantly, b) introducing a 2-stage multi-head cross attention (MHCA) mechanism to infer audio-visual speech enhancement for balancing the fused audio-visual features and eliminating irrelevant features. This paper proposes attentional audio-visual multi-layer feature fusion model, in which MHCA units are applied to feature mapping at every layer of decoder. The proposed model demonstrates the superior performance of the network against the state-of-the-art models.
GLD-Net: Improving Monaural Speech Enhancement by Learning Global and Local Dependency Features with GLD Block
Jun 30, 2022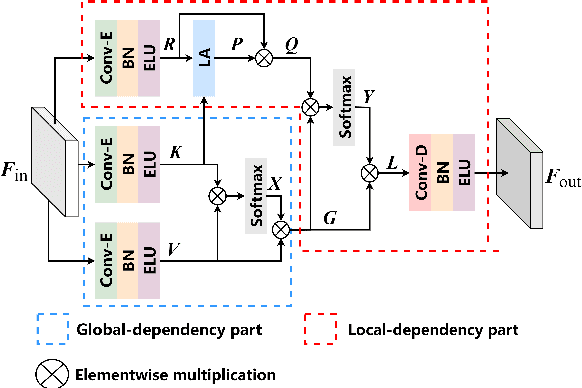
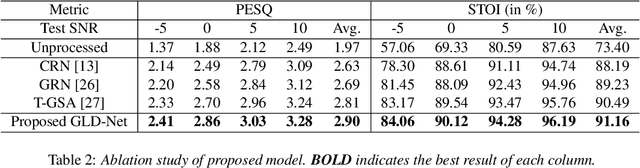
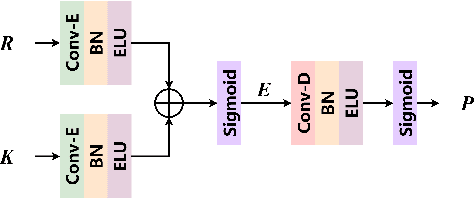

For monaural speech enhancement, contextual information is important for accurate speech estimation. However, commonly used convolution neural networks (CNNs) are weak in capturing temporal contexts since they only build blocks that process one local neighborhood at a time. To address this problem, we learn from human auditory perception to introduce a two-stage trainable reasoning mechanism, referred as global-local dependency (GLD) block. GLD blocks capture long-term dependency of time-frequency bins both in global level and local level from the noisy spectrogram to help detecting correlations among speech part, noise part, and whole noisy input. What is more, we conduct a monaural speech enhancement network called GLD-Net, which adopts encoder-decoder architecture and consists of speech object branch, interference branch, and global noisy branch. The extracted speech feature at global-level and local-level are efficiently reasoned and aggregated in each of the branches. We compare the proposed GLD-Net with existing state-of-art methods on WSJ0 and DEMAND dataset. The results show that GLD-Net outperforms the state-of-the-art methods in terms of PESQ and STOI.
Indoor Localization Using Smartphone Magnetic with Multi-Scale TCN and LSTM
Sep 24, 2021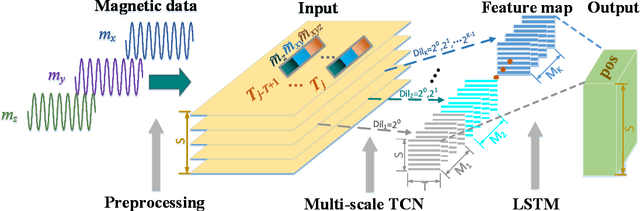
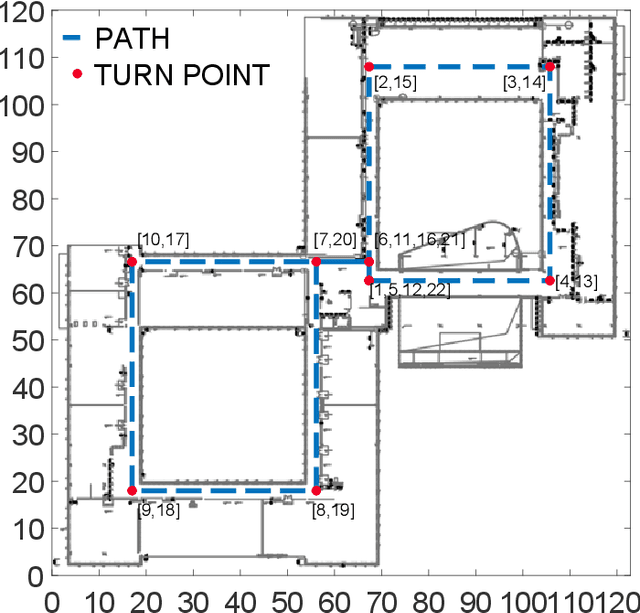
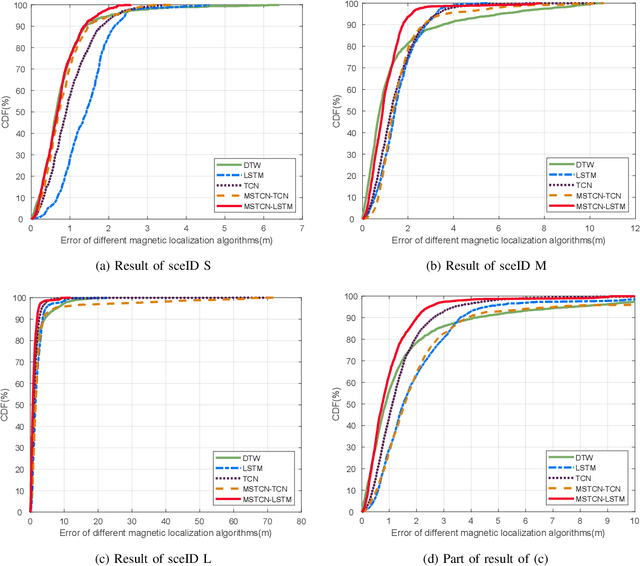
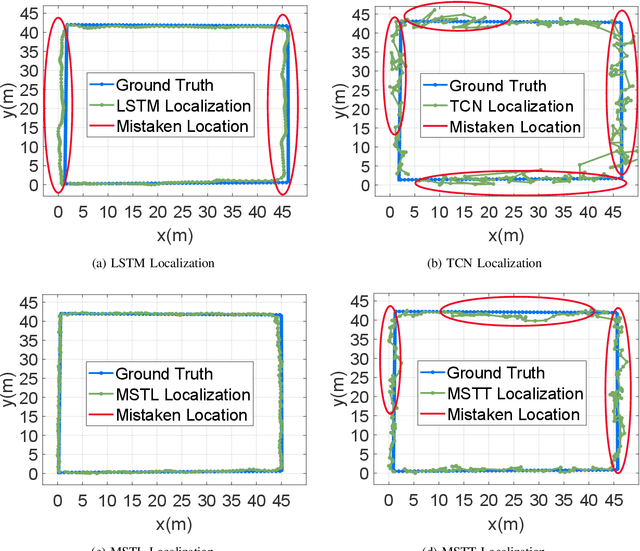
A novel multi-scale temporal convolutional network (TCN) and long short-term memory network (LSTM) based magnetic localization approach is proposed. To enhance the discernibility of geomagnetic signals, the time-series preprocessing approach is constructed at first. Next, the TCN is invoked to expand the feature dimensions on the basis of keeping the time-series characteristics of LSTM model. Then, a multi-scale time-series layer is constructed with multiple TCNs of different dilation factors to address the problem of inconsistent time-series speed between localization model and mobile users. A stacking framework of multi-scale TCN and LSTM is eventually proposed for indoor magnetic localization. Experiment results demonstrate the effectiveness of the proposed algorithm in indoor localization.
VSEGAN: Visual Speech Enhancement Generative Adversarial Network
Feb 04, 2021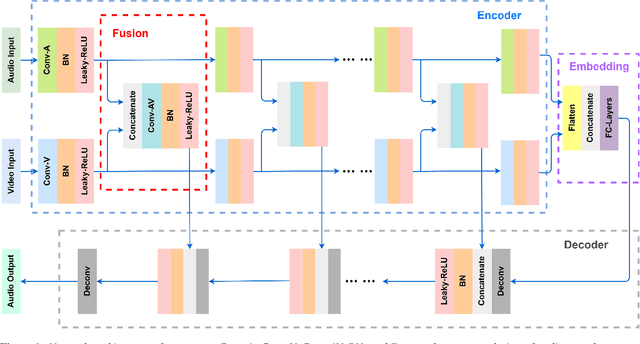

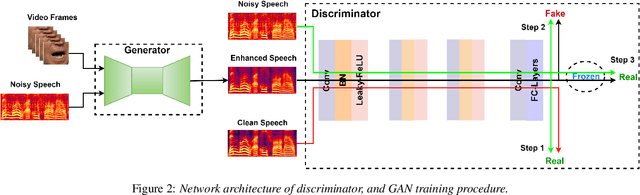
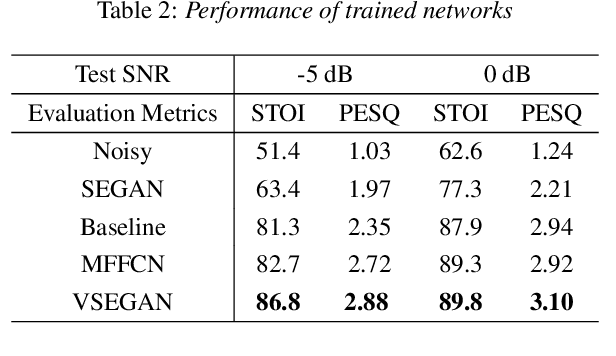
Speech enhancement is an essential task of improving speech quality in noise scenario. Several state-of-the-art approaches have introduced visual information for speech enhancement,since the visual aspect of speech is essentially unaffected by acoustic environment. This paper proposes a novel frameworkthat involves visual information for speech enhancement, by in-corporating a Generative Adversarial Network (GAN). In par-ticular, the proposed visual speech enhancement GAN consistof two networks trained in adversarial manner, i) a generator that adopts multi-layer feature fusion convolution network to enhance input noisy speech, and ii) a discriminator that attemptsto minimize the discrepancy between the distributions of the clean speech signal and enhanced speech signal. Experiment re-sults demonstrated superior performance of the proposed modelagainst several state-of-the-art
AMFFCN: Attentional Multi-layer Feature Fusion Convolution Network for Audio-visual Speech Enhancement
Feb 04, 2021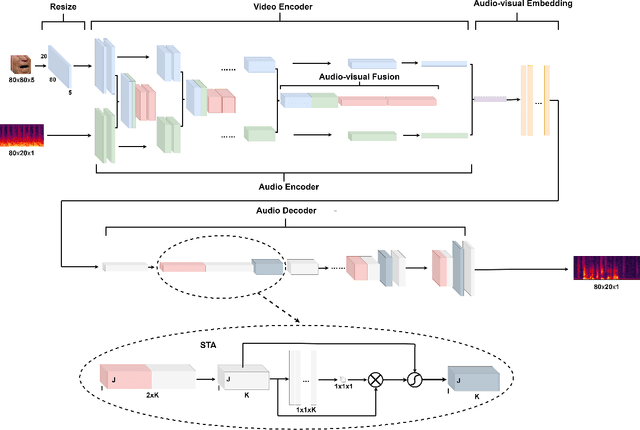
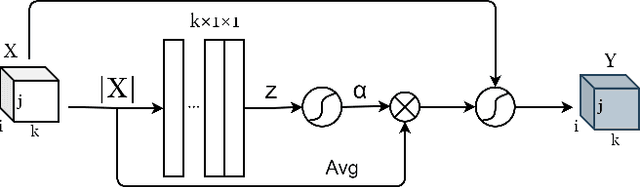
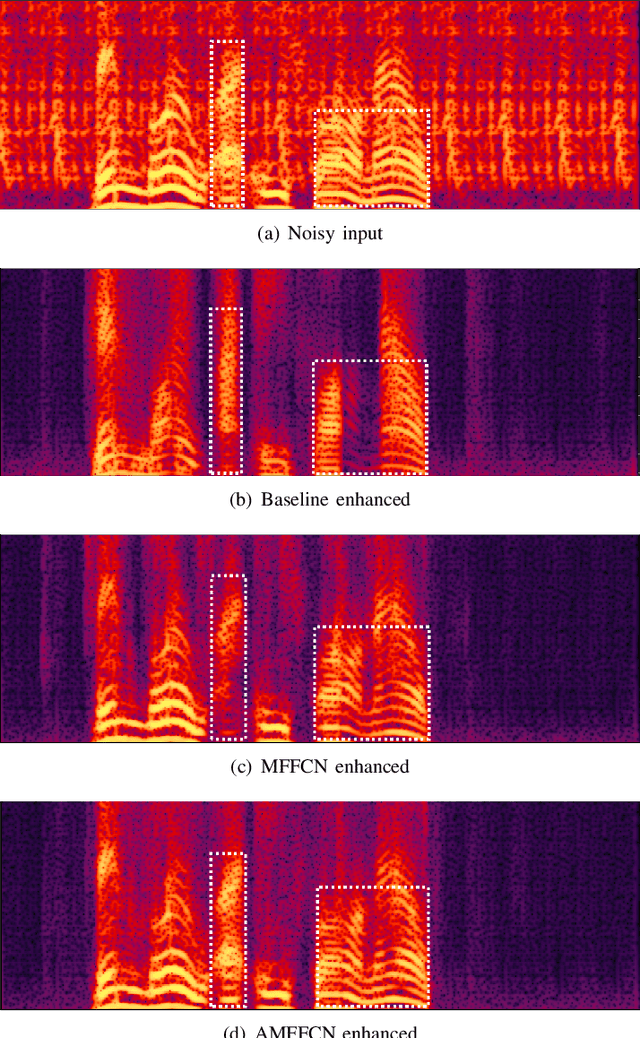
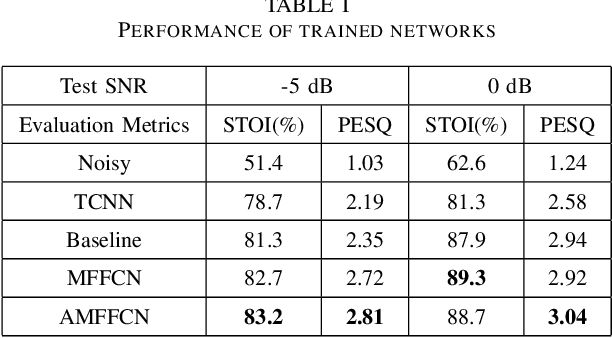
Audio-visual speech enhancement system is regarded to be one of promising solutions for isolating and enhancing speech of desired speaker. Conventional methods focus on predicting clean speech spectrum via a naive convolution neural network based encoder-decoder architecture, and these methods a) not adequate to use data fully and effectively, b) cannot process features selectively. The proposed model addresses these drawbacks, by a) applying a model that fuses audio and visual features layer by layer in encoding phase, and that feeds fused audio-visual features to each corresponding decoder layer, and more importantly, b) introducing soft threshold attention into the model to select the informative modality softly. This paper proposes attentional audio-visual multi-layer feature fusion model, in which soft threshold attention unit are applied on feature mapping at every layer of decoder. The proposed model demonstrates the superior performance of the network against the state-of-the-art models.
MFFCN: Multi-layer Feature Fusion Convolution Network for Audio-visual Speech Enhancement
Feb 04, 2021
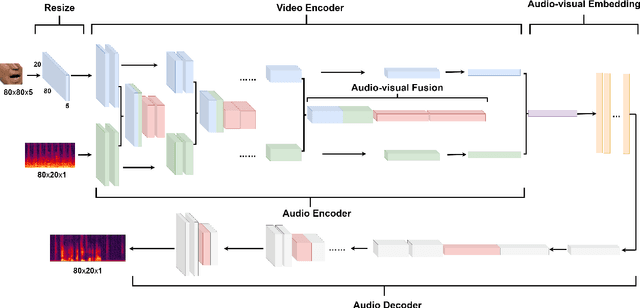
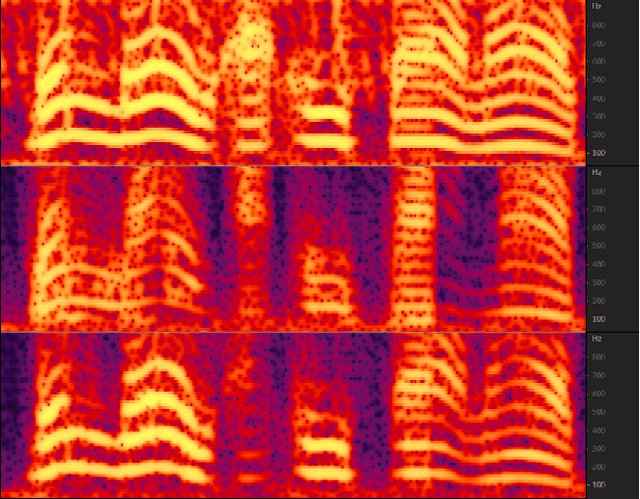
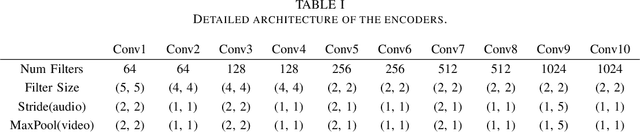
The purpose of speech enhancement is to extract target speech signal from a mixture of sounds generated from several sources. Speech enhancement can potentially benefit from the visual information from the target speaker, such as lip move-ment and facial expressions, because the visual aspect of speech isessentially unaffected by acoustic environment. In order to fuse audio and visual information, an audio-visual fusion strategy is proposed, which goes beyond simple feature concatenation and learns to automatically align the two modalities, leading to more powerful representation which increase intelligibility in noisy conditions. The proposed model fuses audio-visual featureslayer by layer, and feed these audio-visual features to each corresponding decoding layer. Experiment results show relative improvement from 6% to 24% on test sets over the audio modalityalone, depending on audio noise level. Moreover, there is a significant increase of PESQ from 1.21 to 2.06 in our -15 dB SNR experiment.