 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVSEGAN: Visual Speech Enhancement Generative Adversarial Network
Feb 04, 2021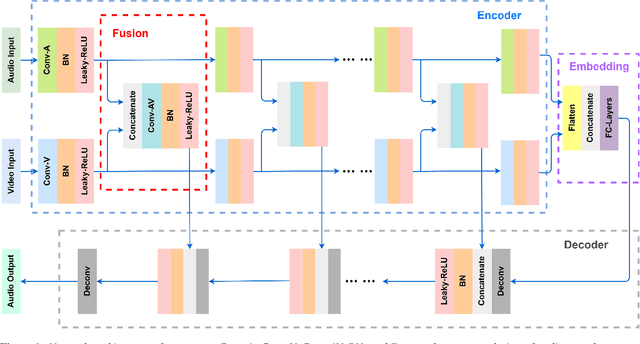

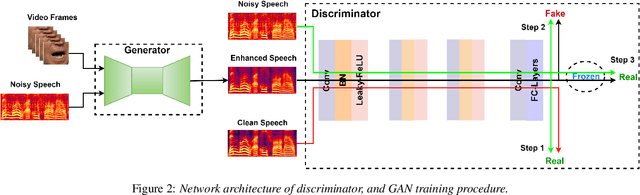
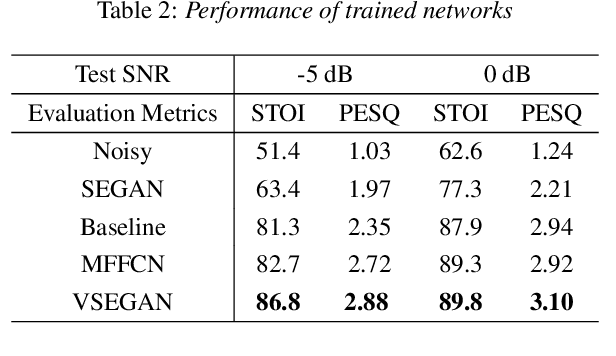
Speech enhancement is an essential task of improving speech quality in noise scenario. Several state-of-the-art approaches have introduced visual information for speech enhancement,since the visual aspect of speech is essentially unaffected by acoustic environment. This paper proposes a novel frameworkthat involves visual information for speech enhancement, by in-corporating a Generative Adversarial Network (GAN). In par-ticular, the proposed visual speech enhancement GAN consistof two networks trained in adversarial manner, i) a generator that adopts multi-layer feature fusion convolution network to enhance input noisy speech, and ii) a discriminator that attemptsto minimize the discrepancy between the distributions of the clean speech signal and enhanced speech signal. Experiment re-sults demonstrated superior performance of the proposed modelagainst several state-of-the-art
AMFFCN: Attentional Multi-layer Feature Fusion Convolution Network for Audio-visual Speech Enhancement
Feb 04, 2021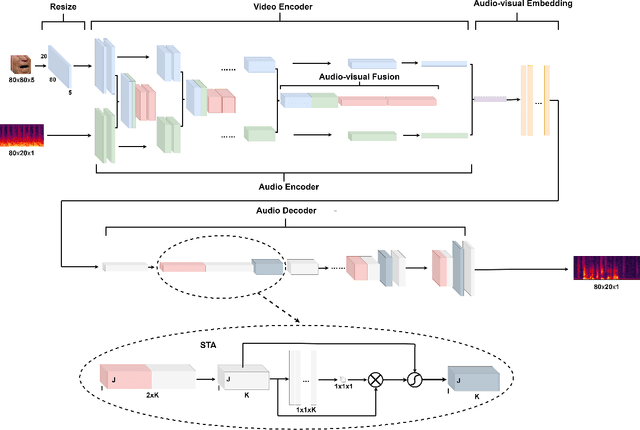
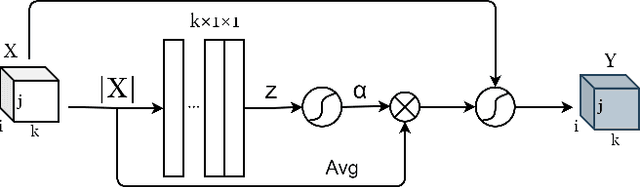
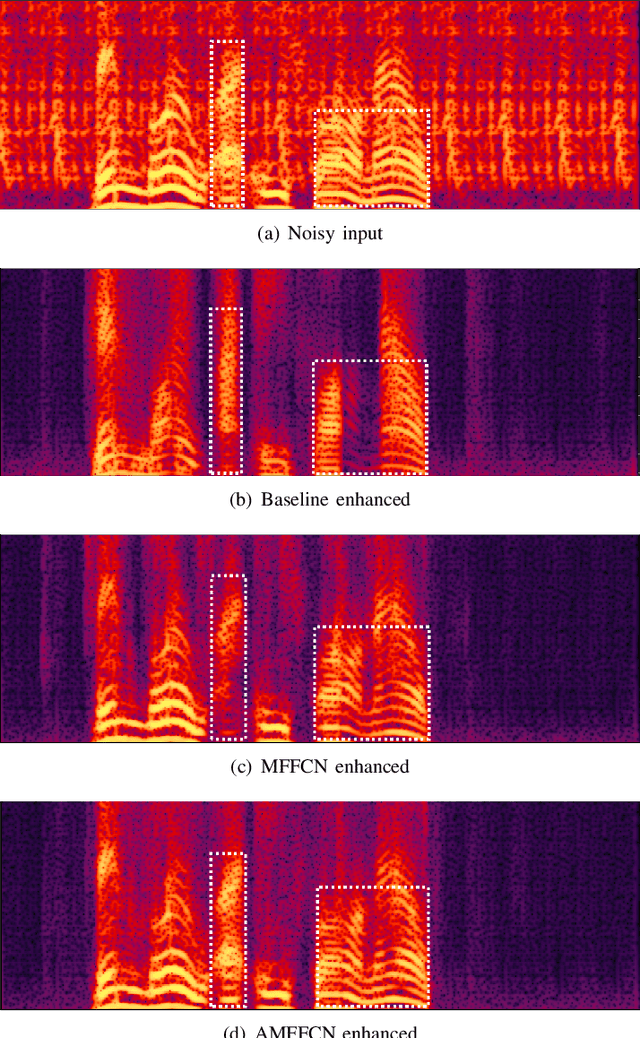
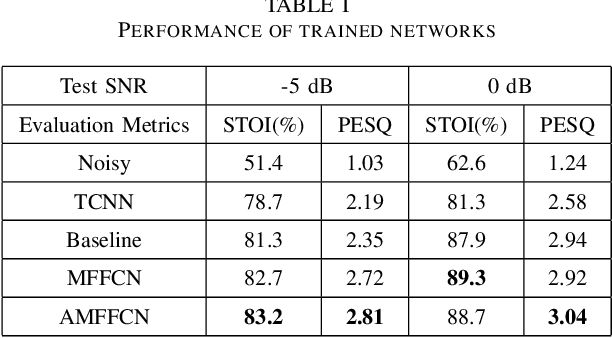
Audio-visual speech enhancement system is regarded to be one of promising solutions for isolating and enhancing speech of desired speaker. Conventional methods focus on predicting clean speech spectrum via a naive convolution neural network based encoder-decoder architecture, and these methods a) not adequate to use data fully and effectively, b) cannot process features selectively. The proposed model addresses these drawbacks, by a) applying a model that fuses audio and visual features layer by layer in encoding phase, and that feeds fused audio-visual features to each corresponding decoder layer, and more importantly, b) introducing soft threshold attention into the model to select the informative modality softly. This paper proposes attentional audio-visual multi-layer feature fusion model, in which soft threshold attention unit are applied on feature mapping at every layer of decoder. The proposed model demonstrates the superior performance of the network against the state-of-the-art models.
MFFCN: Multi-layer Feature Fusion Convolution Network for Audio-visual Speech Enhancement
Feb 04, 2021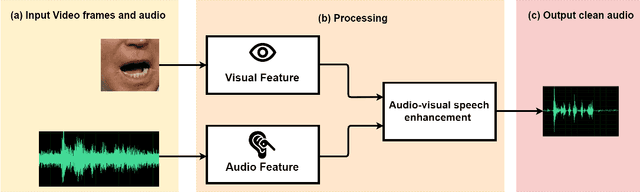
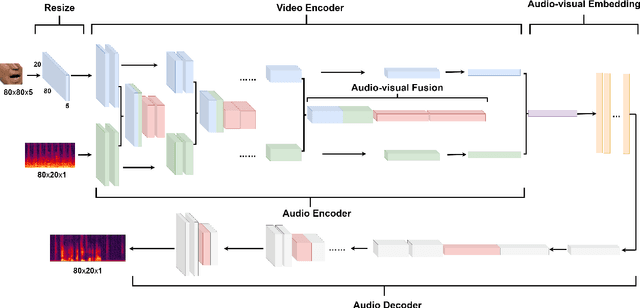
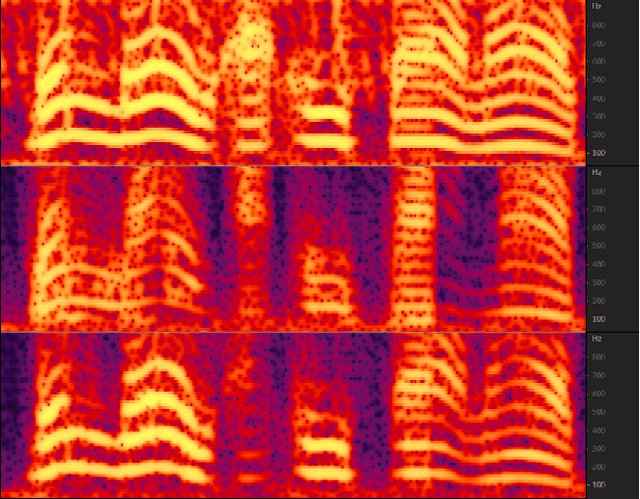
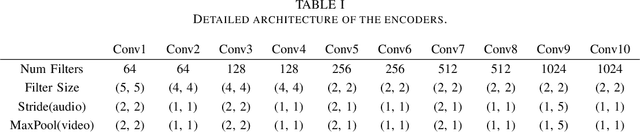
The purpose of speech enhancement is to extract target speech signal from a mixture of sounds generated from several sources. Speech enhancement can potentially benefit from the visual information from the target speaker, such as lip move-ment and facial expressions, because the visual aspect of speech isessentially unaffected by acoustic environment. In order to fuse audio and visual information, an audio-visual fusion strategy is proposed, which goes beyond simple feature concatenation and learns to automatically align the two modalities, leading to more powerful representation which increase intelligibility in noisy conditions. The proposed model fuses audio-visual featureslayer by layer, and feed these audio-visual features to each corresponding decoding layer. Experiment results show relative improvement from 6% to 24% on test sets over the audio modalityalone, depending on audio noise level. Moreover, there is a significant increase of PESQ from 1.21 to 2.06 in our -15 dB SNR experiment.