 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Masked Jigsaw Puzzle Framework for Vision and Language Models
Jan 17, 2026In federated learning, Transformer, as a popular architecture, faces critical challenges in defending against gradient attacks and improving model performance in both Computer Vision (CV) and Natural Language Processing (NLP) tasks. It has been revealed that the gradient of Position Embeddings (PEs) in Transformer contains sufficient information, which can be used to reconstruct the input data. To mitigate this issue, we introduce a Masked Jigsaw Puzzle (MJP) framework. MJP starts with random token shuffling to break the token order, and then a learnable \textit{unknown (unk)} position embedding is used to mask out the PEs of the shuffled tokens. In this manner, the local spatial information which is encoded in the position embeddings is disrupted, and the models are forced to learn feature representations that are less reliant on the local spatial information. Notably, with the careful use of MJP, we can not only improve models' robustness against gradient attacks, but also boost their performance in both vision and text application scenarios, such as classification for images (\textit{e.g.,} ImageNet-1K) and sentiment analysis for text (\textit{e.g.,} Yelp and Amazon). Experimental results suggest that MJP is a unified framework for different Transformer-based models in both vision and language tasks. Code is publicly available via https://github.com/ywxsuperstar/transformerattack
Residual Cross-Modal Fusion Networks for Audio-Visual Navigation
Jan 11, 2026Audio-visual embodied navigation aims to enable an agent to autonomously localize and reach a sound source in unseen 3D environments by leveraging auditory cues. The key challenge of this task lies in effectively modeling the interaction between heterogeneous features during multimodal fusion, so as to avoid single-modality dominance or information degradation, particularly in cross-domain scenarios. To address this, we propose a Cross-Modal Residual Fusion Network, which introduces bidirectional residual interactions between audio and visual streams to achieve complementary modeling and fine-grained alignment, while maintaining the independence of their representations. Unlike conventional methods that rely on simple concatenation or attention gating, CRFN explicitly models cross-modal interactions via residual connections and incorporates stabilization techniques to improve convergence and robustness. Experiments on the Replica and Matterport3D datasets demonstrate that CRFN significantly outperforms state-of-the-art fusion baselines and achieves stronger cross-domain generalization. Notably, our experiments also reveal that agents exhibit differentiated modality dependence across different datasets. The discovery of this phenomenon provides a new perspective for understanding the cross-modal collaboration mechanism of embodied agents.
Chorus: Multi-Teacher Pretraining for Holistic 3D Gaussian Scene Encoding
Dec 22, 2025While 3DGS has emerged as a high-fidelity scene representation, encoding rich, general-purpose features directly from its primitives remains under-explored. We address this gap by introducing Chorus, a multi-teacher pretraining framework that learns a holistic feed-forward 3D Gaussian Splatting (3DGS) scene encoder by distilling complementary signals from 2D foundation models. Chorus employs a shared 3D encoder and teacher-specific projectors to learn from language-aligned, generalist, and object-aware teachers, encouraging a shared embedding space that captures signals from high-level semantics to fine-grained structure. We evaluate Chorus on a wide range of tasks: open-vocabulary semantic and instance segmentation, linear and decoder probing, as well as data-efficient supervision. Besides 3DGS, we also test Chorus on several benchmarks that only support point clouds by pretraining a variant using only Gaussians' centers, colors, estimated normals as inputs. Interestingly, this encoder shows strong transfer and outperforms the point clouds baseline while using 39.9 times fewer training scenes. Finally, we propose a render-and-distill adaptation that facilitates out-of-domain finetuning. Our code and model will be released upon publication.
Multimodal Spatial Reasoning in the Large Model Era: A Survey and Benchmarks
Oct 29, 2025Humans possess spatial reasoning abilities that enable them to understand spaces through multimodal observations, such as vision and sound. Large multimodal reasoning models extend these abilities by learning to perceive and reason, showing promising performance across diverse spatial tasks. However, systematic reviews and publicly available benchmarks for these models remain limited. In this survey, we provide a comprehensive review of multimodal spatial reasoning tasks with large models, categorizing recent progress in multimodal large language models (MLLMs) and introducing open benchmarks for evaluation. We begin by outlining general spatial reasoning, focusing on post-training techniques, explainability, and architecture. Beyond classical 2D tasks, we examine spatial relationship reasoning, scene and layout understanding, as well as visual question answering and grounding in 3D space. We also review advances in embodied AI, including vision-language navigation and action models. Additionally, we consider emerging modalities such as audio and egocentric video, which contribute to novel spatial understanding through new sensors. We believe this survey establishes a solid foundation and offers insights into the growing field of multimodal spatial reasoning. Updated information about this survey, codes and implementation of the open benchmarks can be found at https://github.com/zhengxuJosh/Awesome-Spatial-Reasoning.
Are We Using the Right Benchmark: An Evaluation Framework for Visual Token Compression Methods
Oct 08, 2025Recent endeavors to accelerate inference in Multimodal Large Language Models (MLLMs) have primarily focused on visual token compression. The effectiveness of these methods is typically assessed by measuring the accuracy drop on established benchmarks, comparing model performance before and after compression. However, these benchmarks are originally designed to assess the perception and reasoning capabilities of MLLMs, rather than to evaluate compression techniques. As a result, directly applying them to visual token compression introduces a task mismatch. Strikingly, our investigation reveals that simple image downsampling consistently outperforms many advanced compression methods across multiple widely used benchmarks. Through extensive experiments, we make the following observations: (i) Current benchmarks are noisy for the visual token compression task. (ii) Down-sampling is able to serve as a data filter to evaluate the difficulty of samples in the visual token compression task. Motivated by these findings, we introduce VTC-Bench, an evaluation framework that incorporates a data filtering mechanism to denoise existing benchmarks, thereby enabling fairer and more accurate assessment of visual token compression methods. All data and code are available at https://github.com/Chenfei-Liao/VTC-Bench.
Masked Clustering Prediction for Unsupervised Point Cloud Pre-training
Aug 12, 2025



Vision transformers (ViTs) have recently been widely applied to 3D point cloud understanding, with masked autoencoding as the predominant pre-training paradigm. However, the challenge of learning dense and informative semantic features from point clouds via standard ViTs remains underexplored. We propose MaskClu, a novel unsupervised pre-training method for ViTs on 3D point clouds that integrates masked point modeling with clustering-based learning. MaskClu is designed to reconstruct both cluster assignments and cluster centers from masked point clouds, thus encouraging the model to capture dense semantic information. Additionally, we introduce a global contrastive learning mechanism that enhances instance-level feature learning by contrasting different masked views of the same point cloud. By jointly optimizing these complementary objectives, i.e., dense semantic reconstruction, and instance-level contrastive learning. MaskClu enables ViTs to learn richer and more semantically meaningful representations from 3D point clouds. We validate the effectiveness of our method via multiple 3D tasks, including part segmentation, semantic segmentation, object detection, and classification, where MaskClu sets new competitive results. The code and models will be released at:https://github.com/Amazingren/maskclu.
SceneSplat++: A Large Dataset and Comprehensive Benchmark for Language Gaussian Splatting
Jun 10, 20253D Gaussian Splatting (3DGS) serves as a highly performant and efficient encoding of scene geometry, appearance, and semantics. Moreover, grounding language in 3D scenes has proven to be an effective strategy for 3D scene understanding. Current Language Gaussian Splatting line of work fall into three main groups: (i) per-scene optimization-based, (ii) per-scene optimization-free, and (iii) generalizable approach. However, most of them are evaluated only on rendered 2D views of a handful of scenes and viewpoints close to the training views, limiting ability and insight into holistic 3D understanding. To address this gap, we propose the first large-scale benchmark that systematically assesses these three groups of methods directly in 3D space, evaluating on 1060 scenes across three indoor datasets and one outdoor dataset. Benchmark results demonstrate a clear advantage of the generalizable paradigm, particularly in relaxing the scene-specific limitation, enabling fast feed-forward inference on novel scenes, and achieving superior segmentation performance. We further introduce GaussianWorld-49K a carefully curated 3DGS dataset comprising around 49K diverse indoor and outdoor scenes obtained from multiple sources, with which we demonstrate the generalizable approach could harness strong data priors. Our codes, benchmark, and datasets will be made public to accelerate research in generalizable 3DGS scene understanding.
HiSin: Efficient High-Resolution Sinogram Inpainting via Resolution-Guided Progressive Inference
Jun 10, 2025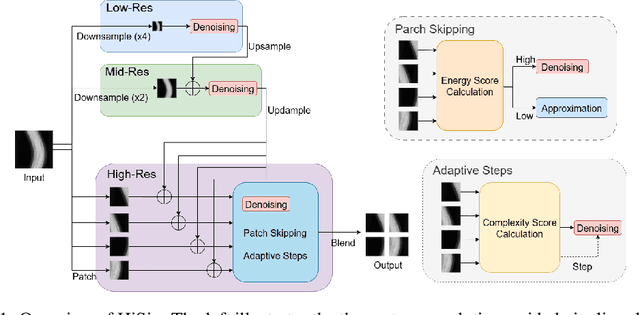
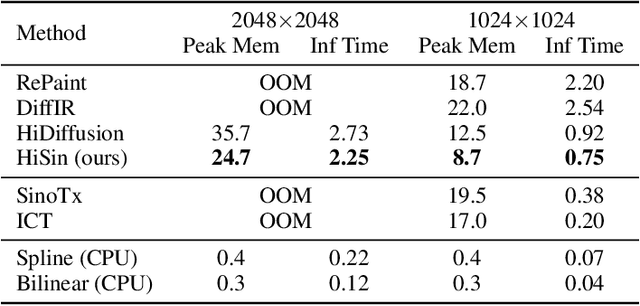
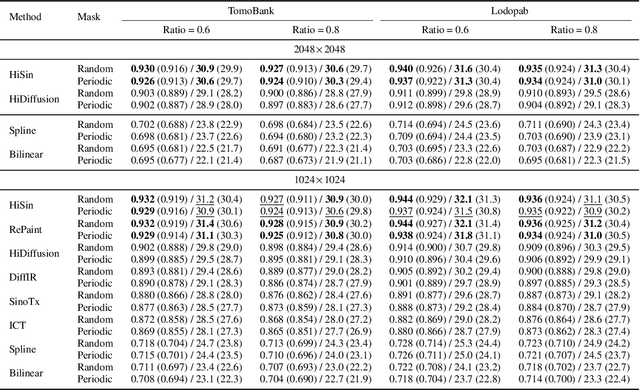
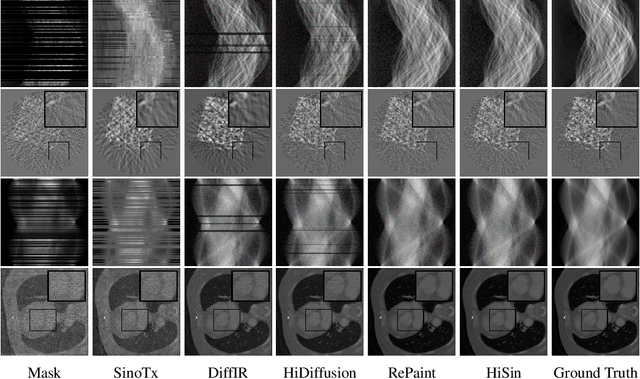
High-resolution sinogram inpainting is essential for computed tomography reconstruction, as missing high-frequency projections can lead to visible artifacts and diagnostic errors. Diffusion models are well-suited for this task due to their robustness and detail-preserving capabilities, but their application to high-resolution inputs is limited by excessive memory and computational demands. To address this limitation, we propose HiSin, a novel diffusion based framework for efficient sinogram inpainting via resolution-guided progressive inference. It progressively extracts global structure at low resolution and defers high-resolution inference to small patches, enabling memory-efficient inpainting. It further incorporates frequency-aware patch skipping and structure-adaptive step allocation to reduce redundant computation. Experimental results show that HiSin reduces peak memory usage by up to 31.25% and inference time by up to 18.15%, and maintains inpainting accuracy across datasets, resolutions, and mask conditions.
Inverse Virtual Try-On: Generating Multi-Category Product-Style Images from Clothed Individuals
May 27, 2025



While virtual try-on (VTON) systems aim to render a garment onto a target person image, this paper tackles the novel task of virtual try-off (VTOFF), which addresses the inverse problem: generating standardized product images of garments from real-world photos of clothed individuals. Unlike VTON, which must resolve diverse pose and style variations, VTOFF benefits from a consistent and well-defined output format -- typically a flat, lay-down-style representation of the garment -- making it a promising tool for data generation and dataset enhancement. However, existing VTOFF approaches face two major limitations: (i) difficulty in disentangling garment features from occlusions and complex poses, often leading to visual artifacts, and (ii) restricted applicability to single-category garments (e.g., upper-body clothes only), limiting generalization. To address these challenges, we present Text-Enhanced MUlti-category Virtual Try-Off (TEMU-VTOFF), a novel architecture featuring a dual DiT-based backbone with a modified multimodal attention mechanism for robust garment feature extraction. Our architecture is designed to receive garment information from multiple modalities like images, text, and masks to work in a multi-category setting. Finally, we propose an additional alignment module to further refine the generated visual details. Experiments on VITON-HD and Dress Code datasets show that TEMU-VTOFF sets a new state-of-the-art on the VTOFF task, significantly improving both visual quality and fidelity to the target garments.
Manifold-aware Representation Learning for Degradation-agnostic Image Restoration
May 24, 2025Image Restoration (IR) aims to recover high quality images from degraded inputs affected by various corruptions such as noise, blur, haze, rain, and low light conditions. Despite recent advances, most existing approaches treat IR as a direct mapping problem, relying on shared representations across degradation types without modeling their structural diversity. In this work, we present MIRAGE, a unified and lightweight framework for all in one IR that explicitly decomposes the input feature space into three semantically aligned parallel branches, each processed by a specialized module attention for global context, convolution for local textures, and MLP for channel-wise statistics. This modular decomposition significantly improves generalization and efficiency across diverse degradations. Furthermore, we introduce a cross layer contrastive learning scheme that aligns shallow and latent features to enhance the discriminability of shared representations. To better capture the underlying geometry of feature representations, we perform contrastive learning in a Symmetric Positive Definite (SPD) manifold space rather than the conventional Euclidean space. Extensive experiments show that MIRAGE not only achieves new state of the art performance across a variety of degradation types but also offers a scalable solution for challenging all-in-one IR scenarios. Our code and models will be publicly available at https://amazingren.github.io/MIRAGE/.