 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Deceive Me: Mitigating Gaslighting through Attention Reallocation in LMMs
Apr 13, 2025



Large Multimodal Models (LMMs) have demonstrated remarkable capabilities across a wide range of tasks. However, their vulnerability to user gaslighting-the deliberate use of misleading or contradictory inputs-raises critical concerns about their reliability in real-world applications. In this paper, we address the novel and challenging issue of mitigating the negative impact of negation-based gaslighting on LMMs, where deceptive user statements lead to significant drops in model accuracy. Specifically, we introduce GasEraser, a training-free approach that reallocates attention weights from misleading textual tokens to semantically salient visual regions. By suppressing the influence of "attention sink" tokens and enhancing focus on visually grounded cues, GasEraser significantly improves LMM robustness without requiring retraining or additional supervision. Extensive experimental results demonstrate that GasEraser is effective across several leading open-source LMMs on the GaslightingBench. Notably, for LLaVA-v1.5-7B, GasEraser reduces the misguidance rate by 48.2%, demonstrating its potential for more trustworthy LMMs.
Evaluating LLM-based Agents for Multi-Turn Conversations: A Survey
Mar 28, 2025This survey examines evaluation methods for large language model (LLM)-based agents in multi-turn conversational settings. Using a PRISMA-inspired framework, we systematically reviewed nearly 250 scholarly sources, capturing the state of the art from various venues of publication, and establishing a solid foundation for our analysis. Our study offers a structured approach by developing two interrelated taxonomy systems: one that defines \emph{what to evaluate} and another that explains \emph{how to evaluate}. The first taxonomy identifies key components of LLM-based agents for multi-turn conversations and their evaluation dimensions, including task completion, response quality, user experience, memory and context retention, as well as planning and tool integration. These components ensure that the performance of conversational agents is assessed in a holistic and meaningful manner. The second taxonomy system focuses on the evaluation methodologies. It categorizes approaches into annotation-based evaluations, automated metrics, hybrid strategies that combine human assessments with quantitative measures, and self-judging methods utilizing LLMs. This framework not only captures traditional metrics derived from language understanding, such as BLEU and ROUGE scores, but also incorporates advanced techniques that reflect the dynamic, interactive nature of multi-turn dialogues.
SwapAnyone: Consistent and Realistic Video Synthesis for Swapping Any Person into Any Video
Mar 12, 2025



Video body-swapping aims to replace the body in an existing video with a new body from arbitrary sources, which has garnered more attention in recent years. Existing methods treat video body-swapping as a composite of multiple tasks instead of an independent task and typically rely on various models to achieve video body-swapping sequentially. However, these methods fail to achieve end-to-end optimization for the video body-swapping which causes issues such as variations in luminance among frames, disorganized occlusion relationships, and the noticeable separation between bodies and background. In this work, we define video body-swapping as an independent task and propose three critical consistencies: identity consistency, motion consistency, and environment consistency. We introduce an end-to-end model named SwapAnyone, treating video body-swapping as a video inpainting task with reference fidelity and motion control. To improve the ability to maintain environmental harmony, particularly luminance harmony in the resulting video, we introduce a novel EnvHarmony strategy for training our model progressively. Additionally, we provide a dataset named HumanAction-32K covering various videos about human actions. Extensive experiments demonstrate that our method achieves State-Of-The-Art (SOTA) performance among open-source methods while approaching or surpassing closed-source models across multiple dimensions. All code, model weights, and the HumanAction-32K dataset will be open-sourced at https://github.com/PKU-YuanGroup/SwapAnyone.
WISE: A World Knowledge-Informed Semantic Evaluation for Text-to-Image Generation
Mar 10, 2025Text-to-Image (T2I) models are capable of generating high-quality artistic creations and visual content. However, existing research and evaluation standards predominantly focus on image realism and shallow text-image alignment, lacking a comprehensive assessment of complex semantic understanding and world knowledge integration in text to image generation. To address this challenge, we propose $\textbf{WISE}$, the first benchmark specifically designed for $\textbf{W}$orld Knowledge-$\textbf{I}$nformed $\textbf{S}$emantic $\textbf{E}$valuation. WISE moves beyond simple word-pixel mapping by challenging models with 1000 meticulously crafted prompts across 25 sub-domains in cultural common sense, spatio-temporal reasoning, and natural science. To overcome the limitations of traditional CLIP metric, we introduce $\textbf{WiScore}$, a novel quantitative metric for assessing knowledge-image alignment. Through comprehensive testing of 20 models (10 dedicated T2I models and 10 unified multimodal models) using 1,000 structured prompts spanning 25 subdomains, our findings reveal significant limitations in their ability to effectively integrate and apply world knowledge during image generation, highlighting critical pathways for enhancing knowledge incorporation and application in next-generation T2I models. Code and data are available at https://github.com/PKU-YuanGroup/WISE.
OSCAR: Object Status and Contextual Awareness for Recipes to Support Non-Visual Cooking
Mar 07, 2025



Following recipes while cooking is an important but difficult task for visually impaired individuals. We developed OSCAR (Object Status Context Awareness for Recipes), a novel approach that provides recipe progress tracking and context-aware feedback on the completion of cooking tasks through tracking object statuses. OSCAR leverages both Large-Language Models (LLMs) and Vision-Language Models (VLMs) to manipulate recipe steps, extract object status information, align visual frames with object status, and provide cooking progress tracking log. We evaluated OSCAR's recipe following functionality using 173 YouTube cooking videos and 12 real-world non-visual cooking videos to demonstrate OSCAR's capability to track cooking steps and provide contextual guidance. Our results highlight the effectiveness of using object status to improve performance compared to baseline by over 20% across different VLMs, and we present factors that impact prediction performance. Furthermore, we contribute a dataset of real-world non-visual cooking videos with step annotations as an evaluation benchmark.
HD-EPIC: A Highly-Detailed Egocentric Video Dataset
Feb 06, 2025
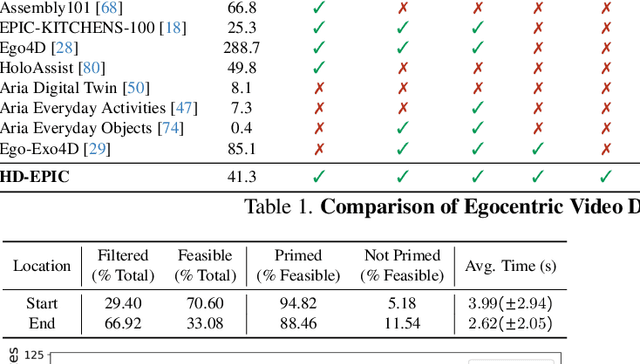


We present a validation dataset of newly-collected kitchen-based egocentric videos, manually annotated with highly detailed and interconnected ground-truth labels covering: recipe steps, fine-grained actions, ingredients with nutritional values, moving objects, and audio annotations. Importantly, all annotations are grounded in 3D through digital twinning of the scene, fixtures, object locations, and primed with gaze. Footage is collected from unscripted recordings in diverse home environments, making HDEPIC the first dataset collected in-the-wild but with detailed annotations matching those in controlled lab environments. We show the potential of our highly-detailed annotations through a challenging VQA benchmark of 26K questions assessing the capability to recognise recipes, ingredients, nutrition, fine-grained actions, 3D perception, object motion, and gaze direction. The powerful long-context Gemini Pro only achieves 38.5% on this benchmark, showcasing its difficulty and highlighting shortcomings in current VLMs. We additionally assess action recognition, sound recognition, and long-term video-object segmentation on HD-EPIC. HD-EPIC is 41 hours of video in 9 kitchens with digital twins of 413 kitchen fixtures, capturing 69 recipes, 59K fine-grained actions, 51K audio events, 20K object movements and 37K object masks lifted to 3D. On average, we have 263 annotations per minute of our unscripted videos.
Calling a Spade a Heart: Gaslighting Multimodal Large Language Models via Negation
Jan 31, 2025



Multimodal Large Language Models (MLLMs) have exhibited remarkable advancements in integrating different modalities, excelling in complex understanding and generation tasks. Despite their success, MLLMs remain vulnerable to conversational adversarial inputs, particularly negation arguments. This paper systematically evaluates state-of-the-art MLLMs across diverse benchmarks, revealing significant performance drops when negation arguments are introduced to initially correct responses. We show critical vulnerabilities in the reasoning and alignment mechanisms of these models. Proprietary models such as GPT-4o and Claude-3.5-Sonnet demonstrate better resilience compared to open-source counterparts like Qwen2-VL and LLaVA. However, all evaluated MLLMs struggle to maintain logical consistency under negation arguments during conversation. This paper aims to offer valuable insights for improving the robustness of MLLMs against adversarial inputs, contributing to the development of more reliable and trustworthy multimodal AI systems.
Next Patch Prediction for Autoregressive Visual Generation
Dec 19, 2024Autoregressive models, built based on the Next Token Prediction (NTP) paradigm, show great potential in developing a unified framework that integrates both language and vision tasks. In this work, we rethink the NTP for autoregressive image generation and propose a novel Next Patch Prediction (NPP) paradigm. Our key idea is to group and aggregate image tokens into patch tokens containing high information density. With patch tokens as a shorter input sequence, the autoregressive model is trained to predict the next patch, thereby significantly reducing the computational cost. We further propose a multi-scale coarse-to-fine patch grouping strategy that exploits the natural hierarchical property of image data. Experiments on a diverse range of models (100M-1.4B parameters) demonstrate that the next patch prediction paradigm could reduce the training cost to around 0.6 times while improving image generation quality by up to 1.0 FID score on the ImageNet benchmark. We highlight that our method retains the original autoregressive model architecture without introducing additional trainable parameters or specifically designing a custom image tokenizer, thus ensuring flexibility and seamless adaptation to various autoregressive models for visual generation.
DreamDance: Animating Human Images by Enriching 3D Geometry Cues from 2D Poses
Nov 30, 2024In this work, we present DreamDance, a novel method for animating human images using only skeleton pose sequences as conditional inputs. Existing approaches struggle with generating coherent, high-quality content in an efficient and user-friendly manner. Concretely, baseline methods relying on only 2D pose guidance lack the cues of 3D information, leading to suboptimal results, while methods using 3D representation as guidance achieve higher quality but involve a cumbersome and time-intensive process. To address these limitations, DreamDance enriches 3D geometry cues from 2D poses by introducing an efficient diffusion model, enabling high-quality human image animation with various guidance. Our key insight is that human images naturally exhibit multiple levels of correlation, progressing from coarse skeleton poses to fine-grained geometry cues, and further from these geometry cues to explicit appearance details. Capturing such correlations could enrich the guidance signals, facilitating intra-frame coherency and inter-frame consistency. Specifically, we construct the TikTok-Dance5K dataset, comprising 5K high-quality dance videos with detailed frame annotations, including human pose, depth, and normal maps. Next, we introduce a Mutually Aligned Geometry Diffusion Model to generate fine-grained depth and normal maps for enriched guidance. Finally, a Cross-domain Controller incorporates multi-level guidance to animate human images effectively with a video diffusion model. Extensive experiments demonstrate that our method achieves state-of-the-art performance in animating human images.
Open-Sora Plan: Open-Source Large Video Generation Model
Nov 28, 2024



We introduce Open-Sora Plan, an open-source project that aims to contribute a large generation model for generating desired high-resolution videos with long durations based on various user inputs. Our project comprises multiple components for the entire video generation process, including a Wavelet-Flow Variational Autoencoder, a Joint Image-Video Skiparse Denoiser, and various condition controllers. Moreover, many assistant strategies for efficient training and inference are designed, and a multi-dimensional data curation pipeline is proposed for obtaining desired high-quality data. Benefiting from efficient thoughts, our Open-Sora Plan achieves impressive video generation results in both qualitative and quantitative evaluations. We hope our careful design and practical experience can inspire the video generation research community. All our codes and model weights are publicly available at \url{https://github.com/PKU-YuanGroup/Open-Sora-Plan}.