 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVOPOSE: A Recursive Transformer For 3D Human Pose Estimation With Kinematic Structure Priors
Jun 16, 2023



Transformer is popular in recent 3D human pose estimation, which utilizes long-term modeling to lift 2D keypoints into the 3D space. However, current transformer-based methods do not fully exploit the prior knowledge of the human skeleton provided by the kinematic structure. In this paper, we propose a novel transformer-based model EvoPose to introduce the human body prior knowledge for 3D human pose estimation effectively. Specifically, a Structural Priors Representation (SPR) module represents human priors as structural features carrying rich body patterns, e.g. joint relationships. The structural features are interacted with 2D pose sequences and help the model to achieve more informative spatiotemporal features. Moreover, a Recursive Refinement (RR) module is applied to refine the 3D pose outputs by utilizing estimated results and further injects human priors simultaneously. Extensive experiments demonstrate the effectiveness of EvoPose which achieves a new state of the art on two most popular benchmarks, Human3.6M and MPI-INF-3DHP.
A Boosted Model Ensembling Approach to Ball Action Spotting in Videos: The Runner-Up Solution to CVPR'23 SoccerNet Challenge
Jun 12, 2023


This technical report presents our solution to Ball Action Spotting in videos. Our method reached second place in the CVPR'23 SoccerNet Challenge. Details of this challenge can be found at https://www.soccer-net.org/tasks/ball-action-spotting. Our approach is developed based on a baseline model termed E2E-Spot, which was provided by the organizer of this competition. We first generated several variants of the E2E-Spot model, resulting in a candidate model set. We then proposed a strategy for selecting appropriate model members from this set and assigning an appropriate weight to each model. The aim of this strategy is to boost the performance of the resulting model ensemble. Therefore, we call our approach Boosted Model Ensembling (BME). Our code is available at https://github.com/ZJLAB-AMMI/E2E-Spot-MBS.
Enabling Intelligent Interactions between an Agent and an LLM: A Reinforcement Learning Approach
Jun 11, 2023



Large language models (LLMs) encode a vast amount of world knowledge acquired from massive text datasets. Recent studies have demonstrated that LLMs can assist an agent in solving complex sequential decision making tasks in embodied environments by providing high-level instructions. However, interacting with LLMs can be time-consuming, as in many practical scenarios, they require a significant amount of storage space that can only be deployed on remote cloud server nodes. Additionally, using commercial LLMs can be costly since they may charge based on usage frequency. In this paper, we explore how to enable intelligent cost-effective interactions between the agent and an LLM. We propose a reinforcement learning based mediator model that determines when it is necessary to consult LLMs for high-level instructions to accomplish a target task. Experiments on 4 MiniGrid environments that entail planning sub-goals demonstrate that our method can learn to solve target tasks with only a few necessary interactions with an LLM, significantly reducing interaction costs in testing environments, compared with baseline methods. Experimental results also suggest that by learning a mediator model to interact with the LLM, the agent's performance becomes more robust against partial observability of the environment. Our code is available at https://github.com/ZJLAB-AMMI/LLM4RL.
Securing Visually-Aware Recommender Systems: An Adversarial Image Reconstruction and Detection Framework
Jun 11, 2023



With rich visual data, such as images, becoming readily associated with items, visually-aware recommendation systems (VARS) have been widely used in different applications. Recent studies have shown that VARS are vulnerable to item-image adversarial attacks, which add human-imperceptible perturbations to the clean images associated with those items. Attacks on VARS pose new security challenges to a wide range of applications such as e-Commerce and social networks where VARS are widely used. How to secure VARS from such adversarial attacks becomes a critical problem. Currently, there is still a lack of systematic study on how to design secure defense strategies against visual attacks on VARS. In this paper, we attempt to fill this gap by proposing an adversarial image reconstruction and detection framework to secure VARS. Our proposed method can simultaneously (1) secure VARS from adversarial attacks characterized by local perturbations by image reconstruction based on global vision transformers; and (2) accurately detect adversarial examples using a novel contrastive learning approach. Meanwhile, our framework is designed to be used as both a filter and a detector so that they can be jointly trained to improve the flexibility of our defense strategy to a variety of attacks and VARS models. We have conducted extensive experimental studies with two popular attack methods (FGSM and PGD). Our experimental results on two real-world datasets show that our defense strategy against visual attacks is effective and outperforms existing methods on different attacks. Moreover, our method can detect adversarial examples with high accuracy.
Reducing Popularity Bias in Recommender Systems through AUC-Optimal Negative Sampling
Jun 02, 2023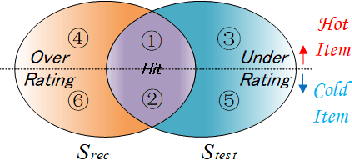
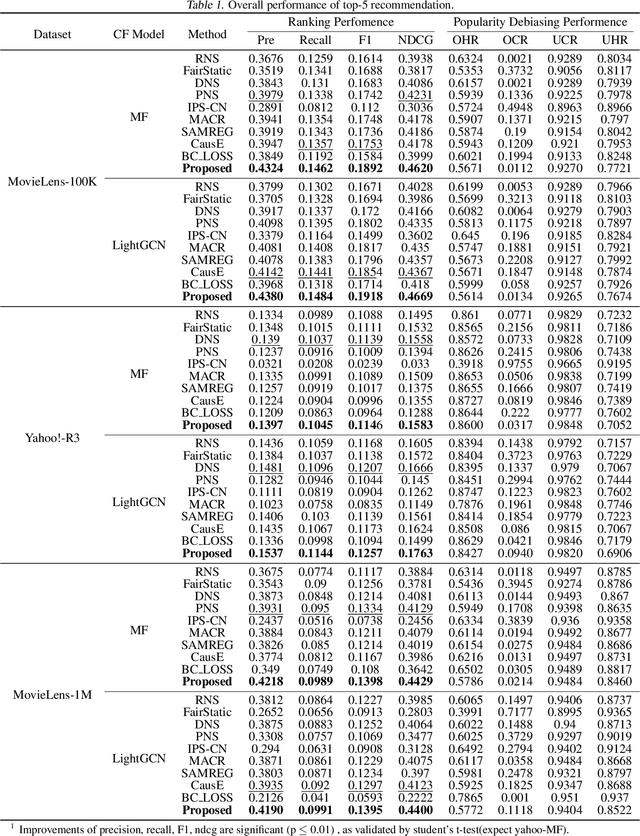
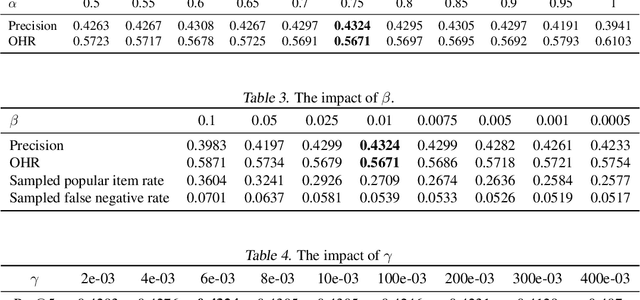

Popularity bias is a persistent issue associated with recommendation systems, posing challenges to both fairness and efficiency. Existing literature widely acknowledges that reducing popularity bias often requires sacrificing recommendation accuracy. In this paper, we challenge this commonly held belief. Our analysis under general bias-variance decomposition framework shows that reducing bias can actually lead to improved model performance under certain conditions. To achieve this win-win situation, we propose to intervene in model training through negative sampling thereby modifying model predictions. Specifically, we provide an optimal negative sampling rule that maximizes partial AUC to preserve the accuracy of any given model, while correcting sample information and prior information to reduce popularity bias in a flexible and principled way. Our experimental results on real-world datasets demonstrate the superiority of our approach in improving recommendation performance and reducing popularity bias.
Restormer-Plus for Real World Image Deraining: the Runner-up Solution to the GT-RAIN Challenge
May 26, 2023



This technical report presents our Restormer-Plus approach, which was submitted to the GT-RAIN Challenge (CVPR 2023 UG$^2$+ Track 3). Details regarding the challenge are available at http://cvpr2023.ug2challenge.org/track3.html. Restormer-Plus outperformed all other submitted solutions in terms of peak signal-to-noise ratio (PSNR), and ranked 4th in terms of structural similarity (SSIM). It was officially evaluated by the competition organizers as a runner-up solution. It consists of four main modules: the single-image de-raining module (Restormer-X), the median filtering module, the weighted averaging module, and the post-processing module. Restormer-X is applied to each rainy image and built on top of Restormer. The median filtering module is used as a median operator for rainy images associated with each scene. The weighted averaging module combines the median filtering results with those of Restormer-X to alleviate overfitting caused by using only Restormer-X. Finally, the post-processing module is utilized to improve the brightness restoration. These modules make Restormer-Plus one of the state-of-the-art solutions for the GT-RAIN Challenge. Our code can be found at https://github.com/ZJLAB-AMMI/Restormer-Plus.
Multi-spectral Class Center Network for Face Manipulation Detection and Localization
May 18, 2023As Deepfake contents continue to proliferate on the internet, advancing face manipulation forensics has become a pressing issue. To combat this emerging threat, previous methods mainly focus on studying how to distinguish authentic and manipulated face images. Despite impressive, image-level classification lacks explainability and is limited to some specific application scenarios. Existing forgery localization methods suffer from imprecise and inconsistent pixel-level annotations. To alleviate these problems, this paper first re-constructs the FaceForensics++ dataset by introducing pixel-level annotations, then builds an extensive benchmark for localizing tampered regions. Next, a novel Multi-Spectral Class Center Network (MSCCNet) is proposed for face manipulation detection and localization. Specifically, inspired by the power of frequency-related forgery traces, we design Multi-Spectral Class Center (MSCC) module to learn more generalizable and semantic-agnostic features. Based on the features of different frequency bands, the MSCC module collects multispectral class centers and computes pixel-to-class relations. Applying multi-spectral class-level representations suppresses the semantic information of the visual concepts, which is insensitive to manipulations. Furthermore, we propose a Multi-level Features Aggregation (MFA) module to employ more low-level forgery artifacts and structure textures. Experimental results quantitatively and qualitatively indicate the effectiveness and superiority of the proposed MSCCNet on comprehensive localization benchmarks. We expect this work to inspire more studies on pixel-level face manipulation localization. The annotations and code will be available.
Clothes-Invariant Feature Learning by Causal Intervention for Clothes-Changing Person Re-identification
May 10, 2023



Clothes-invariant feature extraction is critical to the clothes-changing person re-identification (CC-ReID). It can provide discriminative identity features and eliminate the negative effects caused by the confounder--clothing changes. But we argue that there exists a strong spurious correlation between clothes and human identity, that restricts the common likelihood-based ReID method P(Y|X) to extract clothes-irrelevant features. In this paper, we propose a new Causal Clothes-Invariant Learning (CCIL) method to achieve clothes-invariant feature learning by modeling causal intervention P(Y|do(X)). This new causality-based model is inherently invariant to the confounder in the causal view, which can achieve the clothes-invariant features and avoid the barrier faced by the likelihood-based methods. Extensive experiments on three CC-ReID benchmarks, including PRCC, LTCC, and VC-Clothes, demonstrate the effectiveness of our approach, which achieves a new state of the art.
Use the Detection Transformer as a Data Augmenter
Apr 26, 2023



Detection Transformer (DETR) is a Transformer architecture based object detection model. In this paper, we demonstrate that it can also be used as a data augmenter. We term our approach as DETR assisted CutMix, or DeMix for short. DeMix builds on CutMix, a simple yet highly effective data augmentation technique that has gained popularity in recent years. CutMix improves model performance by cutting and pasting a patch from one image onto another, yielding a new image. The corresponding label for this new example is specified as the weighted average of the original labels, where the weight is proportional to the area of the patch. CutMix selects a random patch to be cut. In contrast, DeMix elaborately selects a semantically rich patch, located by a pre-trained DETR. The label of the new image is specified in the same way as in CutMix. Experimental results on benchmark datasets for image classification demonstrate that DeMix significantly outperforms prior art data augmentation methods including CutMix. Oue code is available at https://github.com/ZJLAB-AMMI/DeMix.
MER 2023: Multi-label Learning, Modality Robustness, and Semi-Supervised Learning
Apr 18, 2023



Over the past few decades, multimodal emotion recognition has made remarkable progress with the development of deep learning. However, existing technologies are difficult to meet the demand for practical applications. To improve the robustness, we launch a Multimodal Emotion Recognition Challenge (MER 2023) to motivate global researchers to build innovative technologies that can further accelerate and foster research. For this year's challenge, we present three distinct sub-challenges: (1) MER-MULTI, in which participants recognize both discrete and dimensional emotions; (2) MER-NOISE, in which noise is added to test videos for modality robustness evaluation; (3) MER-SEMI, which provides large amounts of unlabeled samples for semi-supervised learning. In this paper, we test a variety of multimodal features and provide a competitive baseline for each sub-challenge. Our system achieves 77.57% on the F1 score and 0.82 on the mean squared error (MSE) for MER-MULTI, 69.82% on the F1 score and 1.12 on MSE for MER-NOISE, and 86.75% on the F1 score for MER-SEMI, respectively. Baseline code is available at https://github.com/zeroQiaoba/MER2023-Baseline.