 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Model Merging for Multi-target Domain Adaptation
Jul 18, 2024



In this paper, we study multi-target domain adaptation of scene understanding models. While previous methods achieved commendable results through inter-domain consistency losses, they often assumed unrealistic simultaneous access to images from all target domains, overlooking constraints such as data transfer bandwidth limitations and data privacy concerns. Given these challenges, we pose the question: How to merge models adapted independently on distinct domains while bypassing the need for direct access to training data? Our solution to this problem involves two components, merging model parameters and merging model buffers (i.e., normalization layer statistics). For merging model parameters, empirical analyses of mode connectivity surprisingly reveal that linear merging suffices when employing the same pretrained backbone weights for adapting separate models. For merging model buffers, we model the real-world distribution with a Gaussian prior and estimate new statistics from the buffers of separately trained models. Our method is simple yet effective, achieving comparable performance with data combination training baselines, while eliminating the need for accessing training data. Project page: https://air-discover.github.io/ModelMerging
Key Patch Proposer: Key Patches Contain Rich Information
Feb 18, 2024



In this paper, we introduce a novel algorithm named Key Patch Proposer (KPP) designed to select key patches in an image without additional training. Our experiments showcase KPP's robust capacity to capture semantic information by both reconstruction and classification tasks. The efficacy of KPP suggests its potential application in active learning for semantic segmentation. Our source code is publicly available at https://github.com/CA-TT-AC/key-patch-proposer.
Adaptive Surface Normal Constraint for Geometric Estimation from Monocular Images
Feb 08, 2024



We introduce a novel approach to learn geometries such as depth and surface normal from images while incorporating geometric context. The difficulty of reliably capturing geometric context in existing methods impedes their ability to accurately enforce the consistency between the different geometric properties, thereby leading to a bottleneck of geometric estimation quality. We therefore propose the Adaptive Surface Normal (ASN) constraint, a simple yet efficient method. Our approach extracts geometric context that encodes the geometric variations present in the input image and correlates depth estimation with geometric constraints. By dynamically determining reliable local geometry from randomly sampled candidates, we establish a surface normal constraint, where the validity of these candidates is evaluated using the geometric context. Furthermore, our normal estimation leverages the geometric context to prioritize regions that exhibit significant geometric variations, which makes the predicted normals accurately capture intricate and detailed geometric information. Through the integration of geometric context, our method unifies depth and surface normal estimations within a cohesive framework, which enables the generation of high-quality 3D geometry from images. We validate the superiority of our approach over state-of-the-art methods through extensive evaluations and comparisons on diverse indoor and outdoor datasets, showcasing its efficiency and robustness.
Latency-aware Road Anomaly Segmentation in Videos: A Photorealistic Dataset and New Metrics
Jan 10, 2024In the past several years, road anomaly segmentation is actively explored in the academia and drawing growing attention in the industry. The rationale behind is straightforward: if the autonomous car can brake before hitting an anomalous object, safety is promoted. However, this rationale naturally calls for a temporally informed setting while existing methods and benchmarks are designed in an unrealistic frame-wise manner. To bridge this gap, we contribute the first video anomaly segmentation dataset for autonomous driving. Since placing various anomalous objects on busy roads and annotating them in every frame are dangerous and expensive, we resort to synthetic data. To improve the relevance of this synthetic dataset to real-world applications, we train a generative adversarial network conditioned on rendering G-buffers for photorealism enhancement. Our dataset consists of 120,000 high-resolution frames at a 60 FPS framerate, as recorded in 7 different towns. As an initial benchmarking, we provide baselines using latest supervised and unsupervised road anomaly segmentation methods. Apart from conventional ones, we focus on two new metrics: temporal consistency and latencyaware streaming accuracy. We believe the latter is valuable as it measures whether an anomaly segmentation algorithm can truly prevent a car from crashing in a temporally informed setting.
DQS3D: Densely-matched Quantization-aware Semi-supervised 3D Detection
Apr 25, 2023



In this paper, we study the problem of semi-supervised 3D object detection, which is of great importance considering the high annotation cost for cluttered 3D indoor scenes. We resort to the robust and principled framework of selfteaching, which has triggered notable progress for semisupervised learning recently. While this paradigm is natural for image-level or pixel-level prediction, adapting it to the detection problem is challenged by the issue of proposal matching. Prior methods are based upon two-stage pipelines, matching heuristically selected proposals generated in the first stage and resulting in spatially sparse training signals. In contrast, we propose the first semisupervised 3D detection algorithm that works in the singlestage manner and allows spatially dense training signals. A fundamental issue of this new design is the quantization error caused by point-to-voxel discretization, which inevitably leads to misalignment between two transformed views in the voxel domain. To this end, we derive and implement closed-form rules that compensate this misalignment onthe-fly. Our results are significant, e.g., promoting ScanNet mAP@0.5 from 35.2% to 48.5% using 20% annotation. Codes and data will be publicly available.
Delving into Shape-aware Zero-shot Semantic Segmentation
Apr 17, 2023



Thanks to the impressive progress of large-scale vision-language pretraining, recent recognition models can classify arbitrary objects in a zero-shot and open-set manner, with a surprisingly high accuracy. However, translating this success to semantic segmentation is not trivial, because this dense prediction task requires not only accurate semantic understanding but also fine shape delineation and existing vision-language models are trained with image-level language descriptions. To bridge this gap, we pursue \textbf{shape-aware} zero-shot semantic segmentation in this study. Inspired by classical spectral methods in the image segmentation literature, we propose to leverage the eigen vectors of Laplacian matrices constructed with self-supervised pixel-wise features to promote shape-awareness. Despite that this simple and effective technique does not make use of the masks of seen classes at all, we demonstrate that it out-performs a state-of-the-art shape-aware formulation that aligns ground truth and predicted edges during training. We also delve into the performance gains achieved on different datasets using different backbones and draw several interesting and conclusive observations: the benefits of promoting shape-awareness highly relates to mask compactness and language embedding locality. Finally, our method sets new state-of-the-art performance for zero-shot semantic segmentation on both Pascal and COCO, with significant margins. Code and models will be accessed at https://github.com/Liuxinyv/SAZS.
From Semi-supervised to Omni-supervised Room Layout Estimation Using Point Clouds
Jan 31, 2023Room layout estimation is a long-existing robotic vision task that benefits both environment sensing and motion planning. However, layout estimation using point clouds (PCs) still suffers from data scarcity due to annotation difficulty. As such, we address the semi-supervised setting of this task based upon the idea of model exponential moving averaging. But adapting this scheme to the state-of-the-art (SOTA) solution for PC-based layout estimation is not straightforward. To this end, we define a quad set matching strategy and several consistency losses based upon metrics tailored for layout quads. Besides, we propose a new online pseudo-label harvesting algorithm that decomposes the distribution of a hybrid distance measure between quads and PC into two components. This technique does not need manual threshold selection and intuitively encourages quads to align with reliable layout points. Surprisingly, this framework also works for the fully-supervised setting, achieving a new SOTA on the ScanNet benchmark. Last but not least, we also push the semi-supervised setting to the realistic omni-supervised setting, demonstrating significantly promoted performance on a newly annotated ARKitScenes testing set. Our codes, data and models are released in this repository.
VIBUS: Data-efficient 3D Scene Parsing with VIewpoint Bottleneck and Uncertainty-Spectrum Modeling
Oct 20, 2022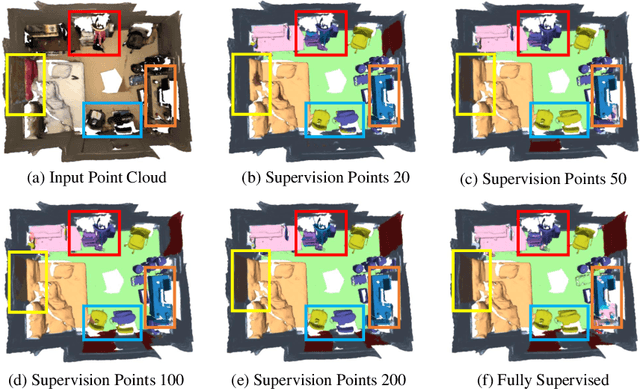
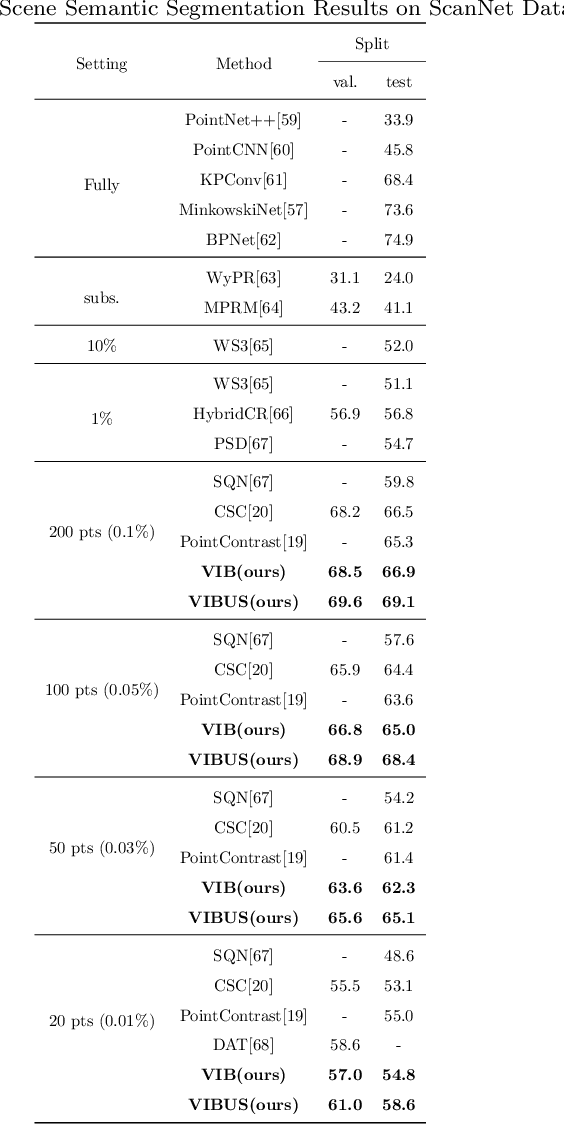
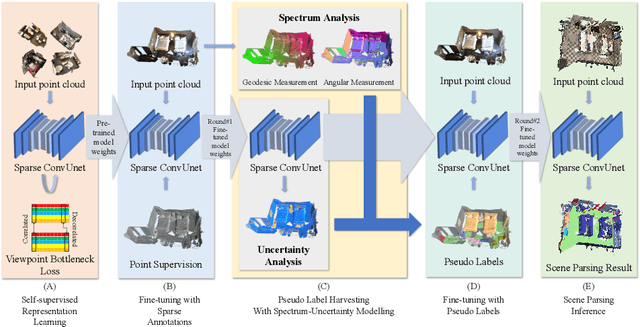
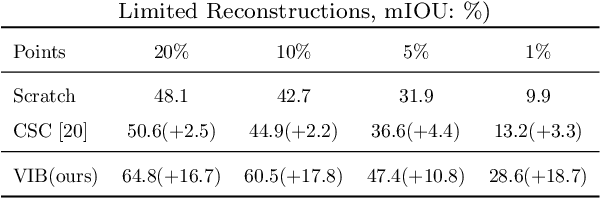
Recently, 3D scenes parsing with deep learning approaches has been a heating topic. However, current methods with fully-supervised models require manually annotated point-wise supervision which is extremely user-unfriendly and time-consuming to obtain. As such, training 3D scene parsing models with sparse supervision is an intriguing alternative. We term this task as data-efficient 3D scene parsing and propose an effective two-stage framework named VIBUS to resolve it by exploiting the enormous unlabeled points. In the first stage, we perform self-supervised representation learning on unlabeled points with the proposed Viewpoint Bottleneck loss function. The loss function is derived from an information bottleneck objective imposed on scenes under different viewpoints, making the process of representation learning free of degradation and sampling. In the second stage, pseudo labels are harvested from the sparse labels based on uncertainty-spectrum modeling. By combining data-driven uncertainty measures and 3D mesh spectrum measures (derived from normal directions and geodesic distances), a robust local affinity metric is obtained. Finite gamma/beta mixture models are used to decompose category-wise distributions of these measures, leading to automatic selection of thresholds. We evaluate VIBUS on the public benchmark ScanNet and achieve state-of-the-art results on both validation set and online test server. Ablation studies show that both Viewpoint Bottleneck and uncertainty-spectrum modeling bring significant improvements. Codes and models are publicly available at https://github.com/AIR-DISCOVER/VIBUS.
TOIST: Task Oriented Instance Segmentation Transformer with Noun-Pronoun Distillation
Oct 19, 2022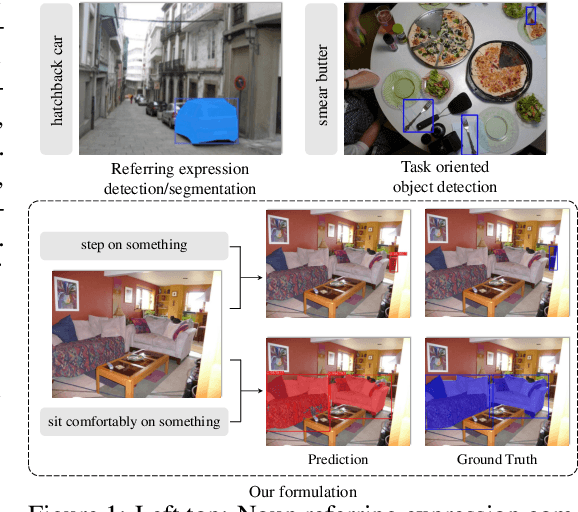

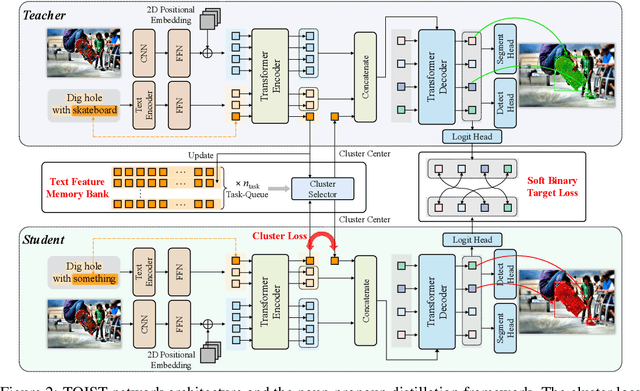
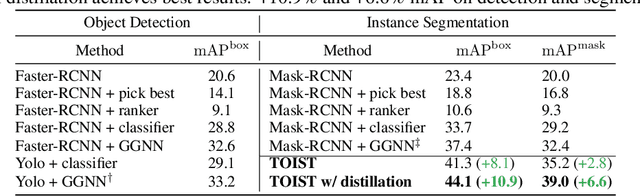
Current referring expression comprehension algorithms can effectively detect or segment objects indicated by nouns, but how to understand verb reference is still under-explored. As such, we study the challenging problem of task oriented detection, which aims to find objects that best afford an action indicated by verbs like sit comfortably on. Towards a finer localization that better serves downstream applications like robot interaction, we extend the problem into task oriented instance segmentation. A unique requirement of this task is to select preferred candidates among possible alternatives. Thus we resort to the transformer architecture which naturally models pair-wise query relationships with attention, leading to the TOIST method. In order to leverage pre-trained noun referring expression comprehension models and the fact that we can access privileged noun ground truth during training, a novel noun-pronoun distillation framework is proposed. Noun prototypes are generated in an unsupervised manner and contextual pronoun features are trained to select prototypes. As such, the network remains noun-agnostic during inference. We evaluate TOIST on the large-scale task oriented dataset COCO-Tasks and achieve +10.9% higher $\rm{mAP^{box}}$ than the best-reported results. The proposed noun-pronoun distillation can boost $\rm{mAP^{box}}$ and $\rm{mAP^{mask}}$ by +2.8% and +3.8%. Codes and models are publicly available at https://github.com/AIR-DISCOVER/TOIST.
Language-guided Semantic Style Transfer of 3D Indoor Scenes
Aug 16, 2022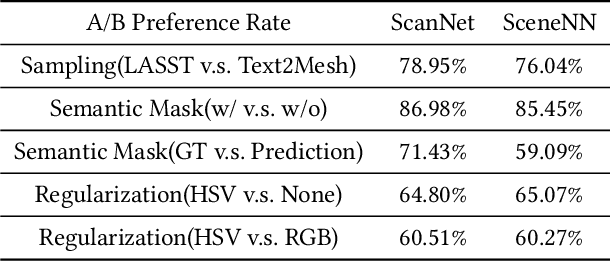
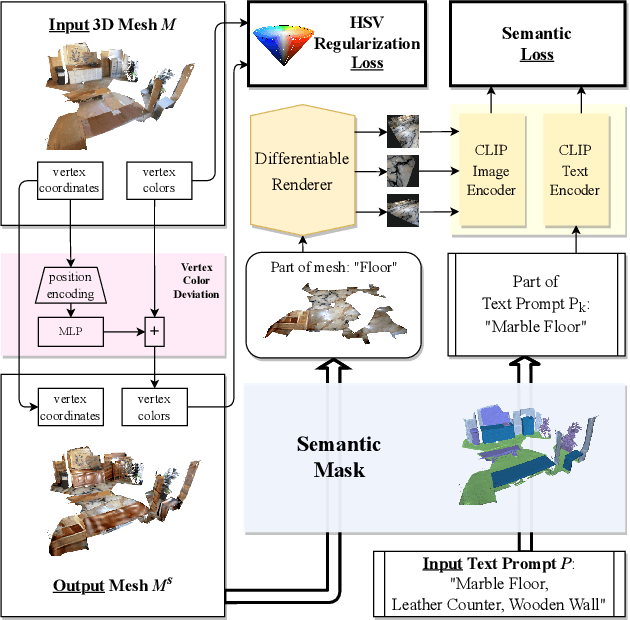
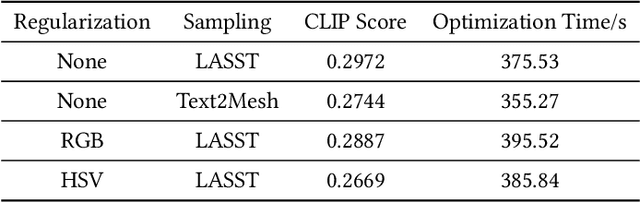
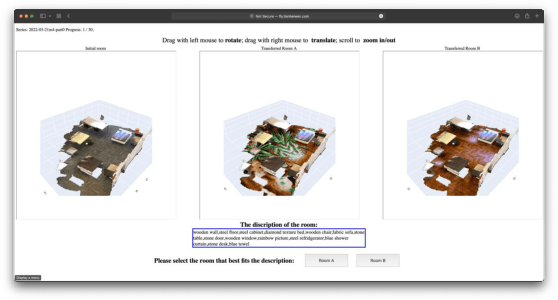
We address the new problem of language-guided semantic style transfer of 3D indoor scenes. The input is a 3D indoor scene mesh and several phrases that describe the target scene. Firstly, 3D vertex coordinates are mapped to RGB residues by a multi-layer perceptron. Secondly, colored 3D meshes are differentiablly rendered into 2D images, via a viewpoint sampling strategy tailored for indoor scenes. Thirdly, rendered 2D images are compared to phrases, via pre-trained vision-language models. Lastly, errors are back-propagated to the multi-layer perceptron to update vertex colors corresponding to certain semantic categories. We did large-scale qualitative analyses and A/B user tests, with the public ScanNet and SceneNN datasets. We demonstrate: (1) visually pleasing results that are potentially useful for multimedia applications. (2) rendering 3D indoor scenes from viewpoints consistent with human priors is important. (3) incorporating semantics significantly improve style transfer quality. (4) an HSV regularization term leads to results that are more consistent with inputs and generally rated better. Codes and user study toolbox are available at https://github.com/AIR-DISCOVER/LASST