 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPT: Semi-Parametric Prompt Tuning for Multitask Prompted Learning
Dec 21, 2022



Pre-trained large language models can efficiently interpolate human-written prompts in a natural way. Multitask prompted learning can help generalization through a diverse set of tasks at once, thus enhancing the potential for more effective downstream fine-tuning. To perform efficient multitask-inference in the same batch, parameter-efficient fine-tuning methods such as prompt tuning have been proposed. However, the existing prompt tuning methods may lack generalization. We propose SPT, a semi-parametric prompt tuning method for multitask prompted learning. The novel component of SPT is a memory bank from where memory prompts are retrieved based on discrete prompts. Extensive experiments, such as (i) fine-tuning a full language model with SPT on 31 different tasks from 8 different domains and evaluating zero-shot generalization on 9 heldout datasets under 5 NLP task categories and (ii) pretraining SPT on the GLUE datasets and evaluating fine-tuning on the SuperGLUE datasets, demonstrate effectiveness of SPT.
SMILE: Scaling Mixture-of-Experts with Efficient Bi-level Routing
Dec 10, 2022



The mixture of Expert (MoE) parallelism is a recent advancement that scales up the model size with constant computational cost. MoE selects different sets of parameters (i.e., experts) for each incoming token, resulting in a sparsely-activated model. Despite several successful applications of MoE, its training efficiency degrades significantly as the number of experts increases. The routing stage in MoE relies on the efficiency of the All2All communication collective, which suffers from network congestion and has poor scalability. To mitigate these issues, we introduce SMILE, which exploits heterogeneous network bandwidth and splits a single-step routing into bi-level routing. Our experimental results show that the proposed method obtains a 2.5x speedup over Switch Transformer in terms of pretraining throughput on the Colossal Clean Crawled Corpus without losing any convergence speed.
Trap and Replace: Defending Backdoor Attacks by Trapping Them into an Easy-to-Replace Subnetwork
Oct 12, 2022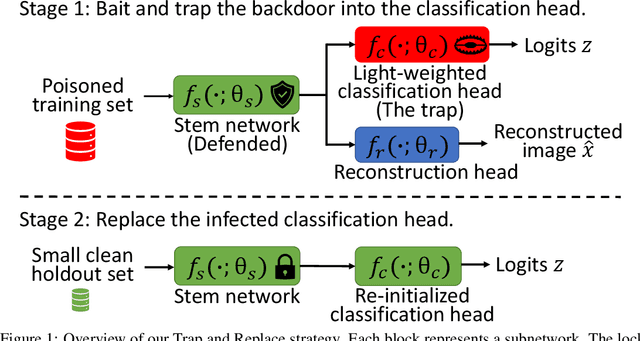
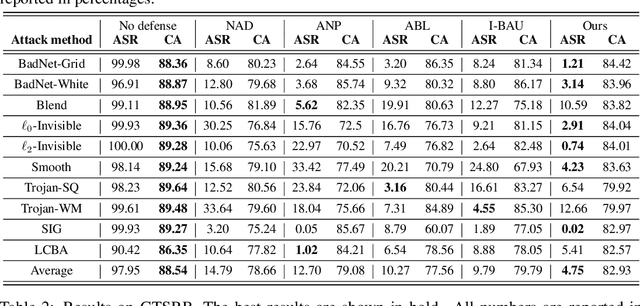
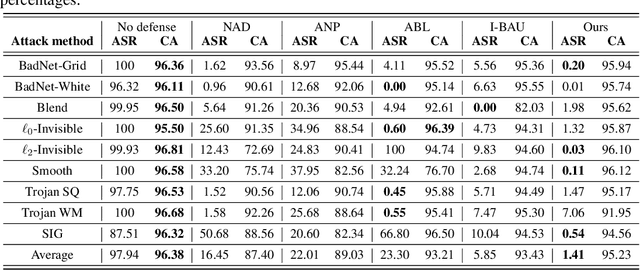
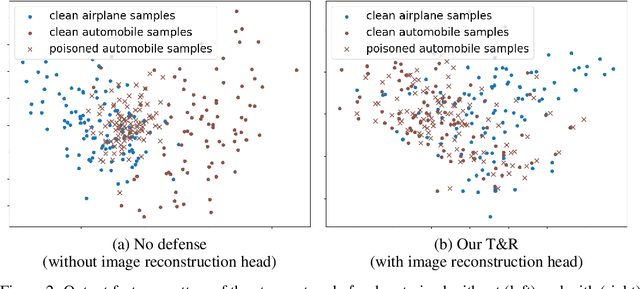
Deep neural networks (DNNs) are vulnerable to backdoor attacks. Previous works have shown it extremely challenging to unlearn the undesired backdoor behavior from the network, since the entire network can be affected by the backdoor samples. In this paper, we propose a brand-new backdoor defense strategy, which makes it much easier to remove the harmful influence of backdoor samples from the model. Our defense strategy, \emph{Trap and Replace}, consists of two stages. In the first stage, we bait and trap the backdoors in a small and easy-to-replace subnetwork. Specifically, we add an auxiliary image reconstruction head on top of the stem network shared with a light-weighted classification head. The intuition is that the auxiliary image reconstruction task encourages the stem network to keep sufficient low-level visual features that are hard to learn but semantically correct, instead of overfitting to the easy-to-learn but semantically incorrect backdoor correlations. As a result, when trained on backdoored datasets, the backdoors are easily baited towards the unprotected classification head, since it is much more vulnerable than the shared stem, leaving the stem network hardly poisoned. In the second stage, we replace the poisoned light-weighted classification head with an untainted one, by re-training it from scratch only on a small holdout dataset with clean samples, while fixing the stem network. As a result, both the stem and the classification head in the final network are hardly affected by backdoor training samples. We evaluate our method against ten different backdoor attacks. Our method outperforms previous state-of-the-art methods by up to $20.57\%$, $9.80\%$, and $13.72\%$ attack success rate and on-average $3.14\%$, $1.80\%$, and $1.21\%$ clean classification accuracy on CIFAR10, GTSRB, and ImageNet-12, respectively. Code is available online.
Automatic Chain of Thought Prompting in Large Language Models
Oct 07, 2022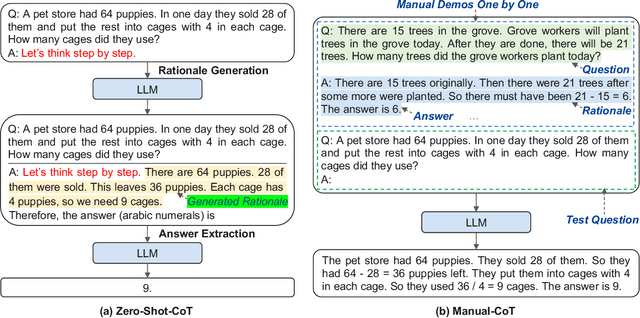
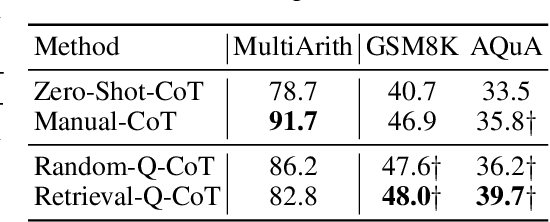
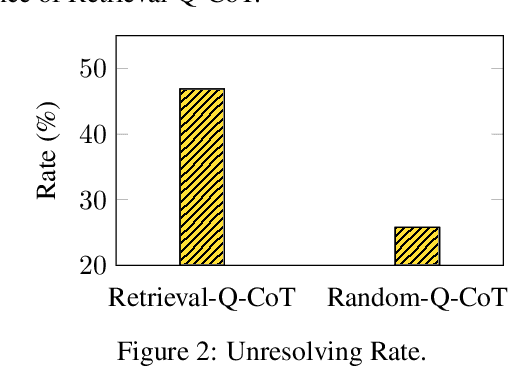

Large language models (LLMs) can perform complex reasoning by generating intermediate reasoning steps. Providing these steps for prompting demonstrations is called chain-of-thought (CoT) prompting. CoT prompting has two major paradigms. One leverages a simple prompt like "Let's think step by step" to facilitate step-by-step thinking before answering a question. The other uses a few manual demonstrations one by one, each composed of a question and a reasoning chain that leads to an answer. The superior performance of the second paradigm hinges on the hand-crafting of task-specific demonstrations one by one. We show that such manual efforts may be eliminated by leveraging LLMs with the "Let's think step by step" prompt to generate reasoning chains for demonstrations one by one, i.e., let's think not just step by step, but also one by one. However, these generated chains often come with mistakes. To mitigate the effect of such mistakes, we find that diversity matters for automatically constructing demonstrations. We propose an automatic CoT prompting method: Auto-CoT. It samples questions with diversity and generates reasoning chains to construct demonstrations. On ten public benchmark reasoning tasks with GPT-3, Auto-CoT consistently matches or exceeds the performance of the CoT paradigm that requires manual designs of demonstrations. Code is available at https://github.com/amazon-research/auto-cot
Partial and Asymmetric Contrastive Learning for Out-of-Distribution Detection in Long-Tailed Recognition
Jul 04, 2022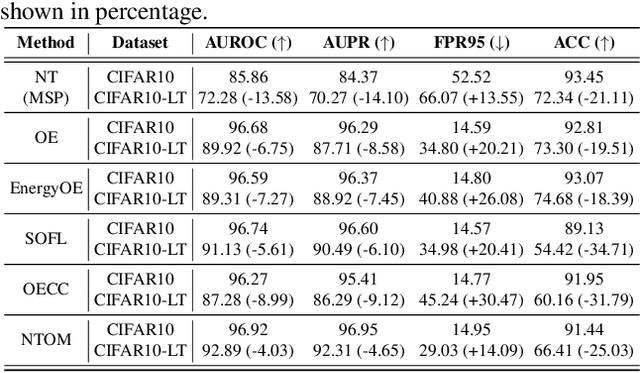
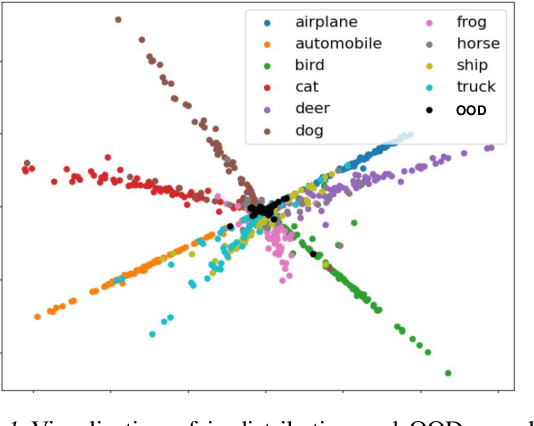
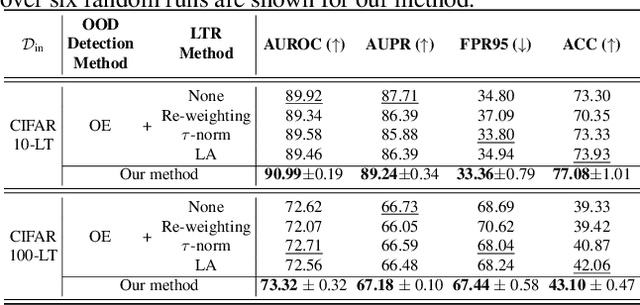
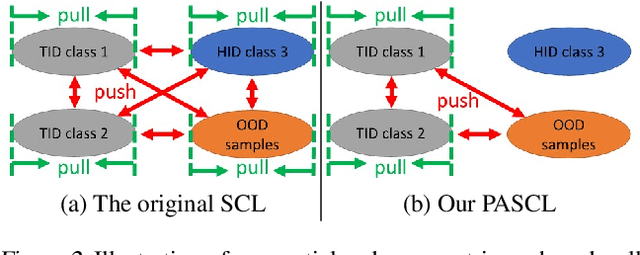
Existing out-of-distribution (OOD) detection methods are typically benchmarked on training sets with balanced class distributions. However, in real-world applications, it is common for the training sets to have long-tailed distributions. In this work, we first demonstrate that existing OOD detection methods commonly suffer from significant performance degradation when the training set is long-tail distributed. Through analysis, we posit that this is because the models struggle to distinguish the minority tail-class in-distribution samples, from the true OOD samples, making the tail classes more prone to be falsely detected as OOD. To solve this problem, we propose Partial and Asymmetric Supervised Contrastive Learning (PASCL), which explicitly encourages the model to distinguish between tail-class in-distribution samples and OOD samples. To further boost in-distribution classification accuracy, we propose Auxiliary Branch Finetuning, which uses two separate branches of BN and classification layers for anomaly detection and in-distribution classification, respectively. The intuition is that in-distribution and OOD anomaly data have different underlying distributions. Our method outperforms previous state-of-the-art method by $1.29\%$, $1.45\%$, $0.69\%$ anomaly detection false positive rate (FPR) and $3.24\%$, $4.06\%$, $7.89\%$ in-distribution classification accuracy on CIFAR10-LT, CIFAR100-LT, and ImageNet-LT, respectively. Code and pre-trained models are available at https://github.com/amazon-research/long-tailed-ood-detection.
Removing Batch Normalization Boosts Adversarial Training
Jul 04, 2022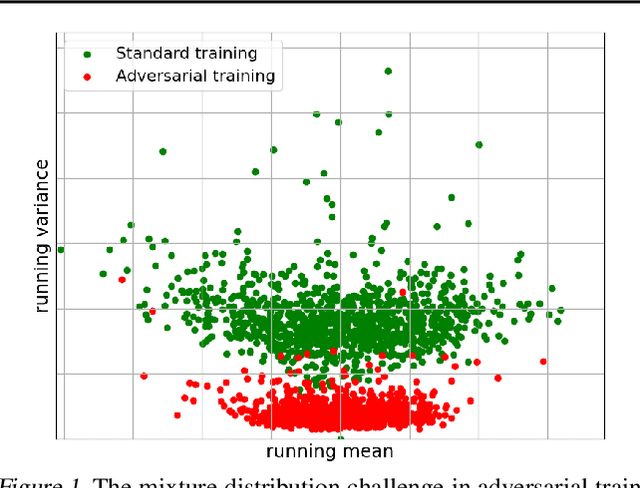
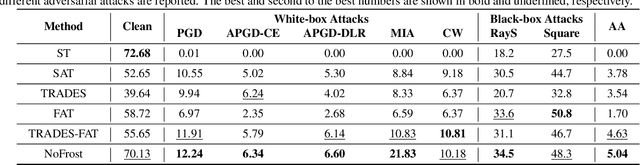
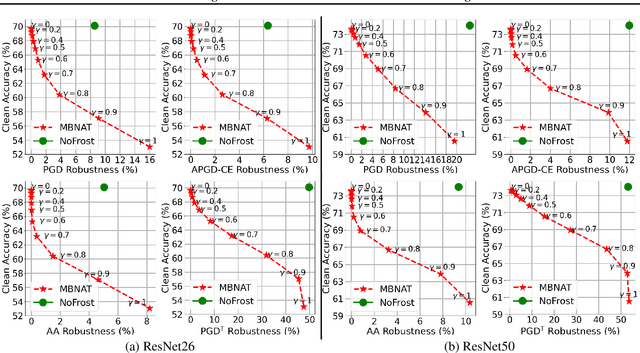
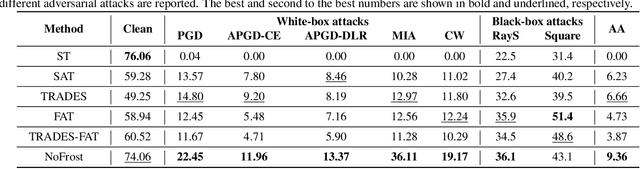
Adversarial training (AT) defends deep neural networks against adversarial attacks. One challenge that limits its practical application is the performance degradation on clean samples. A major bottleneck identified by previous works is the widely used batch normalization (BN), which struggles to model the different statistics of clean and adversarial training samples in AT. Although the dominant approach is to extend BN to capture this mixture of distribution, we propose to completely eliminate this bottleneck by removing all BN layers in AT. Our normalizer-free robust training (NoFrost) method extends recent advances in normalizer-free networks to AT for its unexplored advantage on handling the mixture distribution challenge. We show that NoFrost achieves adversarial robustness with only a minor sacrifice on clean sample accuracy. On ImageNet with ResNet50, NoFrost achieves $74.06\%$ clean accuracy, which drops merely $2.00\%$ from standard training. In contrast, BN-based AT obtains $59.28\%$ clean accuracy, suffering a significant $16.78\%$ drop from standard training. In addition, NoFrost achieves a $23.56\%$ adversarial robustness against PGD attack, which improves the $13.57\%$ robustness in BN-based AT. We observe better model smoothness and larger decision margins from NoFrost, which make the models less sensitive to input perturbations and thus more robust. Moreover, when incorporating more data augmentations into NoFrost, it achieves comprehensive robustness against multiple distribution shifts. Code and pre-trained models are public at https://github.com/amazon-research/normalizer-free-robust-training.
MixGen: A New Multi-Modal Data Augmentation
Jun 16, 2022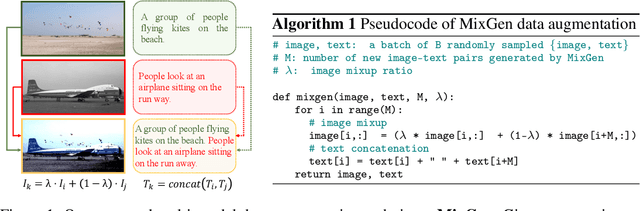

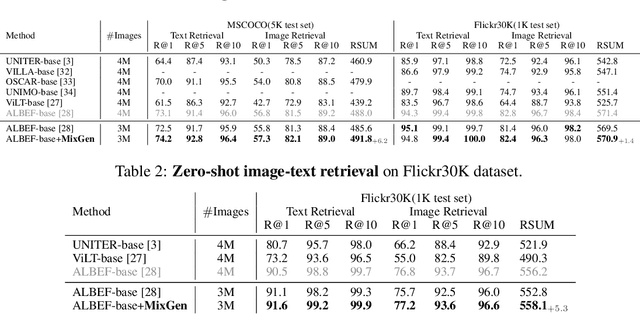
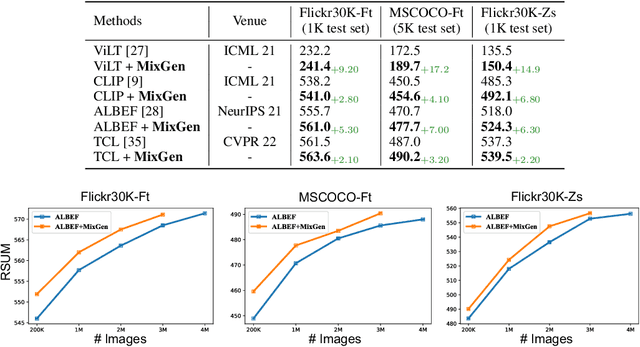
Data augmentation is a necessity to enhance data efficiency in deep learning. For vision-language pre-training, data is only augmented either for images or for text in previous works. In this paper, we present MixGen: a joint data augmentation for vision-language representation learning to further improve data efficiency. It generates new image-text pairs with semantic relationships preserved by interpolating images and concatenating text. It's simple, and can be plug-and-played into existing pipelines. We evaluate MixGen on four architectures, including CLIP, ViLT, ALBEF and TCL, across five downstream vision-language tasks to show its versatility and effectiveness. For example, adding MixGen in ALBEF pre-training leads to absolute performance improvements on downstream tasks: image-text retrieval (+6.2% on COCO fine-tuned and +5.3% on Flicker30K zero-shot), visual grounding (+0.9% on RefCOCO+), visual reasoning (+0.9% on NLVR$^{2}$), visual question answering (+0.3% on VQA2.0), and visual entailment (+0.4% on SNLI-VE).
Lightweight Convolutional Neural Networks By Hypercomplex Parameterization
Oct 08, 2021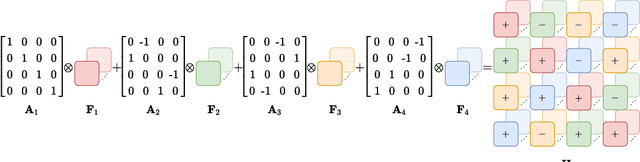
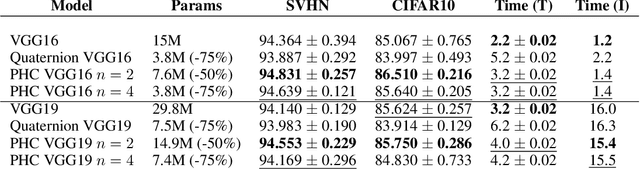
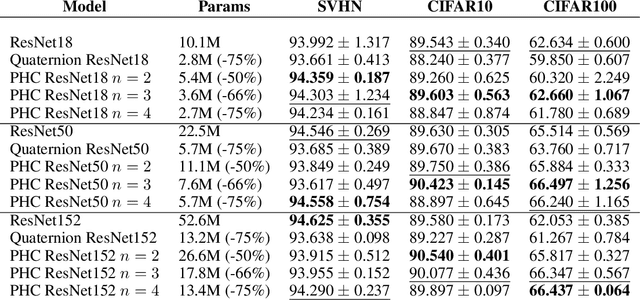
Hypercomplex neural networks have proved to reduce the overall number of parameters while ensuring valuable performances by leveraging the properties of Clifford algebras. Recently, hypercomplex linear layers have been further improved by involving efficient parameterized Kronecker products. In this paper, we define the parameterization of hypercomplex convolutional layers to develop lightweight and efficient large-scale convolutional models. Our method grasps the convolution rules and the filters organization directly from data without requiring a rigidly predefined domain structure to follow. The proposed approach is flexible to operate in any user-defined or tuned domain, from 1D to $n$D regardless of whether the algebra rules are preset. Such a malleability allows processing multidimensional inputs in their natural domain without annexing further dimensions, as done, instead, in quaternion neural networks for 3D inputs like color images. As a result, the proposed method operates with $1/n$ free parameters as regards its analog in the real domain. We demonstrate the versatility of this approach to multiple domains of application by performing experiments on various image datasets as well as audio datasets in which our method outperforms real and quaternion-valued counterparts.
Dive into Deep Learning
Jun 21, 2021
This open-source book represents our attempt to make deep learning approachable, teaching readers the concepts, the context, and the code. The entire book is drafted in Jupyter notebooks, seamlessly integrating exposition figures, math, and interactive examples with self-contained code. Our goal is to offer a resource that could (i) be freely available for everyone; (ii) offer sufficient technical depth to provide a starting point on the path to actually becoming an applied machine learning scientist; (iii) include runnable code, showing readers how to solve problems in practice; (iv) allow for rapid updates, both by us and also by the community at large; (v) be complemented by a forum for interactive discussion of technical details and to answer questions.
Controllable and Diverse Text Generation in E-commerce
Feb 23, 2021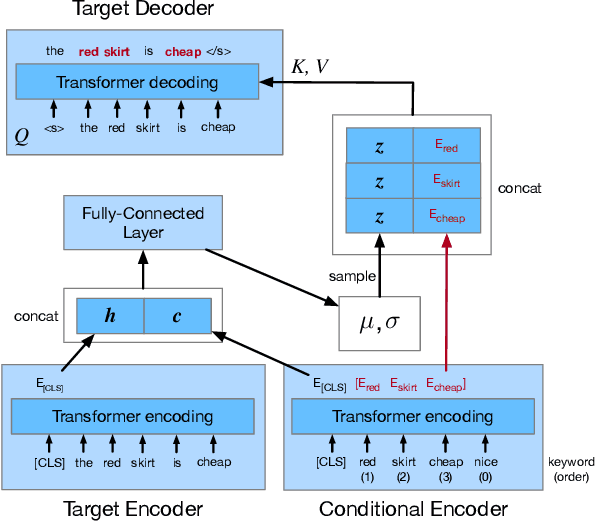
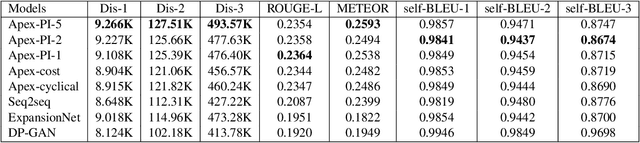
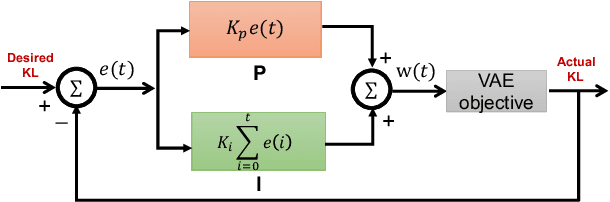
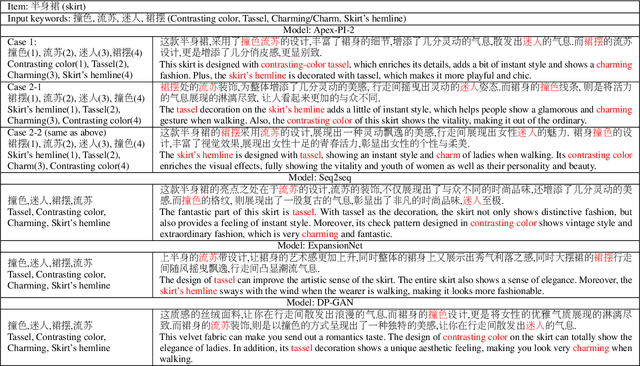
In E-commerce, a key challenge in text generation is to find a good trade-off between word diversity and accuracy (relevance) in order to make generated text appear more natural and human-like. In order to improve the relevance of generated results, conditional text generators were developed that use input keywords or attributes to produce the corresponding text. Prior work, however, do not finely control the diversity of automatically generated sentences. For example, it does not control the order of keywords to put more relevant ones first. Moreover, it does not explicitly control the balance between diversity and accuracy. To remedy these problems, we propose a fine-grained controllable generative model, called~\textit{Apex}, that uses an algorithm borrowed from automatic control (namely, a variant of the \textit{proportional, integral, and derivative (PID) controller}) to precisely manipulate the diversity/accuracy trade-off of generated text. The algorithm is injected into a Conditional Variational Autoencoder (CVAE), allowing \textit{Apex} to control both (i) the order of keywords in the generated sentences (conditioned on the input keywords and their order), and (ii) the trade-off between diversity and accuracy. Evaluation results on real-world datasets show that the proposed method outperforms existing generative models in terms of diversity and relevance. Apex is currently deployed to generate production descriptions and item recommendation reasons in Taobao owned by Alibaba, the largest E-commerce platform in China. The A/B production test results show that our method improves click-through rate (CTR) by 13.17\% compared to the existing method for production descriptions. For item recommendation reason, it is able to increase CTR by 6.89\% and 1.42\% compared to user reviews and top-K item recommendation without reviews, respectively.