 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Creativity Evaluation of Language Models Across Open-Ended Tasks
Jun 10, 2026Large language models (LLMs) have achieved remarkable progress in language understanding, reasoning, and generation, sparking growing interest in their creative potential. Realizing this potential requires systematic and scalable methods for evaluating creativity across diverse tasks. However, most existing creativity metrics are tightly coupled to specific tasks, embedding domain assumptions into the evaluation process, and limiting scalability and generality. To address this gap, we introduce an automated, domain-agnostic framework for quantifying LLM creativity across open-ended tasks. Our approach separates the measurement apparatus from the creative task itself, enabling scalable, task-agnostic assessment. Divergent creativity is measured using semantic entropy, a reference-free and robust metric for novelty and diversity, validated against human annotations, LLM-based novelty judgments and baseline diversity measures. Convergent creativity is assessed via a novel retrieval-based multi-agent judge framework that delivers context-sensitive evaluation of task fulfilment with over 60% improved efficiency. We validate our framework in three qualitatively distinct domains: problem-solving (MacGyver), research ideation (HypoGen), and creative writing (BookMIA), using a broad suite of LLMs. Empirical results show that our framework reliably captures key facets of creativity, including novelty, diversity, and task fulfilment, and reveal how model properties, such as size, temperature, recency, and reasoning, impact creative performance. Our work establishes a reproducible and generalizable standard for automated LLM creativity evaluation, paving the way for scalable benchmarking and accelerating progress in creative AI.
Towards Understanding Modality Interaction in Multimodal Language Models via Partial Information Decomposition
May 31, 2026Understanding modality interaction in multimodal large language models (MLLMs) is central to reliable deployment. We introduce Partial Information Decomposition (PID) as a decision-level framework that separates unique, redundant, and synergistic contributions of sensory and linguistic inputs, beyond representation alignment and outcome-based evaluation. Across vision--language benchmarks, PID reveals recurring modality-use profiles: reasoning and grounding-oriented tasks tend to exhibit high synergy, whereas expert and knowledge-oriented tasks show stronger language-unique reliance. These profiles generalize across model families and predict sensitivity to modality-level interventions. We further extend PID to tri-modal systems with Sensory PID, treating language as a control variable to decompose video--audio information gain. Applied to omni-modal models, Sensory PID reveals a sensory synergy bottleneck dominated by visual information even on audio--visual fusion tasks. Finally, PID-guided reweighting provides initial evidence for improving multimodal reasoning and grounding performance.
How Creative Are Large Language Models in Generating Molecules?
Apr 20, 2026Molecule generation requires satisfying multiple chemical and biological constraints while searching a large and structured chemical space. This makes it a non-binary problem, where effective models must identify non-obvious solutions under constraints while maintaining exploration to improve success by escaping local optima. From this perspective, creativity is a functional requirement in molecular generation rather than an aesthetic notion. Large language models (LLMs) can generate molecular representations directly from natural language prompts, but it remains unclear what type of creativity they exhibit in this setting and how it should be evaluated. In this work, we study the creative behavior of LLMs in molecular generation through a systematic empirical evaluation across physicochemical, ADMET, and biological activity tasks. We characterize creativity along two complementary dimensions, convergent creativity and divergent creativity, and analyze how different factors shape these behaviors. Our results indicate that LLMs exhibit distinct patterns of creative behavior in molecule generation, such as an increase in constraint satisfaction when additional constraints are imposed. Overall, our work is the first to reframe the abilities required for molecule generation as creativity, providing a systematic understanding of creativity in LLM-based molecular generation and clarifying the appropriate use of LLMs in molecular discovery pipelines.
The Triangle of Similarity: A Multi-Faceted Framework for Comparing Neural Network Representations
Jan 23, 2026Comparing neural network representations is essential for understanding and validating models in scientific applications. Existing methods, however, often provide a limited view. We propose the Triangle of Similarity, a framework that combines three complementary perspectives: static representational similarity (CKA/Procrustes), functional similarity (Linear Mode Connectivity or Predictive Similarity), and sparsity similarity (robustness under pruning). Analyzing a range of CNNs, Vision Transformers, and Vision-Language Models using both in-distribution (ImageNetV2) and out-of-distribution (CIFAR-10) testbeds, our initial findings suggest that: (1) architectural family is a primary determinant of representational similarity, forming distinct clusters; (2) CKA self-similarity and task accuracy are strongly correlated during pruning, though accuracy often degrades more sharply; and (3) for some model pairs, pruning appears to regularize representations, exposing a shared computational core. This framework offers a more holistic approach for assessing whether models have converged on similar internal mechanisms, providing a useful tool for model selection and analysis in scientific research.
To Align or Not to Align: Strategic Multimodal Representation Alignment for Optimal Performance
Nov 19, 2025Multimodal learning often relies on aligning representations across modalities to enable effective information integration, an approach traditionally assumed to be universally beneficial. However, prior research has primarily taken an observational approach, examining naturally occurring alignment in multimodal data and exploring its correlation with model performance, without systematically studying the direct effects of explicitly enforced alignment between representations of different modalities. In this work, we investigate how explicit alignment influences both model performance and representation alignment under different modality-specific information structures. Specifically, we introduce a controllable contrastive learning module that enables precise manipulation of alignment strength during training, allowing us to explore when explicit alignment improves or hinders performance. Our results on synthetic and real datasets under different data characteristics show that the impact of explicit alignment on the performance of unimodal models is related to the characteristics of the data: the optimal level of alignment depends on the amount of redundancy between the different modalities. We identify an optimal alignment strength that balances modality-specific signals and shared redundancy in the mixed information distributions. This work provides practical guidance on when and how explicit alignment should be applied to achieve optimal unimodal encoder performance.
Pretraining ECG Data with Adversarial Masking Improves Model Generalizability for Data-Scarce Tasks
Nov 15, 2022



Medical datasets often face the problem of data scarcity, as ground truth labels must be generated by medical professionals. One mitigation strategy is to pretrain deep learning models on large, unlabelled datasets with self-supervised learning (SSL). Data augmentations are essential for improving the generalizability of SSL-trained models, but they are typically handcrafted and tuned manually. We use an adversarial model to generate masks as augmentations for 12-lead electrocardiogram (ECG) data, where masks learn to occlude diagnostically-relevant regions of the ECGs. Compared to random augmentations, adversarial masking reaches better accuracy when transferring to to two diverse downstream objectives: arrhythmia classification and gender classification. Compared to a state-of-art ECG augmentation method 3KG, adversarial masking performs better in data-scarce regimes, demonstrating the generalizability of our model.
How Does Frequency Bias Affect the Robustness of Neural Image Classifiers against Common Corruption and Adversarial Perturbations?
May 09, 2022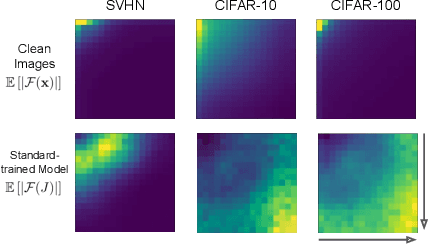
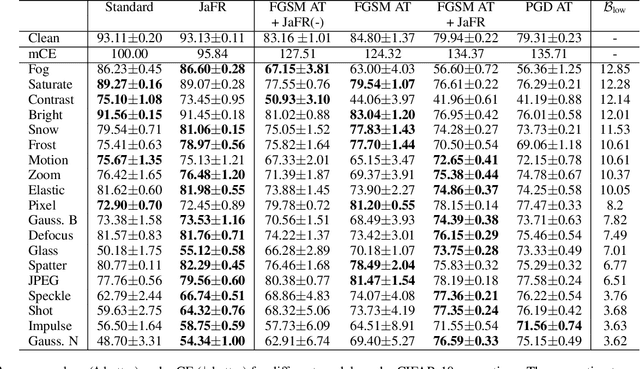
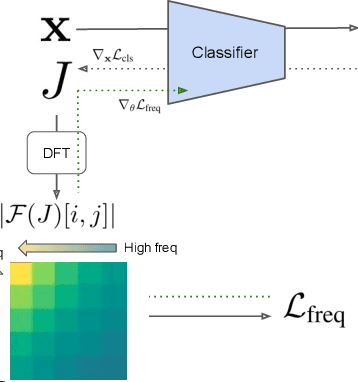
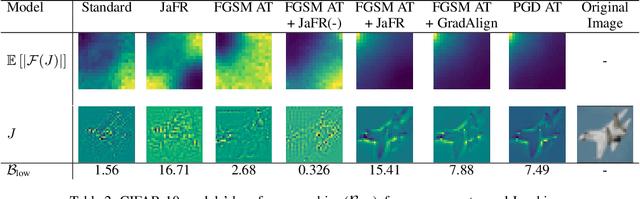
Model robustness is vital for the reliable deployment of machine learning models in real-world applications. Recent studies have shown that data augmentation can result in model over-relying on features in the low-frequency domain, sacrificing performance against low-frequency corruptions, highlighting a connection between frequency and robustness. Here, we take one step further to more directly study the frequency bias of a model through the lens of its Jacobians and its implication to model robustness. To achieve this, we propose Jacobian frequency regularization for models' Jacobians to have a larger ratio of low-frequency components. Through experiments on four image datasets, we show that biasing classifiers towards low (high)-frequency components can bring performance gain against high (low)-frequency corruption and adversarial perturbation, albeit with a tradeoff in performance for low (high)-frequency corruption. Our approach elucidates a more direct connection between the frequency bias and robustness of deep learning models.
A Survey on AI Sustainability: Emerging Trends on Learning Algorithms and Research Challenges
May 08, 2022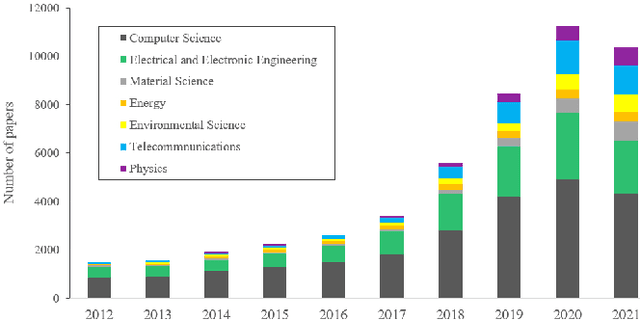
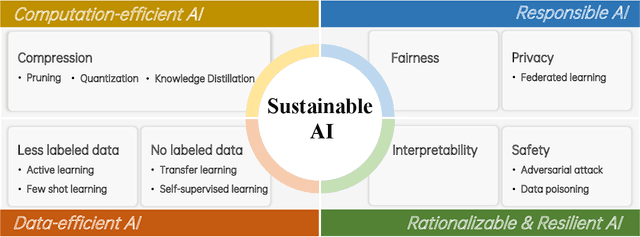

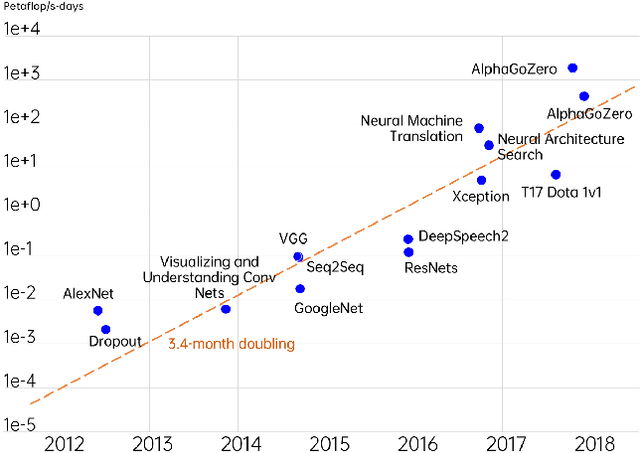
Artificial Intelligence (AI) is a fast-growing research and development (R&D) discipline which is attracting increasing attention because of its promises to bring vast benefits for consumers and businesses, with considerable benefits promised in productivity growth and innovation. To date it has reported significant accomplishments in many areas that have been deemed as challenging for machines, ranging from computer vision, natural language processing, audio analysis to smart sensing and many others. The technical trend in realizing the successes has been towards increasing complex and large size AI models so as to solve more complex problems at superior performance and robustness. This rapid progress, however, has taken place at the expense of substantial environmental costs and resources. Besides, debates on the societal impacts of AI, such as fairness, safety and privacy, have continued to grow in intensity. These issues have presented major concerns pertaining to the sustainable development of AI. In this work, we review major trends in machine learning approaches that can address the sustainability problem of AI. Specifically, we examine emerging AI methodologies and algorithms for addressing the sustainability issue of AI in two major aspects, i.e., environmental sustainability and social sustainability of AI. We will also highlight the major limitations of existing studies and propose potential research challenges and directions for the development of next generation of sustainable AI techniques. We believe that this technical review can help to promote a sustainable development of AI R&D activities for the research community.
ORCHARD: A Benchmark For Measuring Systematic Generalization of Multi-Hierarchical Reasoning
Nov 28, 2021
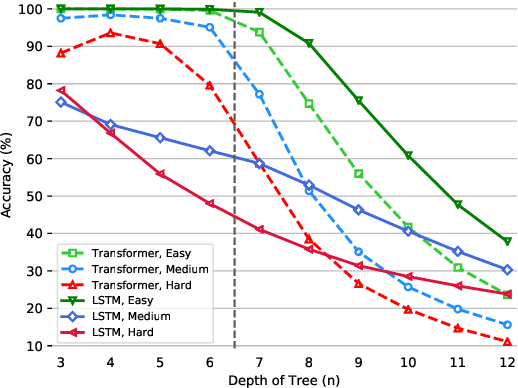
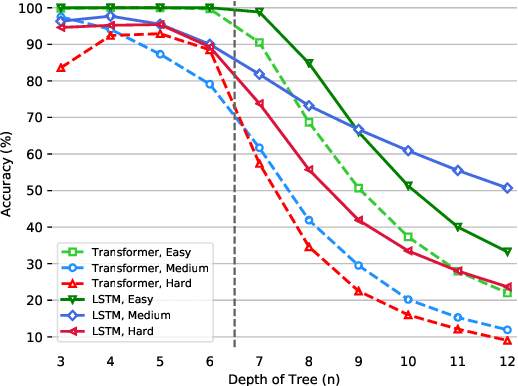
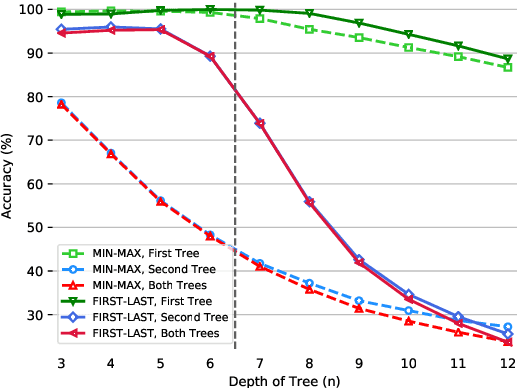
The ability to reason with multiple hierarchical structures is an attractive and desirable property of sequential inductive biases for natural language processing. Do the state-of-the-art Transformers and LSTM architectures implicitly encode for these biases? To answer this, we propose ORCHARD, a diagnostic dataset for systematically evaluating hierarchical reasoning in state-of-the-art neural sequence models. While there have been prior evaluation frameworks such as ListOps or Logical Inference, our work presents a novel and more natural setting where our models learn to reason with multiple explicit hierarchical structures instead of only one, i.e., requiring the ability to do both long-term sequence memorizing, relational reasoning while reasoning with hierarchical structure. Consequently, backed by a set of rigorous experiments, we show that (1) Transformer and LSTM models surprisingly fail in systematic generalization, and (2) with increased references between hierarchies, Transformer performs no better than random.
FastTrees: Parallel Latent Tree-Induction for Faster Sequence Encoding
Nov 28, 2021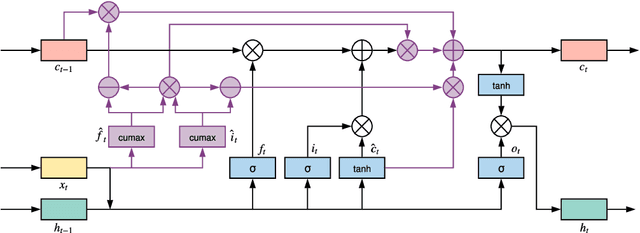
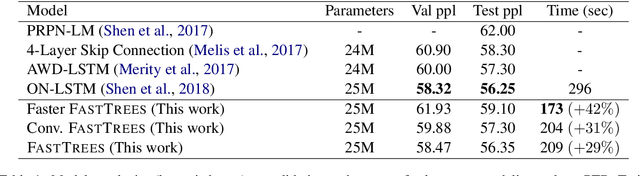
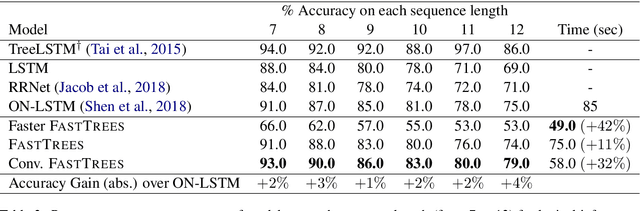
Inducing latent tree structures from sequential data is an emerging trend in the NLP research landscape today, largely popularized by recent methods such as Gumbel LSTM and Ordered Neurons (ON-LSTM). This paper proposes FASTTREES, a new general purpose neural module for fast sequence encoding. Unlike most previous works that consider recurrence to be necessary for tree induction, our work explores the notion of parallel tree induction, i.e., imbuing our model with hierarchical inductive biases in a parallelizable, non-autoregressive fashion. To this end, our proposed FASTTREES achieves competitive or superior performance to ON-LSTM on four well-established sequence modeling tasks, i.e., language modeling, logical inference, sentiment analysis and natural language inference. Moreover, we show that the FASTTREES module can be applied to enhance Transformer models, achieving performance gains on three sequence transduction tasks (machine translation, subject-verb agreement and mathematical language understanding), paving the way for modular tree induction modules. Overall, we outperform existing state-of-the-art models on logical inference tasks by +4% and mathematical language understanding by +8%.