 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMATTERIX: toward a digital twin for robotics-assisted chemistry laboratory automation
Jan 19, 2026Accelerated materials discovery is critical for addressing global challenges. However, developing new laboratory workflows relies heavily on real-world experimental trials, and this can hinder scalability because of the need for numerous physical make-and-test iterations. Here we present MATTERIX, a multiscale, graphics processing unit-accelerated robotic simulation framework designed to create high-fidelity digital twins of chemistry laboratories, thus accelerating workflow development. This multiscale digital twin simulates robotic physical manipulation, powder and liquid dynamics, device functionalities, heat transfer and basic chemical reaction kinetics. This is enabled by integrating realistic physics simulation and photorealistic rendering with a modular graphics processing unit-accelerated semantics engine, which models logical states and continuous behaviors to simulate chemistry workflows across different levels of abstraction. MATTERIX streamlines the creation of digital twin environments through open-source asset libraries and interfaces, while enabling flexible workflow design via hierarchical plan definition and a modular skill library that incorporates learning-based methods. Our approach demonstrates sim-to-real transfer in robotic chemistry setups, reducing reliance on costly real-world experiments and enabling the testing of hypothetical automated workflows in silico. The project website is available at https://accelerationconsortium.github.io/Matterix/ .
ReinforceGen: Hybrid Skill Policies with Automated Data Generation and Reinforcement Learning
Dec 18, 2025Long-horizon manipulation has been a long-standing challenge in the robotics community. We propose ReinforceGen, a system that combines task decomposition, data generation, imitation learning, and motion planning to form an initial solution, and improves each component through reinforcement-learning-based fine-tuning. ReinforceGen first segments the task into multiple localized skills, which are connected through motion planning. The skills and motion planning targets are trained with imitation learning on a dataset generated from 10 human demonstrations, and then fine-tuned through online adaptation and reinforcement learning. When benchmarked on the Robosuite dataset, ReinforceGen reaches 80% success rate on all tasks with visuomotor controls in the highest reset range setting. Additional ablation studies show that our fine-tuning approaches contributes to an 89% average performance increase. More results and videos available in https://reinforcegen.github.io/
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Nov 06, 2025



We present Isaac Lab, the natural successor to Isaac Gym, which extends the paradigm of GPU-native robotics simulation into the era of large-scale multi-modal learning. Isaac Lab combines high-fidelity GPU parallel physics, photorealistic rendering, and a modular, composable architecture for designing environments and training robot policies. Beyond physics and rendering, the framework integrates actuator models, multi-frequency sensor simulation, data collection pipelines, and domain randomization tools, unifying best practices for reinforcement and imitation learning at scale within a single extensible platform. We highlight its application to a diverse set of challenges, including whole-body control, cross-embodiment mobility, contact-rich and dexterous manipulation, and the integration of human demonstrations for skill acquisition. Finally, we discuss upcoming integration with the differentiable, GPU-accelerated Newton physics engine, which promises new opportunities for scalable, data-efficient, and gradient-based approaches to robot learning. We believe Isaac Lab's combination of advanced simulation capabilities, rich sensing, and data-center scale execution will help unlock the next generation of breakthroughs in robotics research.
AMPLIFY: Actionless Motion Priors for Robot Learning from Videos
Jun 17, 2025Action-labeled data for robotics is scarce and expensive, limiting the generalization of learned policies. In contrast, vast amounts of action-free video data are readily available, but translating these observations into effective policies remains a challenge. We introduce AMPLIFY, a novel framework that leverages large-scale video data by encoding visual dynamics into compact, discrete motion tokens derived from keypoint trajectories. Our modular approach separates visual motion prediction from action inference, decoupling the challenges of learning what motion defines a task from how robots can perform it. We train a forward dynamics model on abundant action-free videos and an inverse dynamics model on a limited set of action-labeled examples, allowing for independent scaling. Extensive evaluations demonstrate that the learned dynamics are both accurate, achieving up to 3.7x better MSE and over 2.5x better pixel prediction accuracy compared to prior approaches, and broadly useful. In downstream policy learning, our dynamics predictions enable a 1.2-2.2x improvement in low-data regimes, a 1.4x average improvement by learning from action-free human videos, and the first generalization to LIBERO tasks from zero in-distribution action data. Beyond robotic control, we find the dynamics learned by AMPLIFY to be a versatile latent world model, enhancing video prediction quality. Our results present a novel paradigm leveraging heterogeneous data sources to build efficient, generalizable world models. More information can be found at https://amplify-robotics.github.io/.
SuFIA-BC: Generating High Quality Demonstration Data for Visuomotor Policy Learning in Surgical Subtasks
Apr 21, 2025
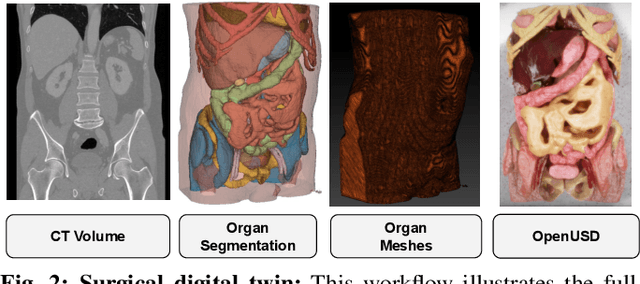
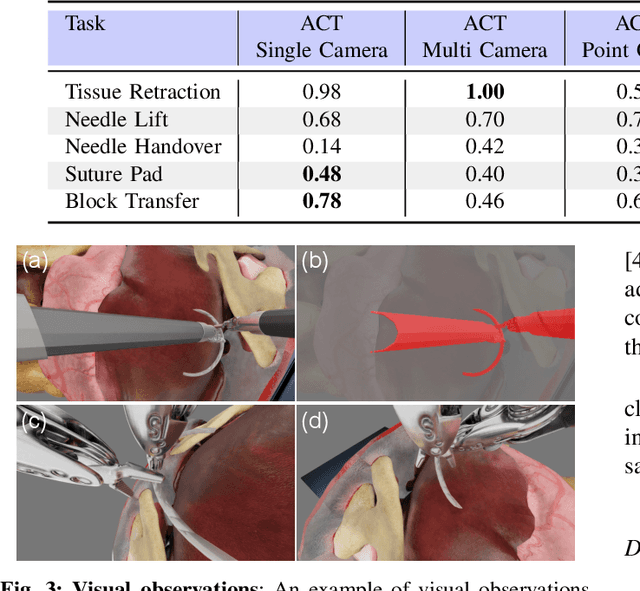

Behavior cloning facilitates the learning of dexterous manipulation skills, yet the complexity of surgical environments, the difficulty and expense of obtaining patient data, and robot calibration errors present unique challenges for surgical robot learning. We provide an enhanced surgical digital twin with photorealistic human anatomical organs, integrated into a comprehensive simulator designed to generate high-quality synthetic data to solve fundamental tasks in surgical autonomy. We present SuFIA-BC: visual Behavior Cloning policies for Surgical First Interactive Autonomy Assistants. We investigate visual observation spaces including multi-view cameras and 3D visual representations extracted from a single endoscopic camera view. Through systematic evaluation, we find that the diverse set of photorealistic surgical tasks introduced in this work enables a comprehensive evaluation of prospective behavior cloning models for the unique challenges posed by surgical environments. We observe that current state-of-the-art behavior cloning techniques struggle to solve the contact-rich and complex tasks evaluated in this work, regardless of their underlying perception or control architectures. These findings highlight the importance of customizing perception pipelines and control architectures, as well as curating larger-scale synthetic datasets that meet the specific demands of surgical tasks. Project website: https://orbit-surgical.github.io/sufia-bc/
Can LLM feedback enhance review quality? A randomized study of 20K reviews at ICLR 2025
Apr 13, 2025Peer review at AI conferences is stressed by rapidly rising submission volumes, leading to deteriorating review quality and increased author dissatisfaction. To address these issues, we developed Review Feedback Agent, a system leveraging multiple large language models (LLMs) to improve review clarity and actionability by providing automated feedback on vague comments, content misunderstandings, and unprofessional remarks to reviewers. Implemented at ICLR 2025 as a large randomized control study, our system provided optional feedback to more than 20,000 randomly selected reviews. To ensure high-quality feedback for reviewers at this scale, we also developed a suite of automated reliability tests powered by LLMs that acted as guardrails to ensure feedback quality, with feedback only being sent to reviewers if it passed all the tests. The results show that 27% of reviewers who received feedback updated their reviews, and over 12,000 feedback suggestions from the agent were incorporated by those reviewers. This suggests that many reviewers found the AI-generated feedback sufficiently helpful to merit updating their reviews. Incorporating AI feedback led to significantly longer reviews (an average increase of 80 words among those who updated after receiving feedback) and more informative reviews, as evaluated by blinded researchers. Moreover, reviewers who were selected to receive AI feedback were also more engaged during paper rebuttals, as seen in longer author-reviewer discussions. This work demonstrates that carefully designed LLM-generated review feedback can enhance peer review quality by making reviews more specific and actionable while increasing engagement between reviewers and authors. The Review Feedback Agent is publicly available at https://github.com/zou-group/review_feedback_agent.
Scaling Laws of Scientific Discovery with AI and Robot Scientists
Mar 28, 2025



The rapid evolution of scientific inquiry highlights an urgent need for groundbreaking methodologies that transcend the limitations of traditional research. Conventional approaches, bogged down by manual processes and siloed expertise, struggle to keep pace with the demands of modern discovery. We envision an autonomous generalist scientist (AGS) system-a fusion of agentic AI and embodied robotics-that redefines the research lifecycle. This system promises to autonomously navigate physical and digital realms, weaving together insights from disparate disciplines with unprecedented efficiency. By embedding advanced AI and robot technologies into every phase-from hypothesis formulation to peer-ready manuscripts-AGS could slash the time and resources needed for scientific research in diverse field. We foresee a future where scientific discovery follows new scaling laws, driven by the proliferation and sophistication of such systems. As these autonomous agents and robots adapt to extreme environments and leverage a growing reservoir of knowledge, they could spark a paradigm shift, pushing the boundaries of what's possible and ushering in an era of relentless innovation.
Adapt3R: Adaptive 3D Scene Representation for Domain Transfer in Imitation Learning
Mar 06, 2025Imitation Learning (IL) has been very effective in training robots to perform complex and diverse manipulation tasks. However, its performance declines precipitously when the observations are out of the training distribution. 3D scene representations that incorporate observations from calibrated RGBD cameras have been proposed as a way to improve generalizability of IL policies, but our evaluations in cross-embodiment and novel camera pose settings found that they show only modest improvement. To address those challenges, we propose Adaptive 3D Scene Representation (Adapt3R), a general-purpose 3D observation encoder which uses a novel architecture to synthesize data from one or more RGBD cameras into a single vector that can then be used as conditioning for arbitrary IL algorithms. The key idea is to use a pretrained 2D backbone to extract semantic information about the scene, using 3D only as a medium for localizing this semantic information with respect to the end-effector. We show that when trained end-to-end with several SOTA multi-task IL algorithms, Adapt3R maintains these algorithms' multi-task learning capacity while enabling zero-shot transfer to novel embodiments and camera poses. Furthermore, we provide a detailed suite of ablation and sensitivity experiments to elucidate the design space for point cloud observation encoders.
AnyPlace: Learning Generalized Object Placement for Robot Manipulation
Feb 06, 2025Object placement in robotic tasks is inherently challenging due to the diversity of object geometries and placement configurations. To address this, we propose AnyPlace, a two-stage method trained entirely on synthetic data, capable of predicting a wide range of feasible placement poses for real-world tasks. Our key insight is that by leveraging a Vision-Language Model (VLM) to identify rough placement locations, we focus only on the relevant regions for local placement, which enables us to train the low-level placement-pose-prediction model to capture diverse placements efficiently. For training, we generate a fully synthetic dataset of randomly generated objects in different placement configurations (insertion, stacking, hanging) and train local placement-prediction models. We conduct extensive evaluations in simulation, demonstrating that our method outperforms baselines in terms of success rate, coverage of possible placement modes, and precision. In real-world experiments, we show how our approach directly transfers models trained purely on synthetic data to the real world, where it successfully performs placements in scenarios where other models struggle -- such as with varying object geometries, diverse placement modes, and achieving high precision for fine placement. More at: https://any-place.github.io.
Accelerating Discovery in Natural Science Laboratories with AI and Robotics: Perspectives and Challenges from the 2024 IEEE ICRA Workshop, Yokohama, Japan
Jan 12, 2025

Science laboratory automation enables accelerated discovery in life sciences and materials. However, it requires interdisciplinary collaboration to address challenges such as robust and flexible autonomy, reproducibility, throughput, standardization, the role of human scientists, and ethics. This article highlights these issues, reflecting perspectives from leading experts in laboratory automation across different disciplines of the natural sciences.