 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-centered mechanism design with Democratic AI
Jan 27, 2022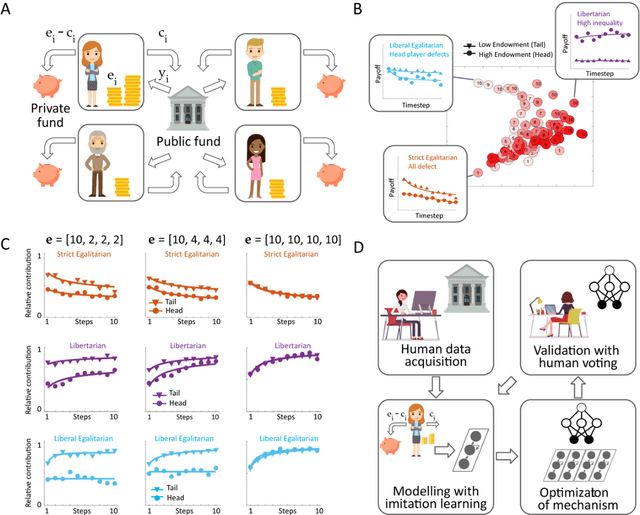
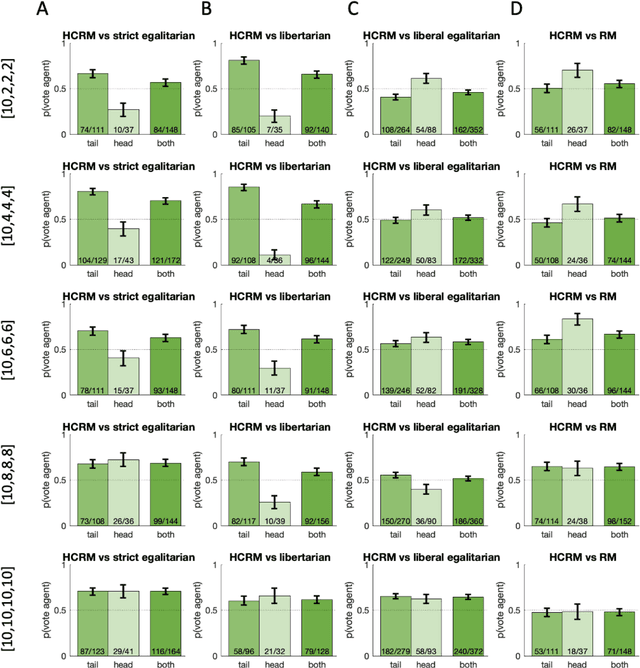
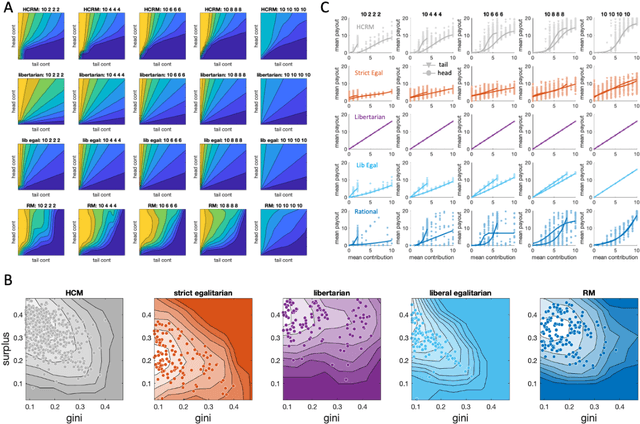
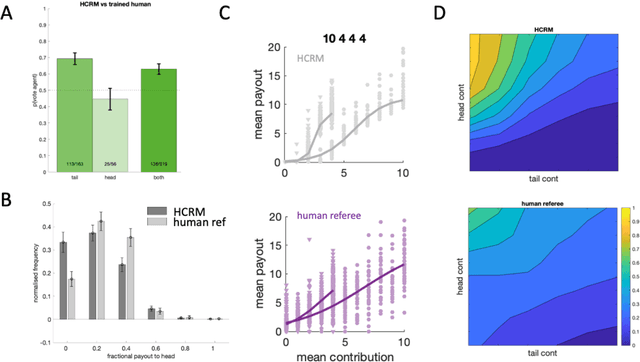
Building artificial intelligence (AI) that aligns with human values is an unsolved problem. Here, we developed a human-in-the-loop research pipeline called Democratic AI, in which reinforcement learning is used to design a social mechanism that humans prefer by majority. A large group of humans played an online investment game that involved deciding whether to keep a monetary endowment or to share it with others for collective benefit. Shared revenue was returned to players under two different redistribution mechanisms, one designed by the AI and the other by humans. The AI discovered a mechanism that redressed initial wealth imbalance, sanctioned free riders, and successfully won the majority vote. By optimizing for human preferences, Democratic AI may be a promising method for value-aligned policy innovation.
Learning to Play No-Press Diplomacy with Best Response Policy Iteration
Jun 17, 2020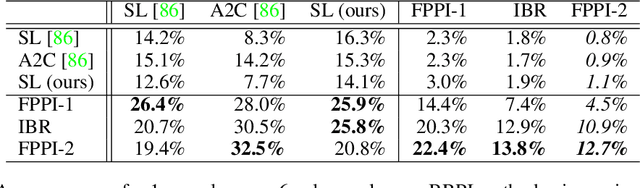
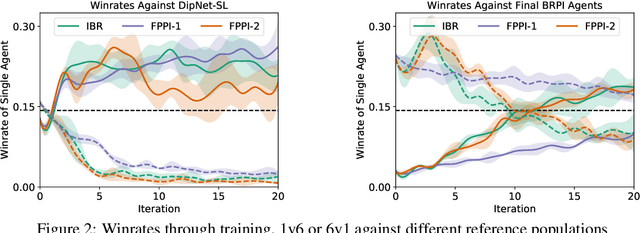
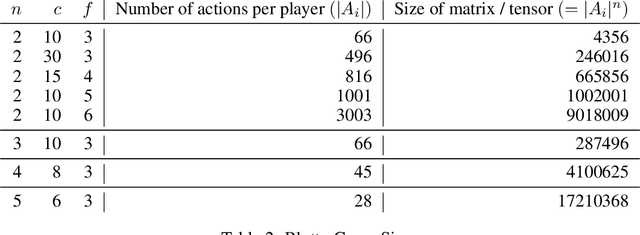
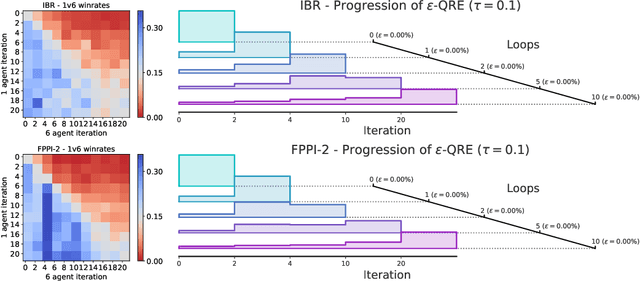
Recent advances in deep reinforcement learning (RL) have led to considerable progress in many 2-player zero-sum games, such as Go, Poker and Starcraft. The purely adversarial nature of such games allows for conceptually simple and principled application of RL methods. However real-world settings are many-agent, and agent interactions are complex mixtures of common-interest and competitive aspects. We consider Diplomacy, a 7-player board game designed to accentuate dilemmas resulting from many-agent interactions. It also features a large combinatorial action space and simultaneous moves, which are challenging for RL algorithms. We propose a simple yet effective approximate best response operator, designed to handle large combinatorial action spaces and simultaneous moves. We also introduce a family of policy iteration methods that approximate fictitious play. With these methods, we successfully apply RL to Diplomacy: we show that our agents convincingly outperform the previous state-of-the-art, and game theoretic equilibrium analysis shows that the new process yields consistent improvements.
A Neural Architecture for Designing Truthful and Efficient Auctions
Jul 11, 2019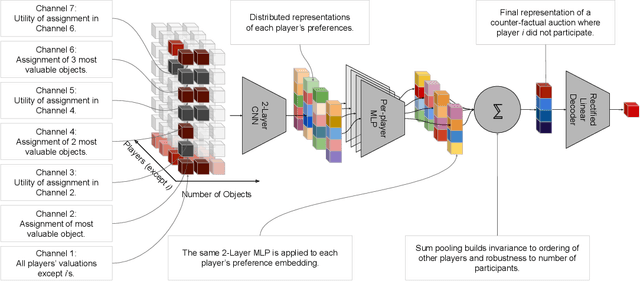
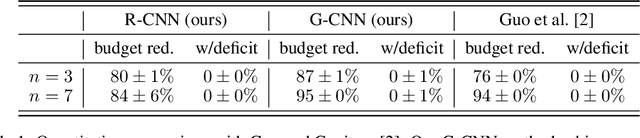
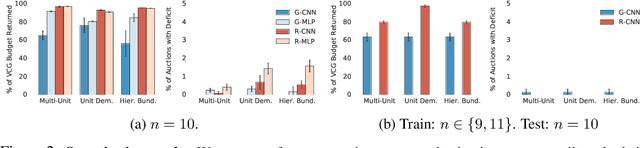
Auctions are protocols to allocate goods to buyers who have preferences over them, and collect payments in return. Economists have invested significant effort in designing auction rules that result in allocations of the goods that are desirable for the group as a whole. However, for settings where participants' valuations of the items on sale are their private information, the rules of the auction must deter buyers from misreporting their preferences, so as to maximize their own utility, since misreported preferences hinder the ability for the auctioneer to allocate goods to those who want them most. Manual auction design has yielded excellent mechanisms for specific settings, but requires significant effort when tackling new domains. We propose a deep learning based approach to automatically design auctions in a wide variety of domains, shifting the design work from human to machine. We assume that participants' valuations for the items for sale are independently sampled from an unknown but fixed distribution. Our system receives a data-set consisting of such valuation samples, and outputs an auction rule encoding the desired incentive structure. We focus on producing truthful and efficient auctions that minimize the economic burden on participants. We evaluate the auctions designed by our framework on well-studied domains, such as multi-unit and combinatorial auctions, showing that they outperform known auction designs in terms of the economic burden placed on participants.
Relational inductive biases, deep learning, and graph networks
Oct 17, 2018
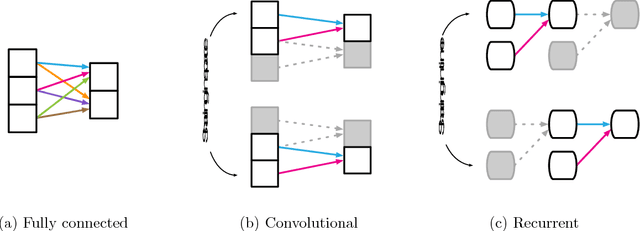
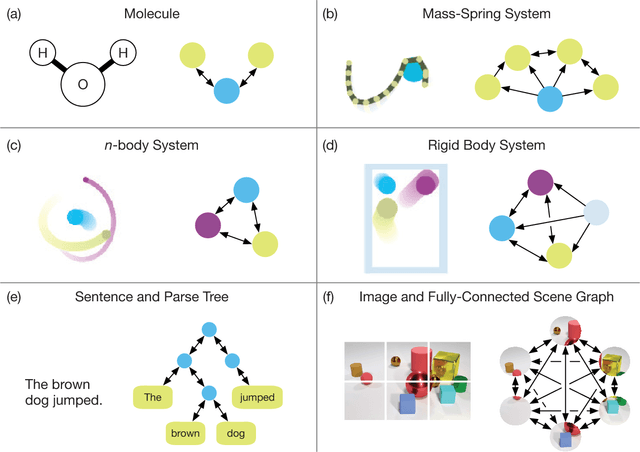
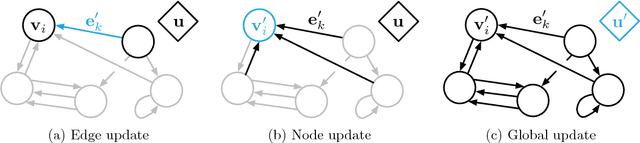
Artificial intelligence (AI) has undergone a renaissance recently, making major progress in key domains such as vision, language, control, and decision-making. This has been due, in part, to cheap data and cheap compute resources, which have fit the natural strengths of deep learning. However, many defining characteristics of human intelligence, which developed under much different pressures, remain out of reach for current approaches. In particular, generalizing beyond one's experiences--a hallmark of human intelligence from infancy--remains a formidable challenge for modern AI. The following is part position paper, part review, and part unification. We argue that combinatorial generalization must be a top priority for AI to achieve human-like abilities, and that structured representations and computations are key to realizing this objective. Just as biology uses nature and nurture cooperatively, we reject the false choice between "hand-engineering" and "end-to-end" learning, and instead advocate for an approach which benefits from their complementary strengths. We explore how using relational inductive biases within deep learning architectures can facilitate learning about entities, relations, and rules for composing them. We present a new building block for the AI toolkit with a strong relational inductive bias--the graph network--which generalizes and extends various approaches for neural networks that operate on graphs, and provides a straightforward interface for manipulating structured knowledge and producing structured behaviors. We discuss how graph networks can support relational reasoning and combinatorial generalization, laying the foundation for more sophisticated, interpretable, and flexible patterns of reasoning. As a companion to this paper, we have released an open-source software library for building graph networks, with demonstrations of how to use them in practice.
Relational Forward Models for Multi-Agent Learning
Sep 28, 2018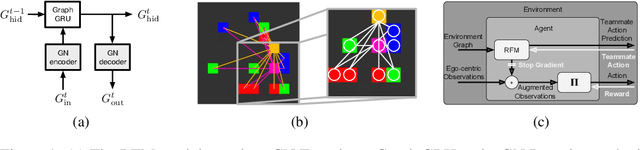
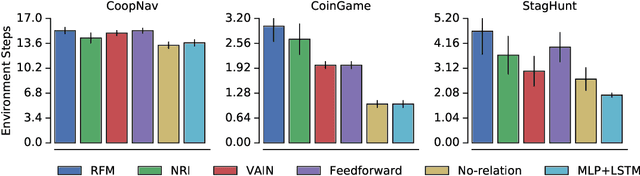
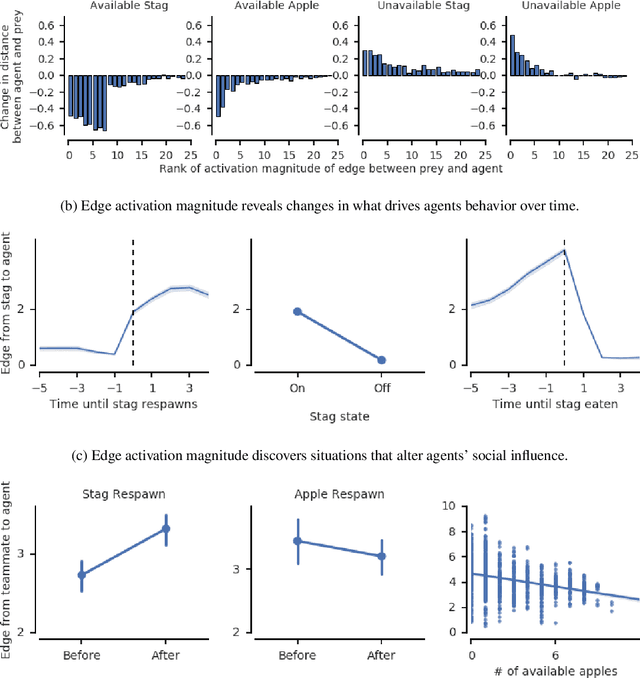
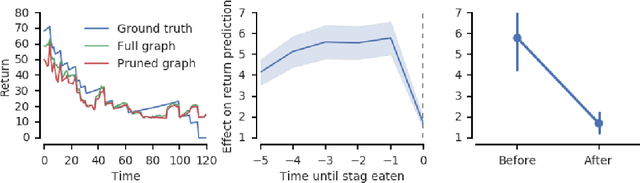
The behavioral dynamics of multi-agent systems have a rich and orderly structure, which can be leveraged to understand these systems, and to improve how artificial agents learn to operate in them. Here we introduce Relational Forward Models (RFM) for multi-agent learning, networks that can learn to make accurate predictions of agents' future behavior in multi-agent environments. Because these models operate on the discrete entities and relations present in the environment, they produce interpretable intermediate representations which offer insights into what drives agents' behavior, and what events mediate the intensity and valence of social interactions. Furthermore, we show that embedding RFM modules inside agents results in faster learning systems compared to non-augmented baselines. As more and more of the autonomous systems we develop and interact with become multi-agent in nature, developing richer analysis tools for characterizing how and why agents make decisions is increasingly necessary. Moreover, developing artificial agents that quickly and safely learn to coordinate with one another, and with humans in shared environments, is crucial.
Visual Interaction Networks
Jun 05, 2017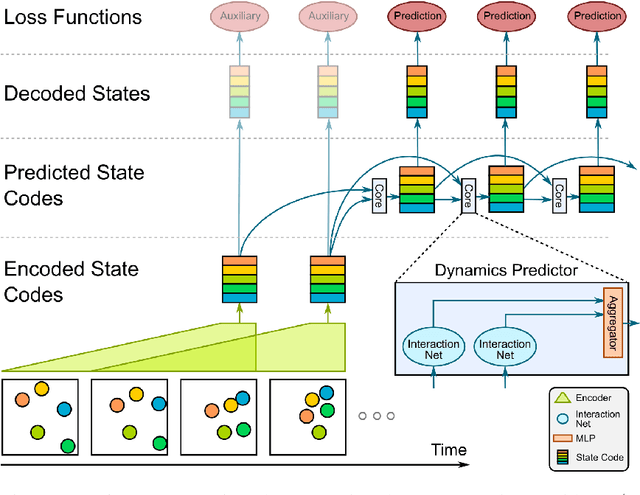

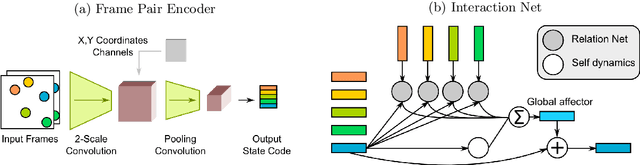
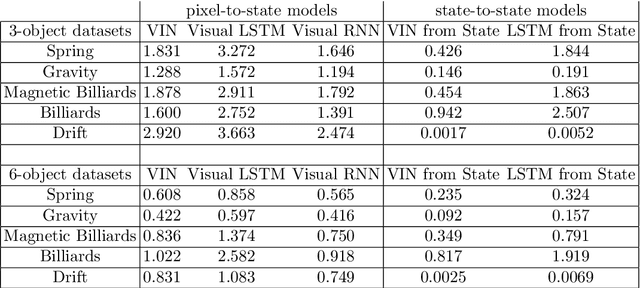
From just a glance, humans can make rich predictions about the future state of a wide range of physical systems. On the other hand, modern approaches from engineering, robotics, and graphics are often restricted to narrow domains and require direct measurements of the underlying states. We introduce the Visual Interaction Network, a general-purpose model for learning the dynamics of a physical system from raw visual observations. Our model consists of a perceptual front-end based on convolutional neural networks and a dynamics predictor based on interaction networks. Through joint training, the perceptual front-end learns to parse a dynamic visual scene into a set of factored latent object representations. The dynamics predictor learns to roll these states forward in time by computing their interactions and dynamics, producing a predicted physical trajectory of arbitrary length. We found that from just six input video frames the Visual Interaction Network can generate accurate future trajectories of hundreds of time steps on a wide range of physical systems. Our model can also be applied to scenes with invisible objects, inferring their future states from their effects on the visible objects, and can implicitly infer the unknown mass of objects. Our results demonstrate that the perceptual module and the object-based dynamics predictor module can induce factored latent representations that support accurate dynamical predictions. This work opens new opportunities for model-based decision-making and planning from raw sensory observations in complex physical environments.
Discriminate-and-Rectify Encoders: Learning from Image Transformation Sets
Mar 14, 2017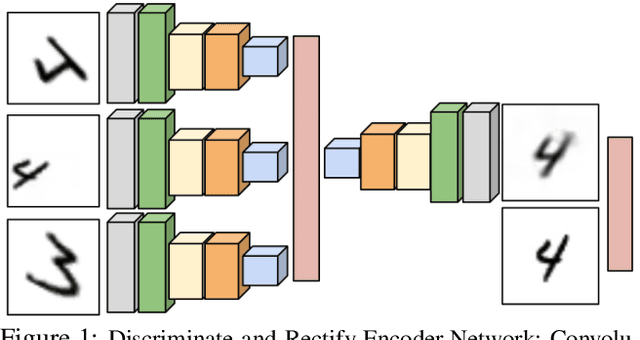



The complexity of a learning task is increased by transformations in the input space that preserve class identity. Visual object recognition for example is affected by changes in viewpoint, scale, illumination or planar transformations. While drastically altering the visual appearance, these changes are orthogonal to recognition and should not be reflected in the representation or feature encoding used for learning. We introduce a framework for weakly supervised learning of image embeddings that are robust to transformations and selective to the class distribution, using sets of transforming examples (orbit sets), deep parametrizations and a novel orbit-based loss. The proposed loss combines a discriminative, contrastive part for orbits with a reconstruction error that learns to rectify orbit transformations. The learned embeddings are evaluated in distance metric-based tasks, such as one-shot classification under geometric transformations, as well as face verification and retrieval under more realistic visual variability. Our results suggest that orbit sets, suitably computed or observed, can be used for efficient, weakly-supervised learning of semantically relevant image embeddings.
Unsupervised Learning of Invariant Representations in Hierarchical Architectures
Mar 11, 2014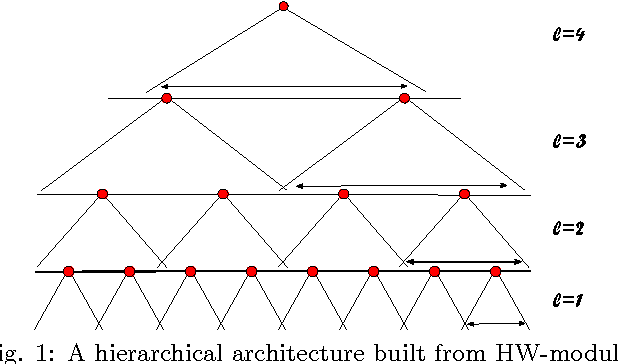
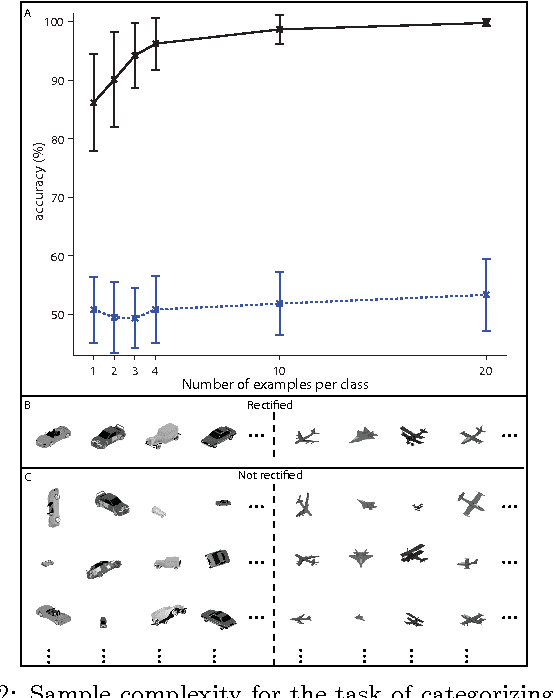

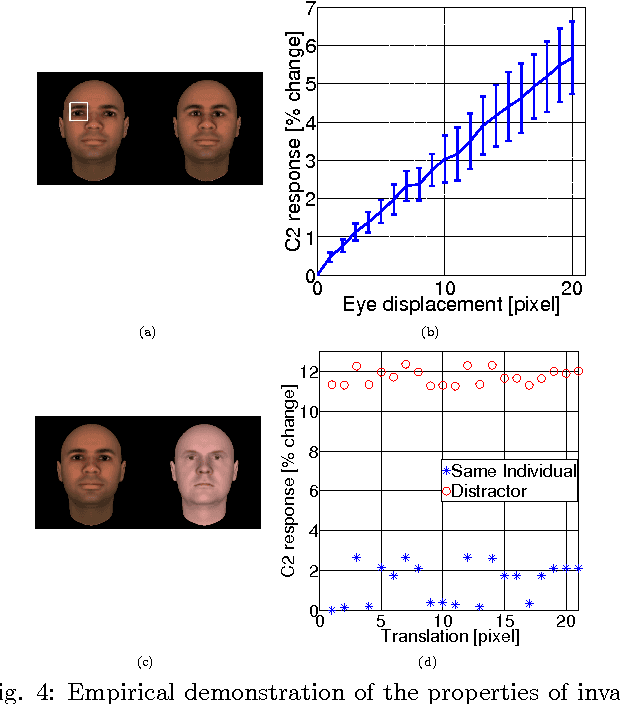
The present phase of Machine Learning is characterized by supervised learning algorithms relying on large sets of labeled examples ($n \to \infty$). The next phase is likely to focus on algorithms capable of learning from very few labeled examples ($n \to 1$), like humans seem able to do. We propose an approach to this problem and describe the underlying theory, based on the unsupervised, automatic learning of a ``good'' representation for supervised learning, characterized by small sample complexity ($n$). We consider the case of visual object recognition though the theory applies to other domains. The starting point is the conjecture, proved in specific cases, that image representations which are invariant to translations, scaling and other transformations can considerably reduce the sample complexity of learning. We prove that an invariant and unique (discriminative) signature can be computed for each image patch, $I$, in terms of empirical distributions of the dot-products between $I$ and a set of templates stored during unsupervised learning. A module performing filtering and pooling, like the simple and complex cells described by Hubel and Wiesel, can compute such estimates. Hierarchical architectures consisting of this basic Hubel-Wiesel moduli inherit its properties of invariance, stability, and discriminability while capturing the compositional organization of the visual world in terms of wholes and parts. The theory extends existing deep learning convolutional architectures for image and speech recognition. It also suggests that the main computational goal of the ventral stream of visual cortex is to provide a hierarchical representation of new objects/images which is invariant to transformations, stable, and discriminative for recognition---and that this representation may be continuously learned in an unsupervised way during development and visual experience.
GURLS: a Least Squares Library for Supervised Learning
Mar 05, 2013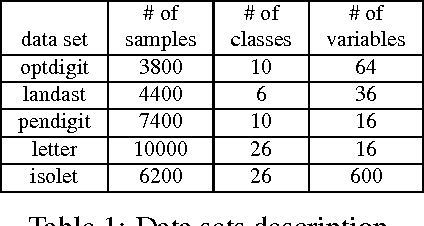
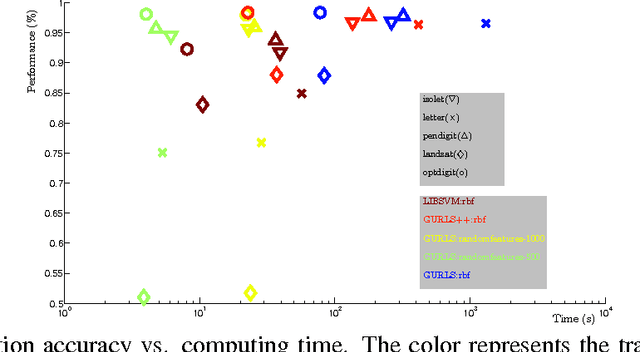
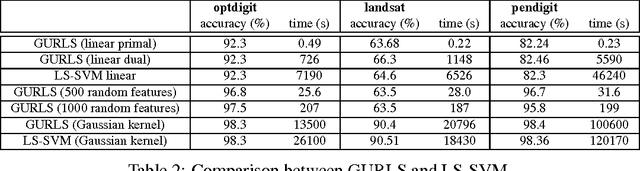
We present GURLS, a least squares, modular, easy-to-extend software library for efficient supervised learning. GURLS is targeted to machine learning practitioners, as well as non-specialists. It offers a number state-of-the-art training strategies for medium and large-scale learning, and routines for efficient model selection. The library is particularly well suited for multi-output problems (multi-category/multi-label). GURLS is currently available in two independent implementations: Matlab and C++. It takes advantage of the favorable properties of regularized least squares algorithm to exploit advanced tools in linear algebra. Routines to handle computations with very large matrices by means of memory-mapped storage and distributed task execution are available. The package is distributed under the BSD licence and is available for download at https://github.com/CBCL/GURLS.