 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning of Invariant Representations in Hierarchical Architectures
Paper and Code
Mar 11, 2014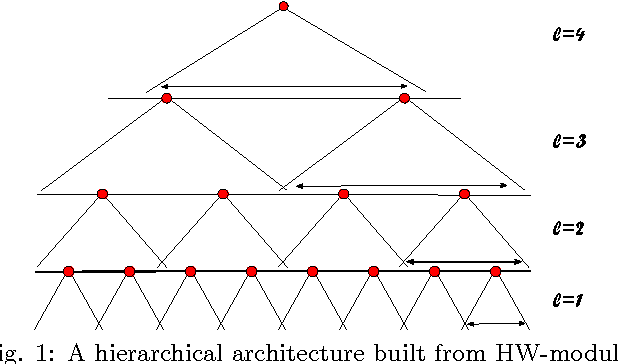
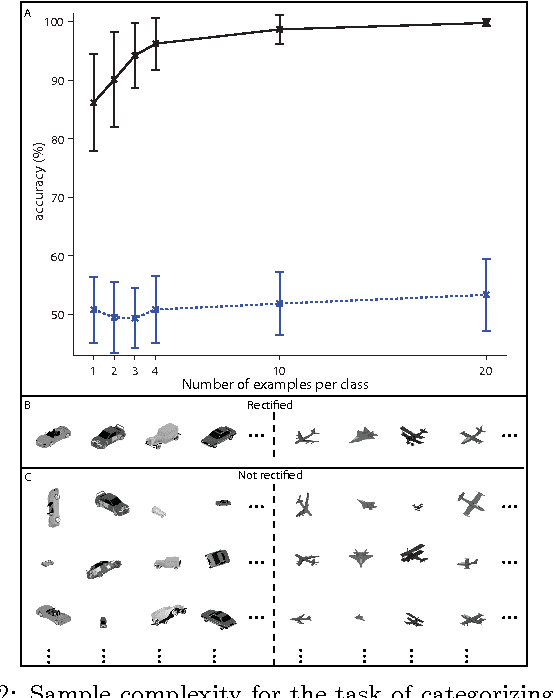

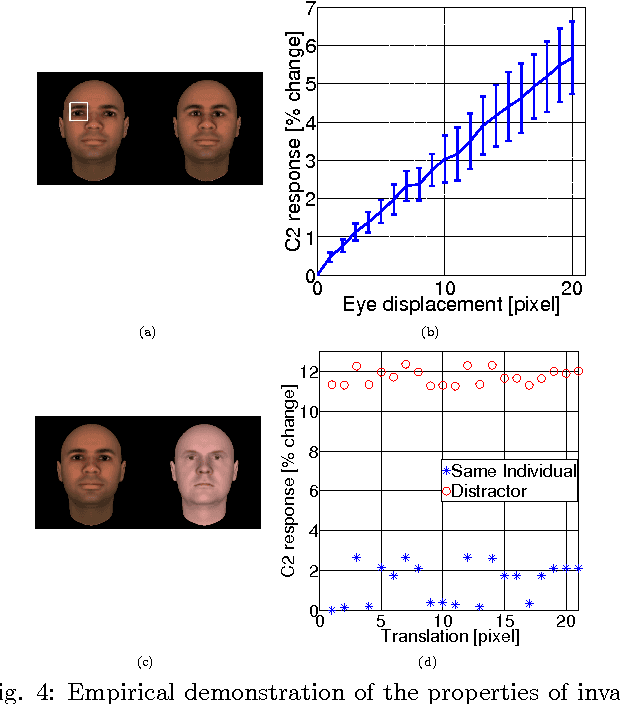
The present phase of Machine Learning is characterized by supervised learning algorithms relying on large sets of labeled examples ($n \to \infty$). The next phase is likely to focus on algorithms capable of learning from very few labeled examples ($n \to 1$), like humans seem able to do. We propose an approach to this problem and describe the underlying theory, based on the unsupervised, automatic learning of a ``good'' representation for supervised learning, characterized by small sample complexity ($n$). We consider the case of visual object recognition though the theory applies to other domains. The starting point is the conjecture, proved in specific cases, that image representations which are invariant to translations, scaling and other transformations can considerably reduce the sample complexity of learning. We prove that an invariant and unique (discriminative) signature can be computed for each image patch, $I$, in terms of empirical distributions of the dot-products between $I$ and a set of templates stored during unsupervised learning. A module performing filtering and pooling, like the simple and complex cells described by Hubel and Wiesel, can compute such estimates. Hierarchical architectures consisting of this basic Hubel-Wiesel moduli inherit its properties of invariance, stability, and discriminability while capturing the compositional organization of the visual world in terms of wholes and parts. The theory extends existing deep learning convolutional architectures for image and speech recognition. It also suggests that the main computational goal of the ventral stream of visual cortex is to provide a hierarchical representation of new objects/images which is invariant to transformations, stable, and discriminative for recognition---and that this representation may be continuously learned in an unsupervised way during development and visual experience.