 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-FedAvg: Learnable Federated Averaging for Multi-Institutional Medical Image Segmentation
Apr 20, 2021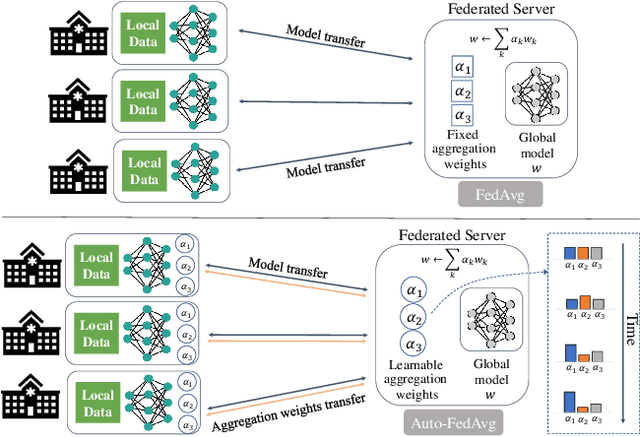
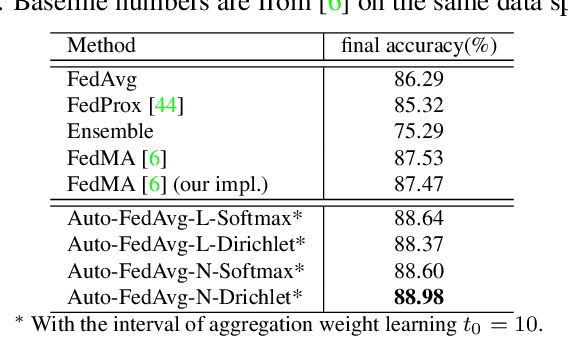
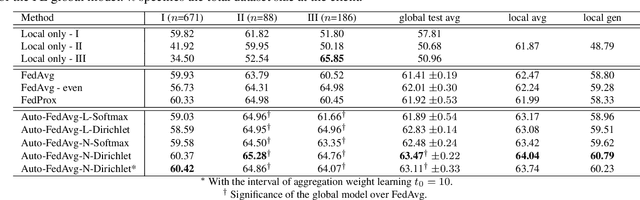
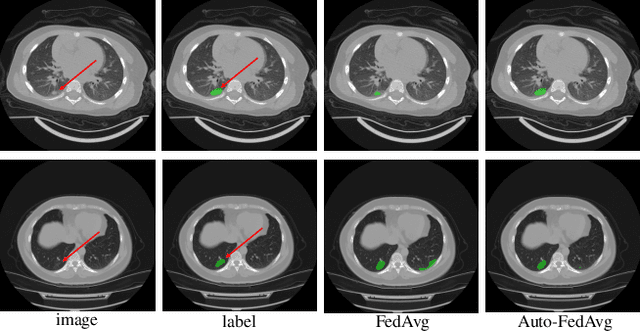
Federated learning (FL) enables collaborative model training while preserving each participant's privacy, which is particularly beneficial to the medical field. FedAvg is a standard algorithm that uses fixed weights, often originating from the dataset sizes at each client, to aggregate the distributed learned models on a server during the FL process. However, non-identical data distribution across clients, known as the non-i.i.d problem in FL, could make this assumption for setting fixed aggregation weights sub-optimal. In this work, we design a new data-driven approach, namely Auto-FedAvg, where aggregation weights are dynamically adjusted, depending on data distributions across data silos and the current training progress of the models. We disentangle the parameter set into two parts, local model parameters and global aggregation parameters, and update them iteratively with a communication-efficient algorithm. We first show the validity of our approach by outperforming state-of-the-art FL methods for image recognition on a heterogeneous data split of CIFAR-10. Furthermore, we demonstrate our algorithm's effectiveness on two multi-institutional medical image analysis tasks, i.e., COVID-19 lesion segmentation in chest CT and pancreas segmentation in abdominal CT.
Self-Supervised Pillar Motion Learning for Autonomous Driving
Apr 18, 2021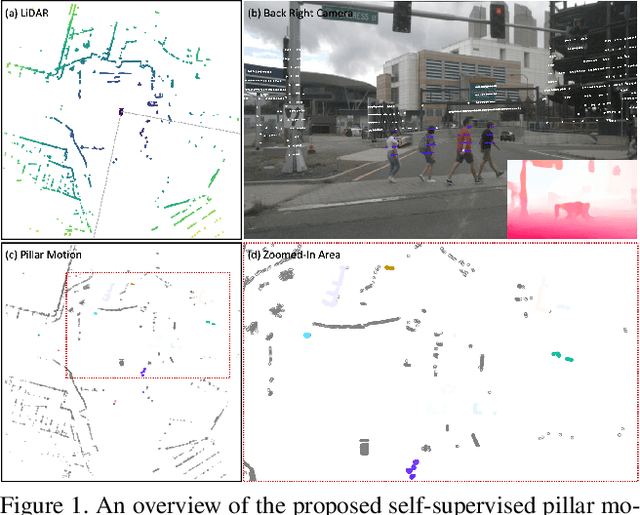

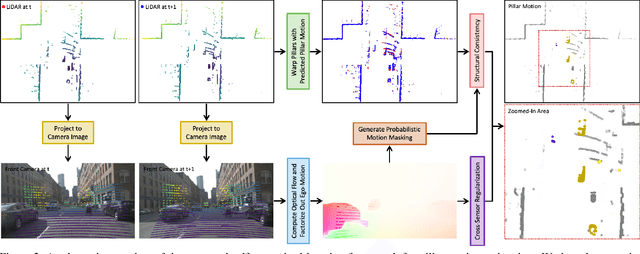

Autonomous driving can benefit from motion behavior comprehension when interacting with diverse traffic participants in highly dynamic environments. Recently, there has been a growing interest in estimating class-agnostic motion directly from point clouds. Current motion estimation methods usually require vast amount of annotated training data from self-driving scenes. However, manually labeling point clouds is notoriously difficult, error-prone and time-consuming. In this paper, we seek to answer the research question of whether the abundant unlabeled data collections can be utilized for accurate and efficient motion learning. To this end, we propose a learning framework that leverages free supervisory signals from point clouds and paired camera images to estimate motion purely via self-supervision. Our model involves a point cloud based structural consistency augmented with probabilistic motion masking as well as a cross-sensor motion regularization to realize the desired self-supervision. Experiments reveal that our approach performs competitively to supervised methods, and achieves the state-of-the-art result when combining our self-supervised model with supervised fine-tuning.
A-SDF: Learning Disentangled Signed Distance Functions for Articulated Shape Representation
Apr 15, 2021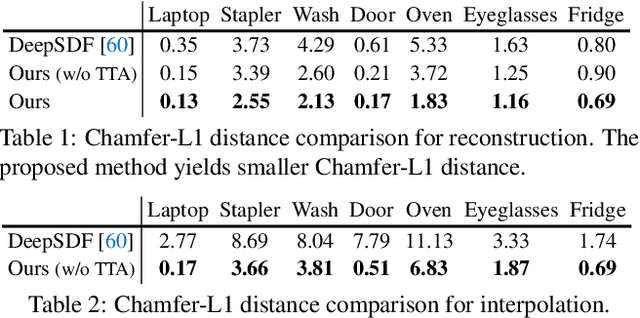
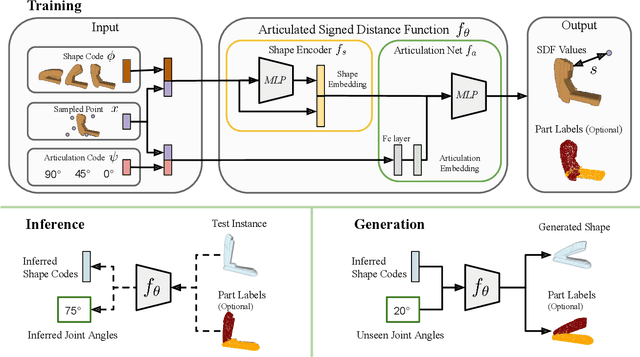
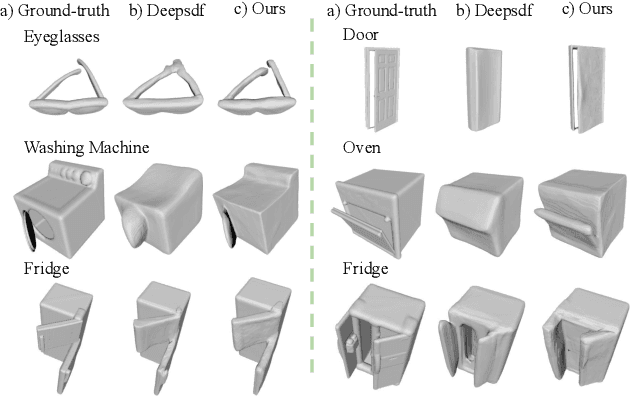

Recent work has made significant progress on using implicit functions, as a continuous representation for 3D rigid object shape reconstruction. However, much less effort has been devoted to modeling general articulated objects. Compared to rigid objects, articulated objects have higher degrees of freedom, which makes it hard to generalize to unseen shapes. To deal with the large shape variance, we introduce Articulated Signed Distance Functions (A-SDF) to represent articulated shapes with a disentangled latent space, where we have separate codes for encoding shape and articulation. We assume no prior knowledge on part geometry, articulation status, joint type, joint axis, and joint location. With this disentangled continuous representation, we demonstrate that we can control the articulation input and animate unseen instances with unseen joint angles. Furthermore, we propose a Test-Time Adaptation inference algorithm to adjust our model during inference. We demonstrate our model generalize well to out-of-distribution and unseen data, e.g., partial point clouds and real-world depth images.
DualNorm-UNet: Incorporating Global and Local Statistics for Robust Medical Image Segmentation
Mar 29, 2021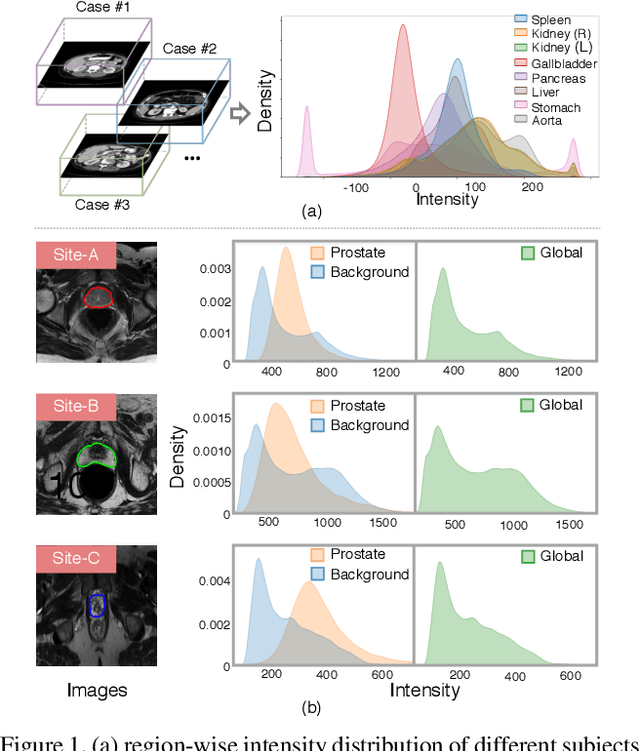
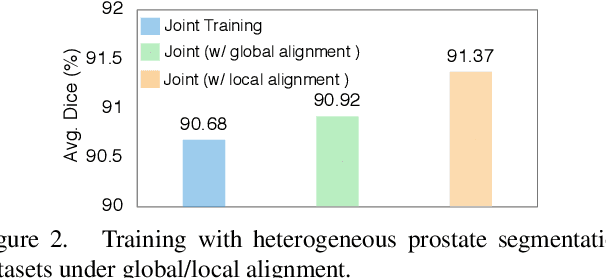
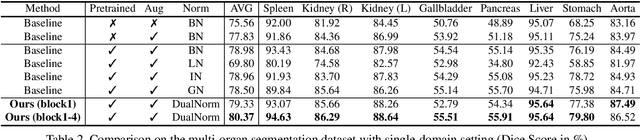
Batch Normalization (BN) is one of the key components for accelerating network training, and has been widely adopted in the medical image analysis field. However, BN only calculates the global statistics at the batch level, and applies the same affine transformation uniformly across all spatial coordinates, which would suppress the image contrast of different semantic structures. In this paper, we propose to incorporate the semantic class information into normalization layers, so that the activations corresponding to different regions (i.e., classes) can be modulated differently. We thus develop a novel DualNorm-UNet, to concurrently incorporate both global image-level statistics and local region-wise statistics for network normalization. Specifically, the local statistics are integrated by adaptively modulating the activations along different class regions via the learned semantic masks in the normalization layer. Compared with existing methods, our approach exploits semantic knowledge at normalization and yields more discriminative features for robust segmentation results. More importantly, our network demonstrates superior abilities in capturing domain-invariant information from multiple domains (institutions) of medical data. Extensive experiments show that our proposed DualNorm-UNet consistently improves the performance on various segmentation tasks, even in the face of more complex and variable data distributions. Code is available at https://github.com/lambert-x/DualNorm-Unet.
TransFG: A Transformer Architecture for Fine-grained Recognition
Mar 28, 2021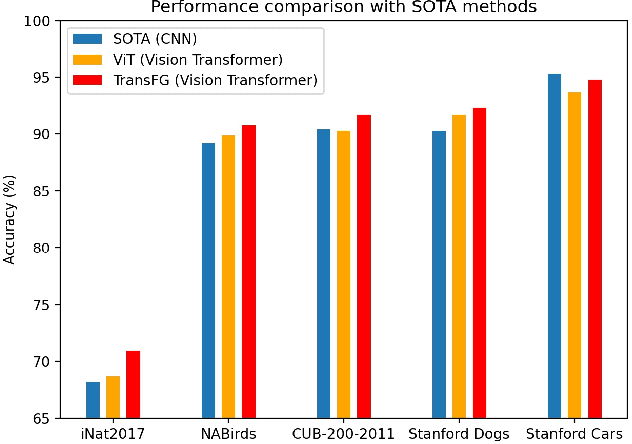
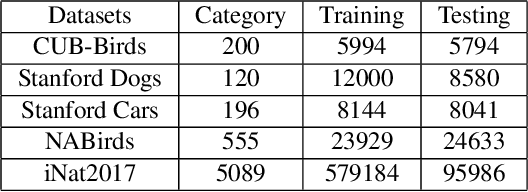
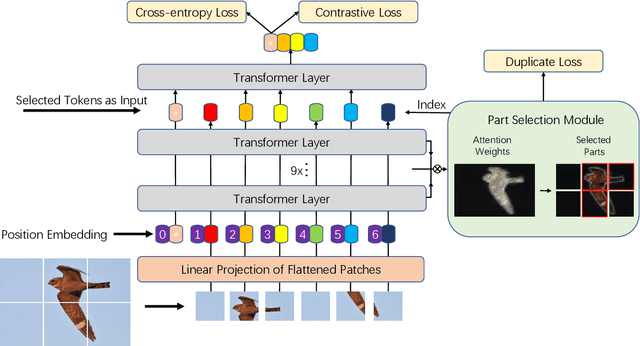
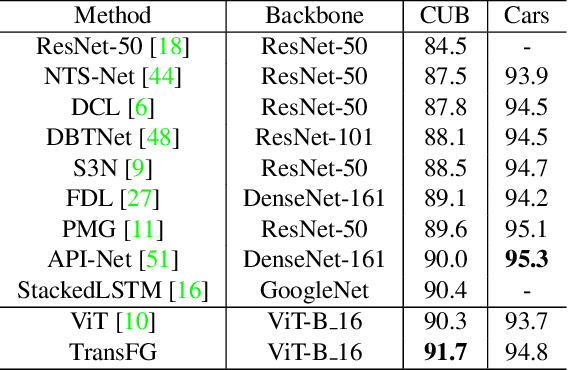
Fine-grained visual classification (FGVC) which aims at recognizing objects from subcategories is a very challenging task due to the inherently subtle inter-class differences. Recent works mainly tackle this problem by focusing on how to locate the most discriminative image regions and rely on them to improve the capability of networks to capture subtle variances. Most of these works achieve this by re-using the backbone network to extract features of selected regions. However, this strategy inevitably complicates the pipeline and pushes the proposed regions to contain most parts of the objects. Recently, vision transformer (ViT) shows its strong performance in the traditional classification task. The self-attention mechanism of the transformer links every patch token to the classification token. The strength of the attention link can be intuitively considered as an indicator of the importance of tokens. In this work, we propose a novel transformer-based framework TransFG where we integrate all raw attention weights of the transformer into an attention map for guiding the network to effectively and accurately select discriminative image patches and compute their relations. A contrastive loss is applied to further enlarge the distance between feature representations of similar sub-classes. We demonstrate the value of TransFG by conducting experiments on five popular fine-grained benchmarks: CUB-200-2011, Stanford Cars, Stanford Dogs, NABirds and iNat2017 where we achieve state-of-the-art performance. Qualitative results are presented for better understanding of our model. Code is available at https://github.com/TACJu/TransFG.
CGPart: A Part Segmentation Dataset Based on 3D Computer Graphics Models
Mar 25, 2021
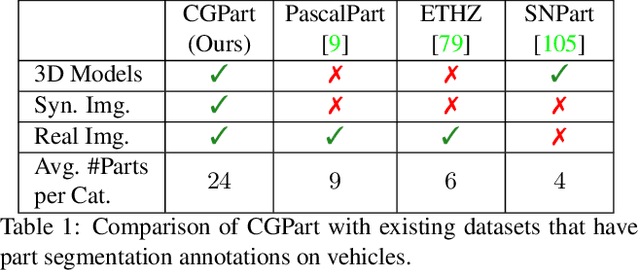
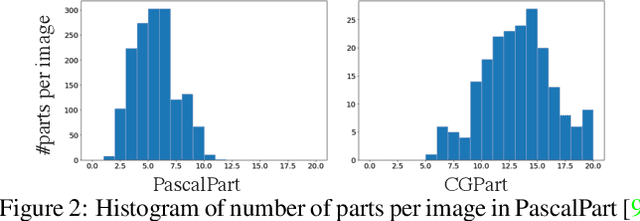
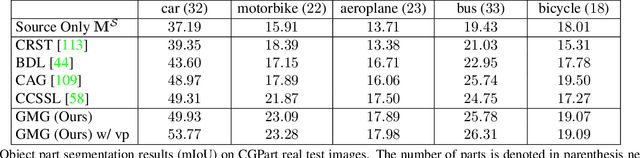
Part segmentations provide a rich and detailed part-level description of objects, but their annotation requires an enormous amount of work. In this paper, we introduce CGPart, a comprehensive part segmentation dataset that provides detailed annotations on 3D CAD models, synthetic images, and real test images. CGPart includes $21$ 3D CAD models covering $5$ vehicle categories, each with detailed per-mesh part labeling. The average number of parts per category is $24$, which is larger than any existing datasets for part segmentation on vehicle objects. By varying the rendering parameters, we make $168,000$ synthetic images from these CAD models, each with automatically generated part segmentation ground-truth. We also annotate part segmentations on $200$ real images for evaluation purposes. To illustrate the value of CGPart, we apply it to image part segmentation through unsupervised domain adaptation (UDA). We evaluate several baseline methods by adapting top-performing UDA algorithms from related tasks to part segmentation. Moreover, we introduce a new method called Geometric-Matching Guided domain adaptation (GMG), which leverages the spatial object structure to guide the knowledge transfer from the synthetic to the real images. Experimental results demonstrate the advantage of our new algorithm and reveal insights for future improvement. We will release our data and code.
Weakly Supervised Instance Segmentation for Videos with Temporal Mask Consistency
Mar 23, 2021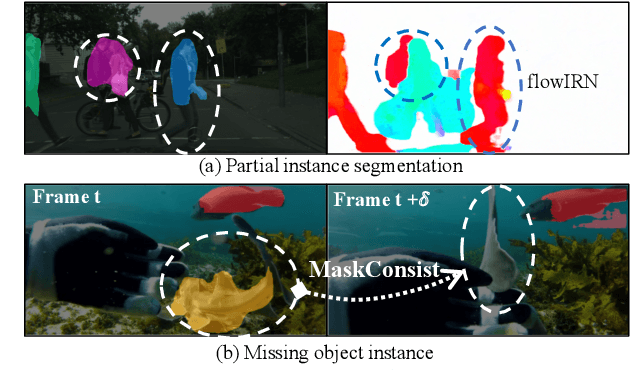
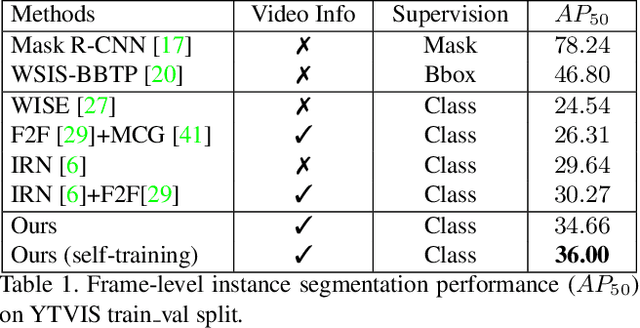
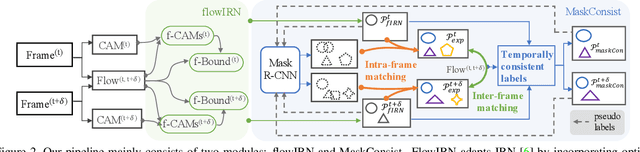
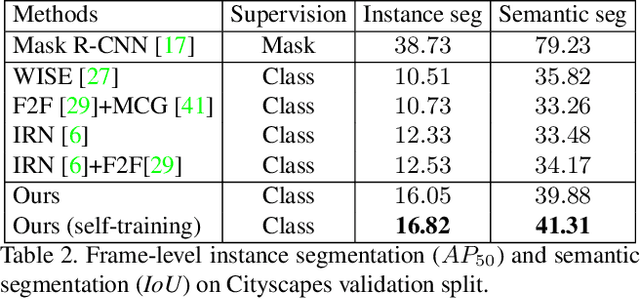
Weakly supervised instance segmentation reduces the cost of annotations required to train models. However, existing approaches which rely only on image-level class labels predominantly suffer from errors due to (a) partial segmentation of objects and (b) missing object predictions. We show that these issues can be better addressed by training with weakly labeled videos instead of images. In videos, motion and temporal consistency of predictions across frames provide complementary signals which can help segmentation. We are the first to explore the use of these video signals to tackle weakly supervised instance segmentation. We propose two ways to leverage this information in our model. First, we adapt inter-pixel relation network (IRN) to effectively incorporate motion information during training. Second, we introduce a new MaskConsist module, which addresses the problem of missing object instances by transferring stable predictions between neighboring frames during training. We demonstrate that both approaches together improve the instance segmentation metric $AP_{50}$ on video frames of two datasets: Youtube-VIS and Cityscapes by $5\%$ and $3\%$ respectively.
Understanding Catastrophic Forgetting and Remembering in Continual Learning with Optimal Relevance Mapping
Feb 22, 2021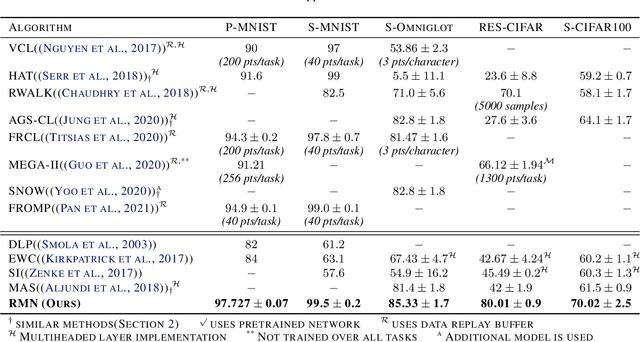
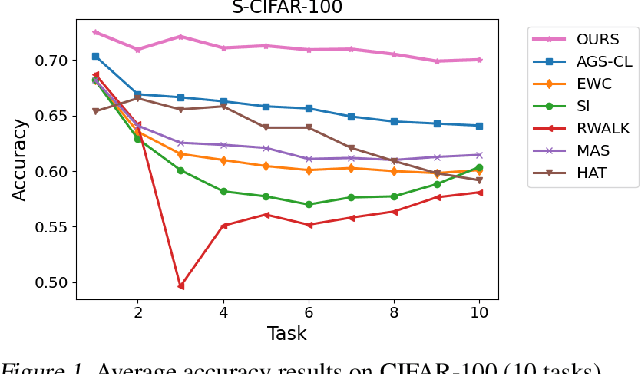

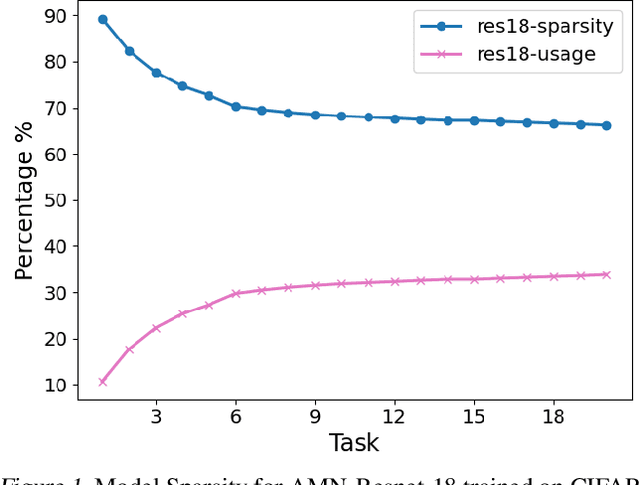
Catastrophic forgetting in neural networks is a significant problem for continual learning. A majority of the current methods replay previous data during training, which violates the constraints of an ideal continual learning system. Additionally, current approaches that deal with forgetting ignore the problem of catastrophic remembering, i.e. the worsening ability to discriminate between data from different tasks. In our work, we introduce Relevance Mapping Networks (RMNs) which are inspired by the Optimal Overlap Hypothesis. The mappings reflects the relevance of the weights for the task at hand by assigning large weights to essential parameters. We show that RMNs learn an optimized representational overlap that overcomes the twin problem of catastrophic forgetting and remembering. Our approach achieves state-of-the-art performance across all common continual learning datasets, even significantly outperforming data replay methods while not violating the constraints for an ideal continual learning system. Moreover, RMNs retain the ability to detect data from new tasks in an unsupervised manner, thus proving their resilience against catastrophic remembering.
CReST: A Class-Rebalancing Self-Training Framework for Imbalanced Semi-Supervised Learning
Feb 18, 2021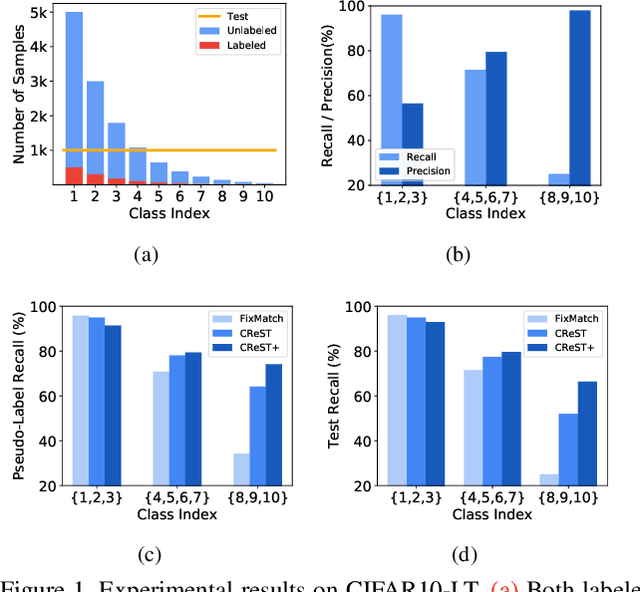

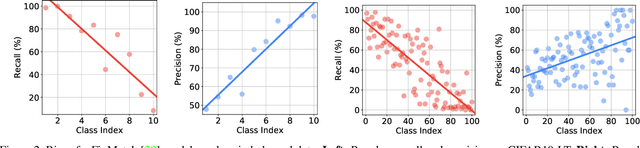
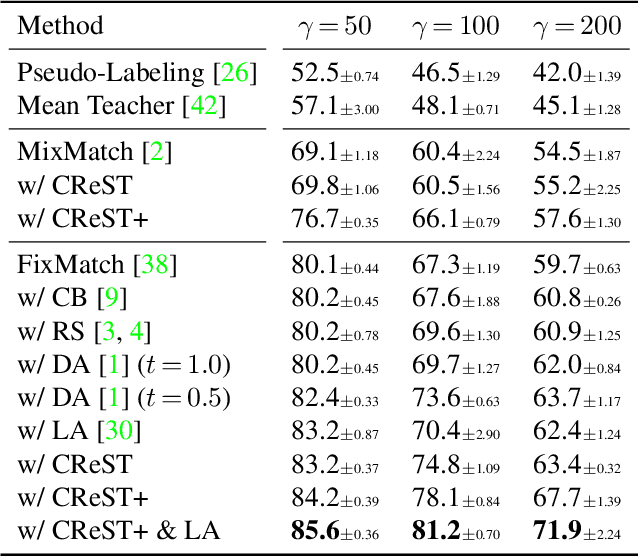
Semi-supervised learning on class-imbalanced data, although a realistic problem, has been under studied. While existing semi-supervised learning (SSL) methods are known to perform poorly on minority classes, we find that they still generate high precision pseudo-labels on minority classes. By exploiting this property, in this work, we propose Class-Rebalancing Self-Training (CReST), a simple yet effective framework to improve existing SSL methods on class-imbalanced data. CReST iteratively retrains a baseline SSL model with a labeled set expanded by adding pseudo-labeled samples from an unlabeled set, where pseudo-labeled samples from minority classes are selected more frequently according to an estimated class distribution. We also propose a progressive distribution alignment to adaptively adjust the rebalancing strength dubbed CReST+. We show that CReST and CReST+ improve state-of-the-art SSL algorithms on various class-imbalanced datasets and consistently outperform other popular rebalancing methods.
Occluded Video Instance Segmentation
Feb 08, 2021
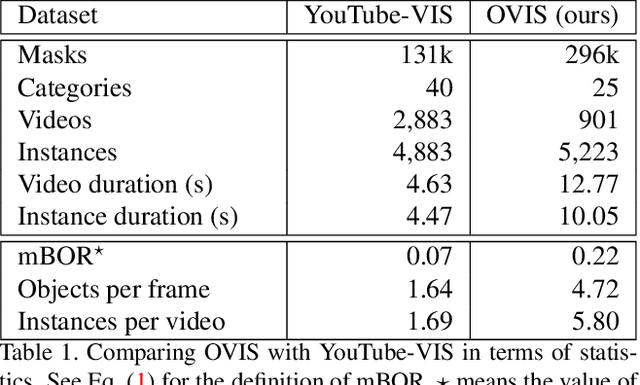

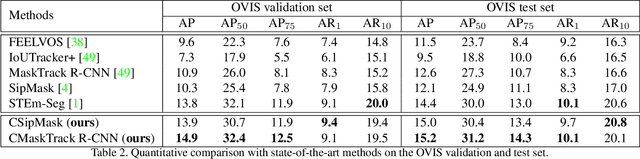
Can our video understanding systems perceive objects when a heavy occlusion exists in a scene? To answer this question, we collect a large scale dataset called OVIS for occluded video instance segmentation, that is, to simultaneously detect, segment, and track instances in occluded scenes. OVIS consists of 296k high-quality instance masks from 25 semantic categories, where object occlusions usually occur. While our human vision systems can understand those occluded instances by contextual reasoning and association, our experiments suggest that current video understanding systems are not satisfying. On the OVIS dataset, the highest AP achieved by state-of-the-art algorithms is only 14.4, which reveals that we are still at a nascent stage for understanding objects, instances, and videos in a real-world scenario. Moreover, to complement missing object cues caused by occlusion, we propose a plug-and-play module called temporal feature calibration. Built upon MaskTrack R-CNN and SipMask, we report an AP of 15.2 and 15.0 respectively. The OVIS dataset is released at http://songbai.site/ovis , and the project code will be available soon.