 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAKES: Channel-wise Automatic KErnel Shrinking for Efficient 3D Network
Mar 28, 2020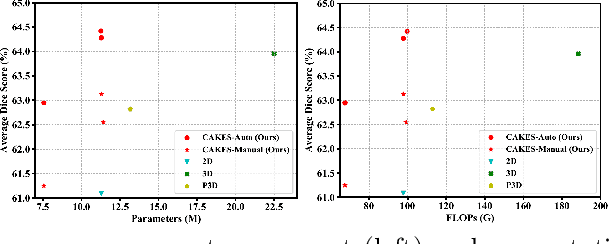
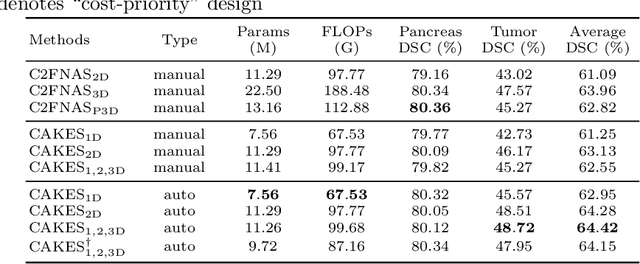
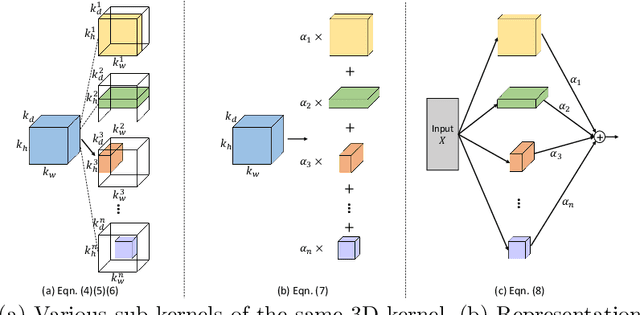
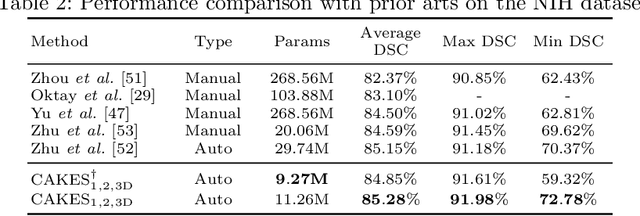
3D Convolution Neural Networks (CNNs) have been widely applied to 3D scene understanding, such as video analysis and volumetric image recognition. However, 3D networks can easily lead to over-parameterization which incurs expensive computation cost. In this paper, we propose Channel-wise Automatic KErnel Shrinking (CAKES), to enable efficient 3D learning by shrinking standard 3D convolutions into a set of economic operations (e.g., 1D, 2D convolutions). Unlike previous methods, our proposed CAKES performs channel-wise kernel shrinkage, which enjoys the following benefits: 1) encouraging operations deployed in every layer to be heterogeneous, so that they can extract diverse and complementary information to benefit the learning process; and 2) allowing for an efficient and flexible replacement design, which can be generalized to both spatial-temporal and volumetric data. Together with a neural architecture search framework, by applying CAKES to 3D C2FNAS and ResNet50, we achieve the state-of-the-art performance with much fewer parameters and computational costs on both 3D medical imaging segmentation and video action recognition.
C2FNAS: Coarse-to-Fine Neural Architecture Search for 3D Medical Image Segmentation
Dec 20, 2019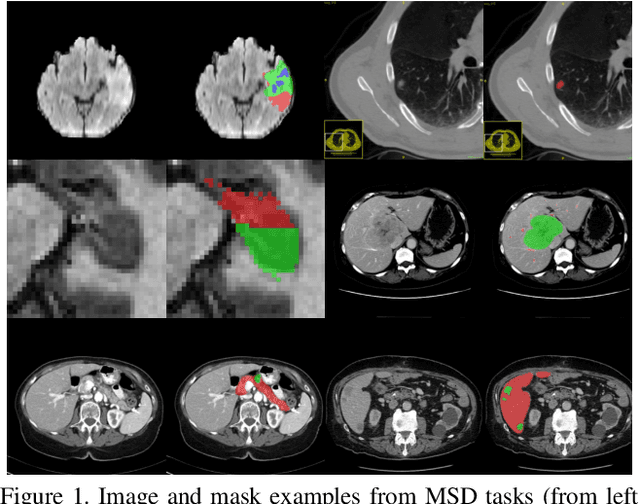
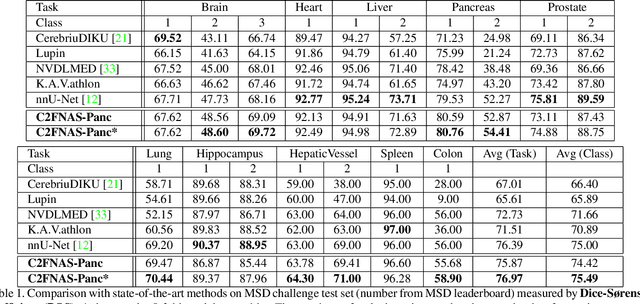

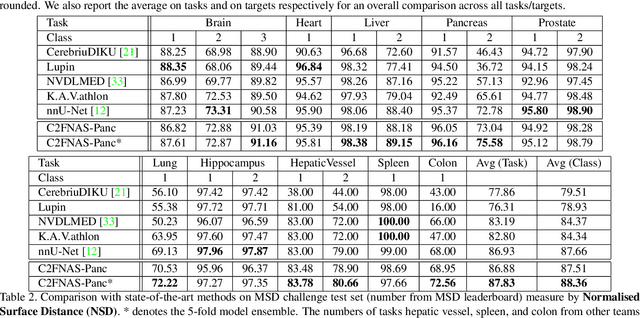
3D convolution neural networks (CNN) have been proved very successful in parsing organs or tumours in 3D medical images, but it remains sophisticated and time-consuming to choose or design proper 3D networks given different task contexts. Recently, Neural Architecture Search (NAS) is proposed to solve this problem by searching for the best network architecture automatically. However, the inconsistency between search stage and deployment stage often exists in NAS algorithms due to memory constraints and large search space, which could become more serious when applying NAS to some memory and time consuming tasks, such as 3D medical image segmentation. In this paper, we propose coarse-to-fine neural architecture search (C2FNAS) to automatically search a 3D segmentation network from scratch without inconsistency on network size or input size. Specifically, we divide the search procedure into two stages: 1) the coarse stage, where we search the macro-level topology of the network, i.e. how each convolution module is connected to other modules; 2) the fine stage, where we search at micro-level for operations in each cell based on previous searched macro-level topology. The coarse-to-fine manner divides the search procedure into two consecutive stages and meanwhile resolves the inconsistency. We evaluate our method on 10 public datasets from Medical Segmentation Decalthon (MSD) challenge, and achieve state-of-the-art performance with the network searched using one dataset, which demonstrates the effectiveness and generalization of our searched models.
Car Pose in Context: Accurate Pose Estimation with Ground Plane Constraints
Dec 09, 2019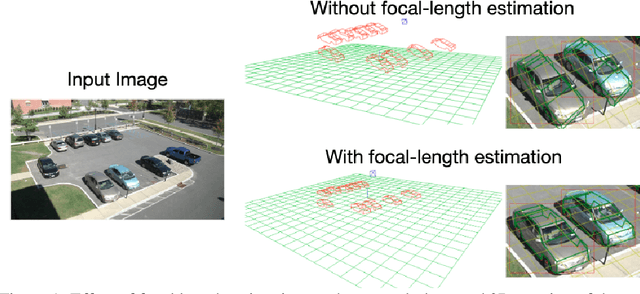
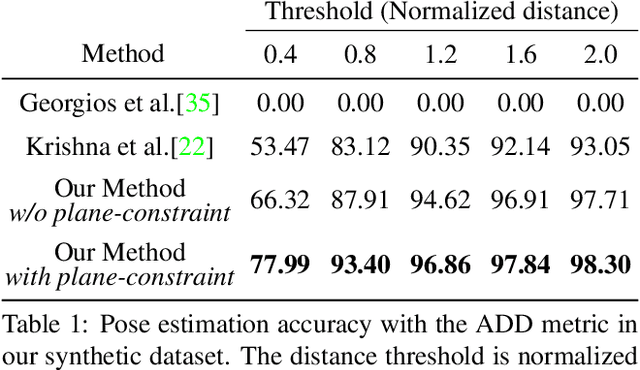
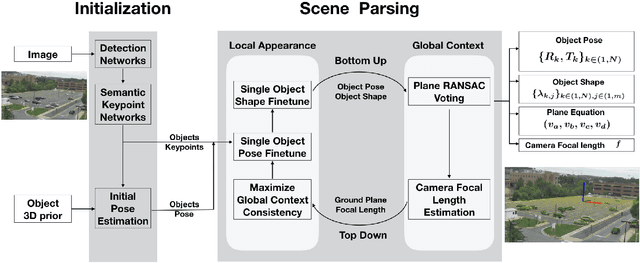
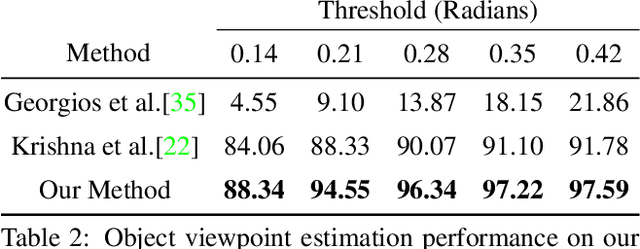
Scene context is a powerful constraint on the geometry of objects within the scene in cases, such as surveillance, where the camera geometry is unknown and image quality may be poor. In this paper, we describe a method for estimating the pose of cars in a scene jointly with the ground plane that supports them. We formulate this as a joint optimization that accounts for varying car shape using a statistical atlas, and which simultaneously computes geometry and internal camera parameters. We demonstrate that this method produces significant improvements for car pose estimation, and we show that the resulting 3D geometry, when computed over a video sequence, makes it possible to improve on state of the art classification of car behavior. We also show that introducing the planar constraint allows us to estimate camera focal length in a reliable manner.
Deep Distance Transform for Tubular Structure Segmentation in CT Scans
Dec 06, 2019
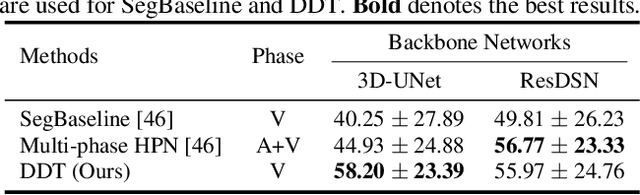
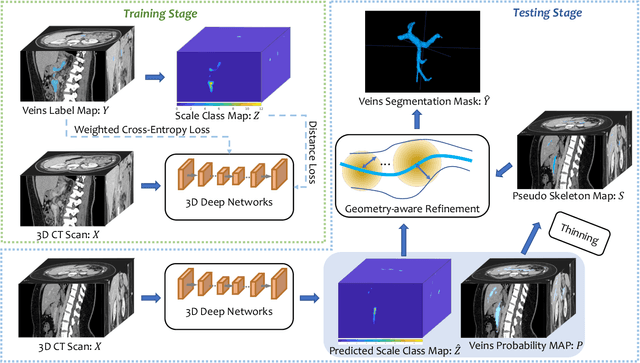
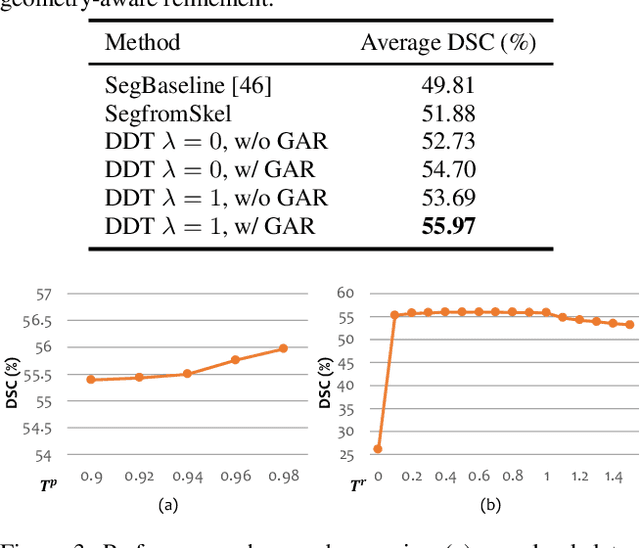
Tubular structure segmentation in medical images, e.g., segmenting vessels in CT scans, serves as a vital step in the use of computers to aid in screening early stages of related diseases. But automatic tubular structure segmentation in CT scans is a challenging problem, due to issues such as poor contrast, noise and complicated background. A tubular structure usually has a cylinder-like shape which can be well represented by its skeleton and cross-sectional radii (scales). Inspired by this, we propose a geometry-aware tubular structure segmentation method, Deep Distance Transform (DDT), which combines intuitions from the classical distance transform for skeletonization and modern deep segmentation networks. DDT first learns a multi-task network to predict a segmentation mask for a tubular structure and a distance map. Each value in the map represents the distance from each tubular structure voxel to the tubular structure surface. Then the segmentation mask is refined by leveraging the shape prior reconstructed from the distance map. We apply our DDT on six medical image datasets. The experiments show that (1) DDT can boost tubular structure segmentation performance significantly (e.g., over 13% improvement measured by DSC for pancreatic duct segmentation), and (2) DDT additionally provides a geometrical measurement for a tubular structure, which is important for clinical diagnosis (e.g., the cross-sectional scale of a pancreatic duct can be an indicator for pancreatic cancer).
Adversarial Examples for Edge Detection: They Exist, and They Transfer
Jun 02, 2019

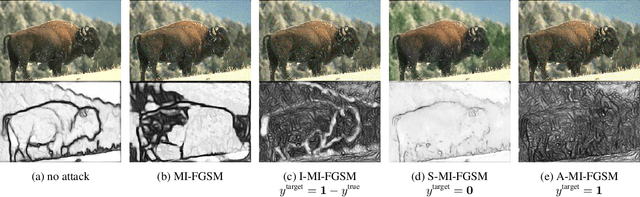
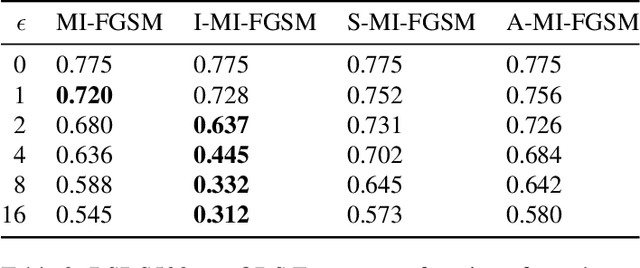
Convolutional neural networks have recently advanced the state of the art in many tasks including edge and object boundary detection. However, in this paper, we demonstrate that these edge detectors inherit a troubling property of neural networks: they can be fooled by adversarial examples. We show that adding small perturbations to an image causes HED, a CNN-based edge detection model, to fail to locate edges, to detect nonexistent edges, and even to hallucinate arbitrary configurations of edges. More surprisingly, we find that these adversarial examples transfer to other CNN-based vision models. In particular, attacks on edge detection result in significant drops in accuracy in models trained to perform unrelated, high-level tasks like image classification and semantic segmentation. Our code will be made public.
Patch-based 3D Human Pose Refinement
May 20, 2019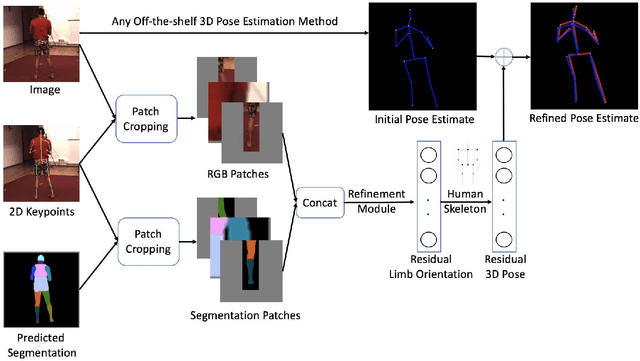
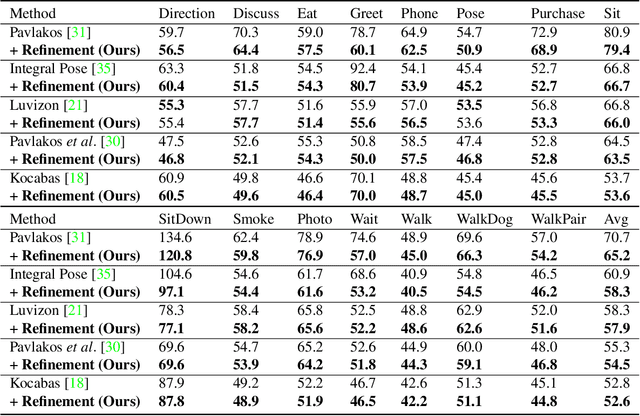


State-of-the-art 3D human pose estimation approaches typically estimate pose from the entire RGB image in a single forward run. In this paper, we develop a post-processing step to refine 3D human pose estimation from body part patches. Using local patches as input has two advantages. First, the fine details around body parts are zoomed in to high resolution for preciser 3D pose prediction. Second, it enables the part appearance to be shared between poses to benefit rare poses. In order to acquire informative representation of patches, we explore different input modalities and validate the superiority of fusing predicted segmentation with RGB. We show that our method consistently boosts the accuracy of state-of-the-art 3D human pose methods.
Thickened 2D Networks for 3D Medical Image Segmentation
Apr 02, 2019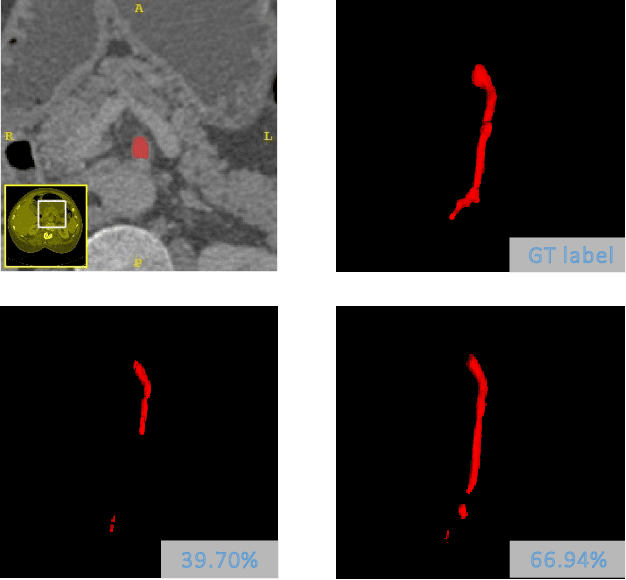
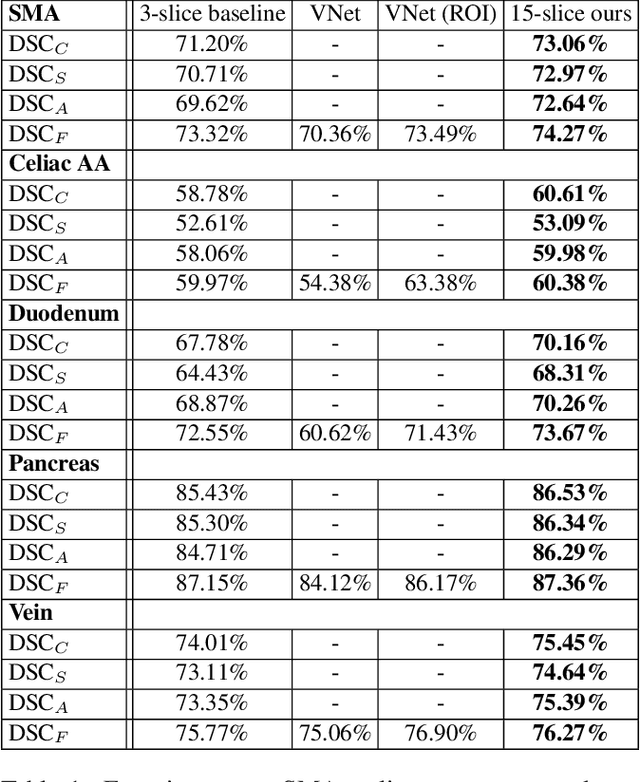
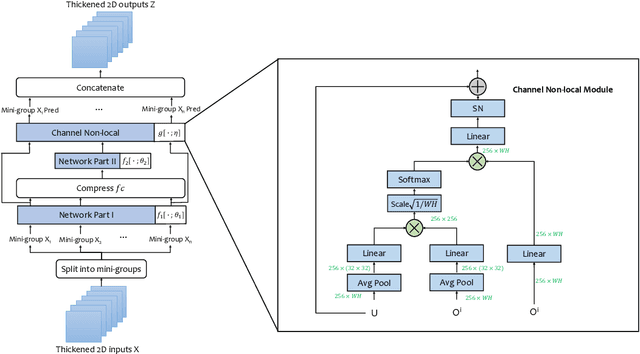
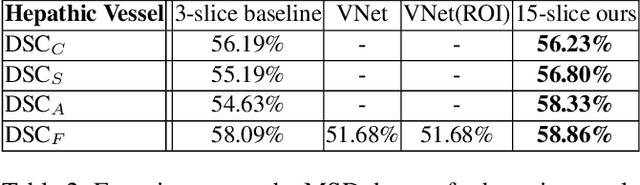
There has been a debate in medical image segmentation on whether to use 2D or 3D networks, where both pipelines have advantages and disadvantages. This paper presents a novel approach which thickens the input of a 2D network, so that the model is expected to enjoy both the stability and efficiency of 2D networks as well as the ability of 3D networks in modeling volumetric contexts. A major information loss happens when a large number of 2D slices are fused at the first convolutional layer, resulting in a relatively weak ability of the network in distinguishing the difference among slices. To alleviate this drawback, we propose an effective framework which (i) postpones slice fusion and (ii) adds highway connections from the pre-fusion layer so that the prediction layer receives slice-sensitive auxiliary cues. Experiments on segmenting a few abdominal targets in particular blood vessels which require strong 3D contexts demonstrate the effectiveness of our approach.
Regional Homogeneity: Towards Learning Transferable Universal Adversarial Perturbations Against Defenses
Apr 01, 2019

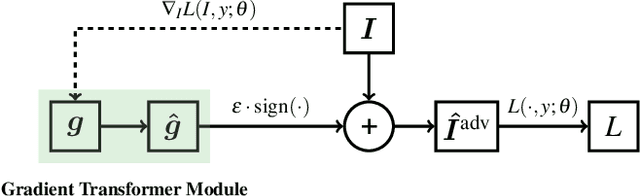
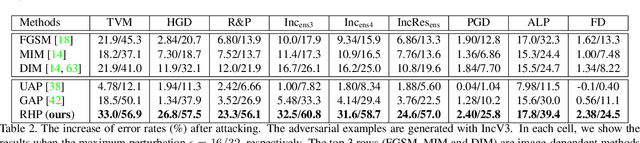
This paper focuses on learning transferable adversarial examples specifically against defense models (models to defense adversarial attacks). In particular, we show that a simple universal perturbation can fool a series of state-of-the-art defenses. Adversarial examples generated by existing attacks are generally hard to transfer to defense models. We observe the property of regional homogeneity in adversarial perturbations and suggest that the defenses are less robust to regionally homogeneous perturbations. Therefore, we propose an effective transforming paradigm and a customized gradient transformer module to transform existing perturbations into regionally homogeneous ones. Without explicitly forcing the perturbations to be universal, we observe that a well-trained gradient transformer module tends to output input-independent gradients (hence universal) benefiting from the under-fitting phenomenon. Thorough experiments demonstrate that our work significantly outperforms the prior art attacking algorithms (either image-dependent or universal ones) by an average improvement of 14.0% when attacking 9 defenses in the black-box setting. In addition to the cross-model transferability, we also verify that regionally homogeneous perturbations can well transfer across different vision tasks (attacking with the semantic segmentation task and testing on the object detection task).
Phase Collaborative Network for Multi-Phase Medical Imaging Segmentation
Dec 06, 2018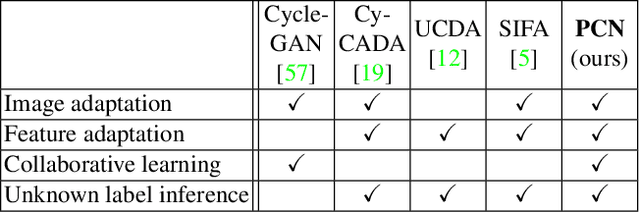
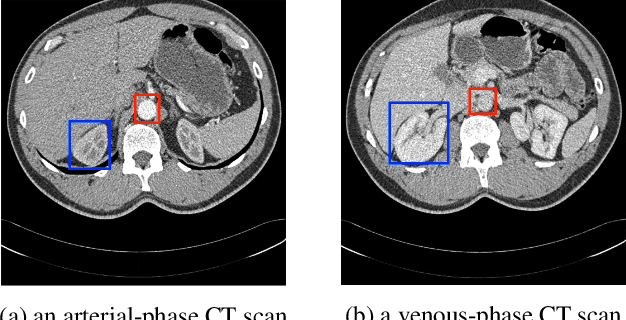
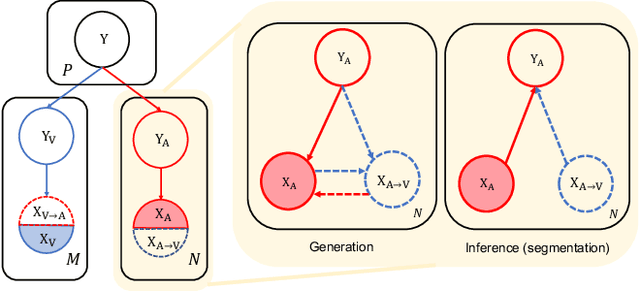
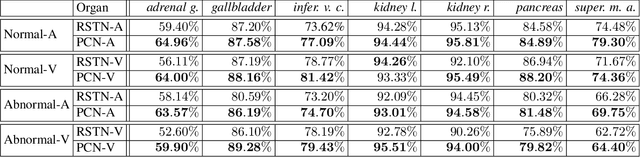
Integrating multi-phase information is an effective way of boosting visual recognition. In this paper, we investigate this problem from the perspective of medical imaging analysis, in which two phases in CT scans known as arterial and venous are combined towards higher segmentation accuracy. To this end, we propose Phase Collaborative Network (PCN), an end-to-end network which contains both generative and discriminative modules to formulate phase-to-phase relations and data-to-label relations, respectively. Experiments are performed on several CT image segmentation datasets. PCN achieves superior performance with either two phases or only one phase available. Moreover, we empirically verify that the accuracy gain comes from the collaboration between phases.
Towards Accurate Task Accomplishment with Low-Cost Robotic Arms
Dec 03, 2018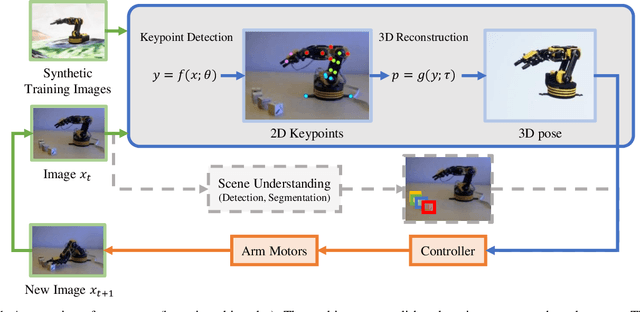
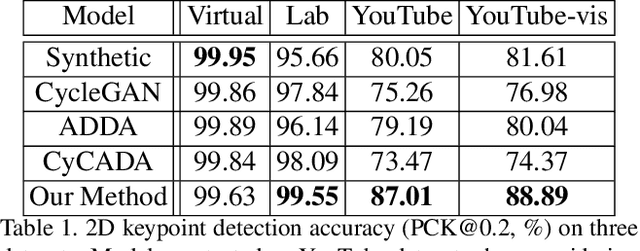
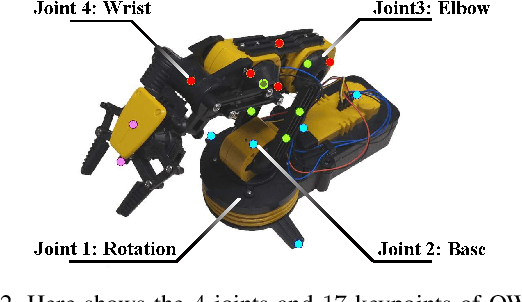
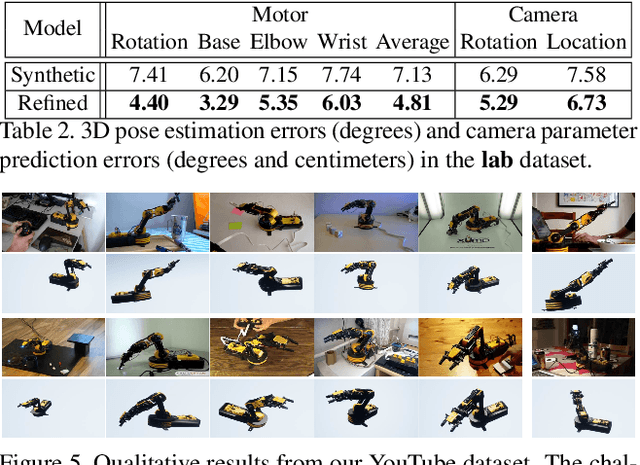
Training a robotic arm to accomplish real-world tasks has been attracting increasing attention in both academia and industry. This work discusses the role of computer vision algorithms in this field. We focus on low-cost arms on which no sensors are equipped and thus all decisions are made upon visual recognition, e.g., real-time 3D pose estimation. This requires annotating a lot of training data, which is not only time-consuming but also laborious. In this paper, we present an alternative solution, which uses a 3D model to create a large number of synthetic data, trains a vision model in this virtual domain, and applies it to real-world images after domain adaptation. To this end, we design a semi-supervised approach, which fully leverages the geometric constraints among keypoints. We apply an iterative algorithm for optimization. Without any annotations on real images, our algorithm generalizes well and produces satisfying results on 3D pose estimation, which is evaluated on two real-world datasets. We also construct a vision-based control system for task accomplishment, for which we train a reinforcement learning agent in a virtual environment and apply it to the real-world. Moreover, our approach, with merely a 3D model being required, has the potential to generalize to other types of multi-rigid-body dynamic systems.