 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
RealTranS: End-to-End Simultaneous Speech Translation with Convolutional Weighted-Shrinking Transformer
Jun 09, 2021
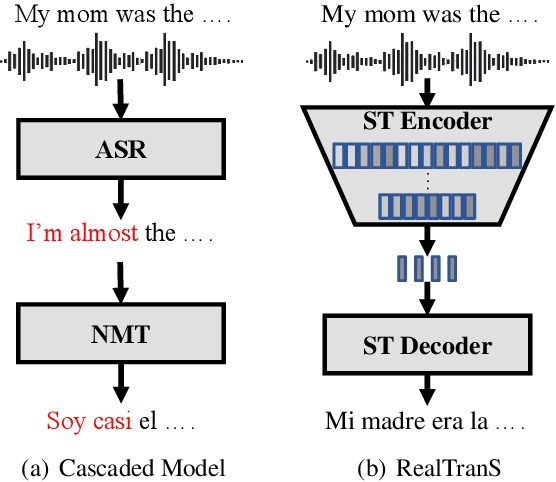
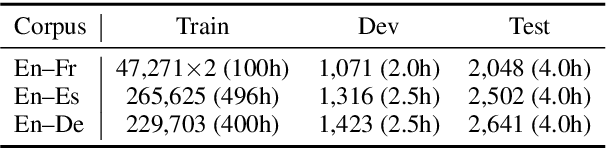
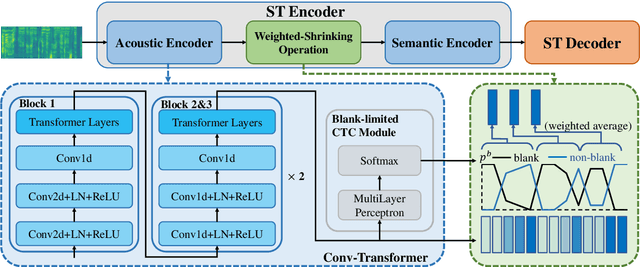

End-to-end simultaneous speech translation (SST), which directly translates speech in one language into text in another language in real-time, is useful in many scenarios but has not been fully investigated. In this work, we propose RealTranS, an end-to-end model for SST. To bridge the modality gap between speech and text, RealTranS gradually downsamples the input speech with interleaved convolution and unidirectional Transformer layers for acoustic modeling, and then maps speech features into text space with a weighted-shrinking operation and a semantic encoder. Besides, to improve the model performance in simultaneous scenarios, we propose a blank penalty to enhance the shrinking quality and a Wait-K-Stride-N strategy to allow local reranking during decoding. Experiments on public and widely-used datasets show that RealTranS with the Wait-K-Stride-N strategy outperforms prior end-to-end models as well as cascaded models in diverse latency settings.
Speaker activity driven neural speech extraction
Feb 09, 2021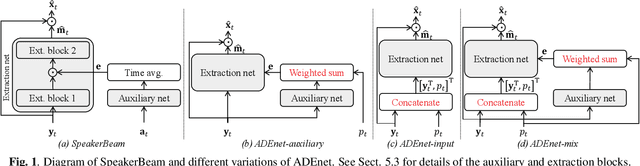

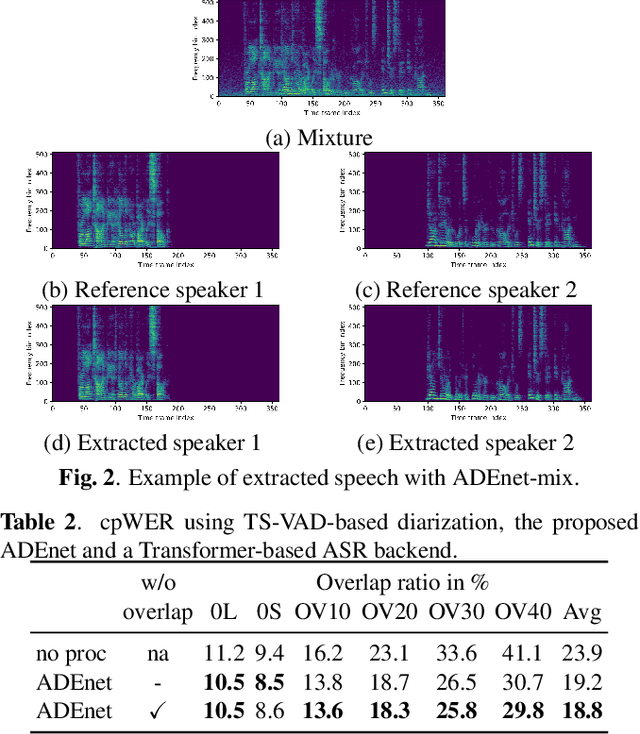
Target speech extraction, which extracts the speech of a target speaker in a mixture given auxiliary speaker clues, has recently received increased interest. Various clues have been investigated such as pre-recorded enrollment utterances, direction information, or video of the target speaker. In this paper, we explore the use of speaker activity information as an auxiliary clue for single-channel neural network-based speech extraction. We propose a speaker activity driven speech extraction neural network (ADEnet) and show that it can achieve performance levels competitive with enrollment-based approaches, without the need for pre-recordings. We further demonstrate the potential of the proposed approach for processing meeting-like recordings, where the speaker activity is obtained from a diarization system. We show that this simple yet practical approach can successfully extract speakers after diarization, which results in improved ASR performance, especially in high overlapping conditions, with a relative word error rate reduction of up to 25%.
Speech2Slot: An End-to-End Knowledge-based Slot Filling from Speech
May 10, 2021
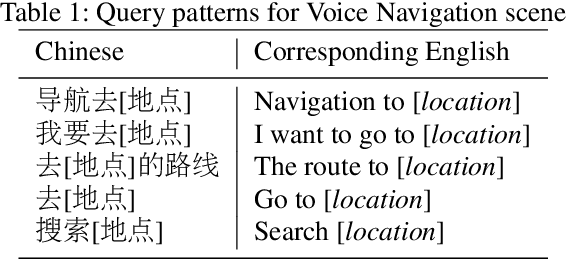
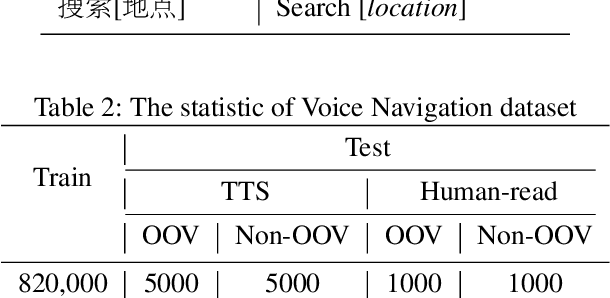
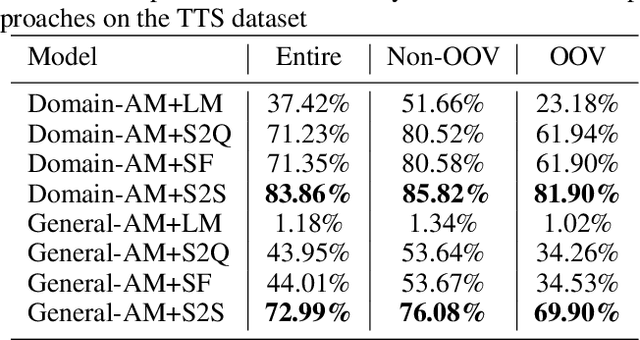
In contrast to conventional pipeline Spoken Language Understanding (SLU) which consists of automatic speech recognition (ASR) and natural language understanding (NLU), end-to-end SLU infers the semantic meaning directly from speech and overcomes the error propagation caused by ASR. End-to-end slot filling (SF) from speech is an essential component of end-to-end SLU, and is usually regarded as a sequence-to-sequence generation problem, heavily relied on the performance of language model of ASR. However, it is hard to generate a correct slot when the slot is out-of-vovabulary (OOV) in training data, especially when a slot is an anti-linguistic entity without grammatical rule. Inspired by object detection in computer vision that is to detect the object from an image, we consider SF as the task of slot detection from speech. In this paper, we formulate the SF task as a matching task and propose an end-to-end knowledge-based SF model, named Speech-to-Slot (Speech2Slot), to leverage knowledge to detect the boundary of a slot from the speech. We also release a large-scale dataset of Chinese speech for slot filling, containing more than 830,000 samples. The experiments show that our approach is markedly superior to the conventional pipeline SLU approach, and outperforms the state-of-the-art end-to-end SF approach with 12.51% accuracy improvement.
Joint magnitude estimation and phase recovery using Cyle-in-cycle GAN for non-parallel speech enhancement
Sep 26, 2021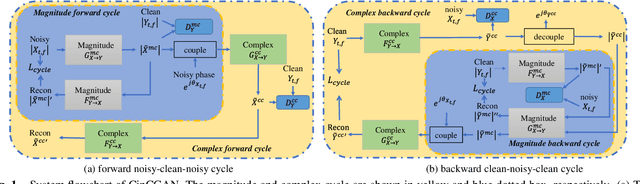
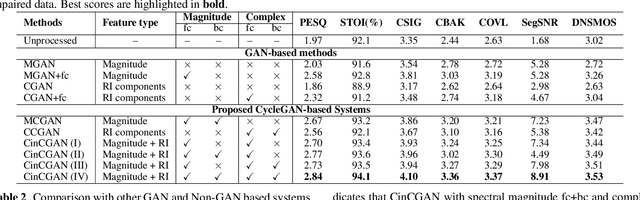
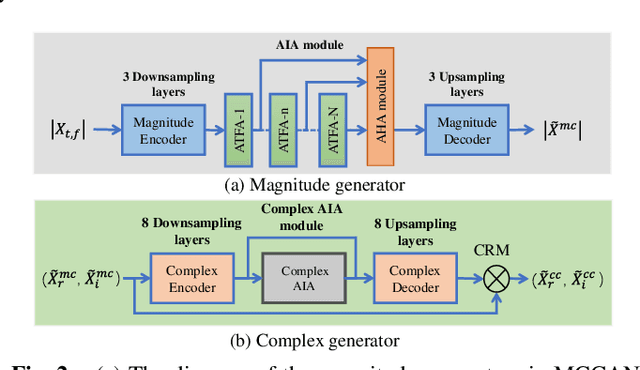
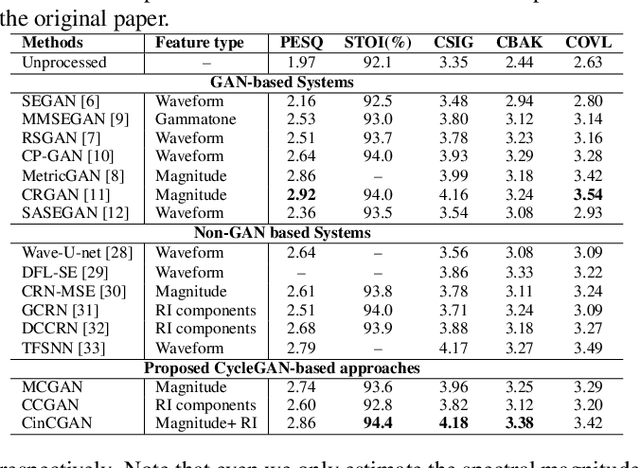
For the lack of adequate paired noisy-clean speech corpus in many real scenarios, non-parallel training is a promising task for DNN-based speech enhancement methods. However, because of the severe mismatch between input and target speech, many previous studies only focus on magnitude spectrum estimation and remain the phase unaltered, resulting in the degraded speech quality under low signal-to-noise ratio conditions. To tackle this problem, we decouple the difficult target $\emph{w.r.t.}$ original spectrum optimization into spectral magnitude and phase, and propose a novel Cycle-in-cycle generative adversarial network (dubbed CinCGAN) to jointly estimate the spectral magnitude and phase information stage by stage. In the first stage, we pretrain a magnitude CycleGAN to coarsely denoise the spectral magnitude spectrum. In the second stage, we couple the pretrained CycleGAN with a complex-valued CycleGAN as a cycle-in-cycle structure to recover phase information and refine the spectral magnitude simultaneously. The experimental results on the VoiceBank + Demand show that the proposed approach significantly outperforms previous baselines under non-parallel training. Experiments on training the models with standard paired data also show that the proposed method can achieve remarkable performance.
Cross-lingual Hate Speech Detection using Transformer Models
Nov 01, 2021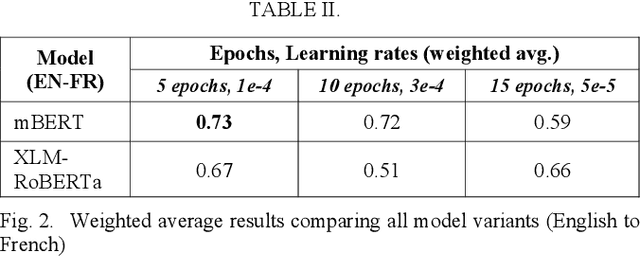
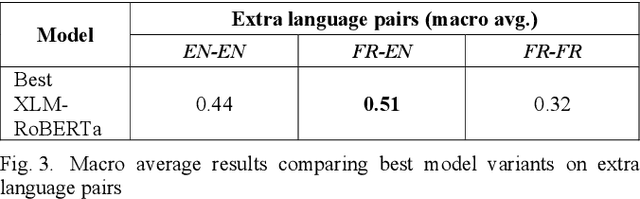
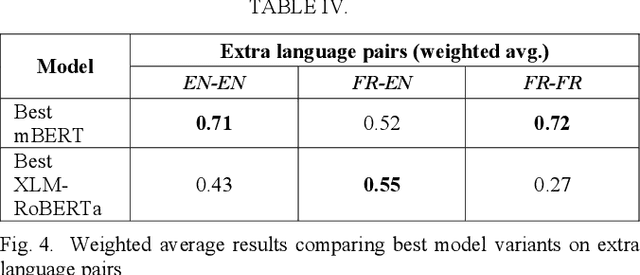
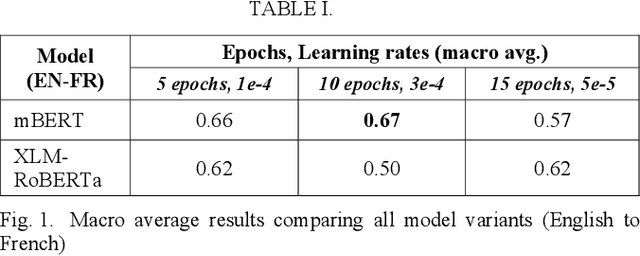
Hate speech detection within a cross-lingual setting represents a paramount area of interest for all medium and large-scale online platforms. Failing to properly address this issue on a global scale has already led over time to morally questionable real-life events, human deaths, and the perpetuation of hate itself. This paper illustrates the capabilities of fine-tuned altered multi-lingual Transformer models (mBERT, XLM-RoBERTa) regarding this crucial social data science task with cross-lingual training from English to French, vice-versa and each language on its own, including sections about iterative improvement and comparative error analysis.
Self Supervised Adversarial Domain Adaptation for Cross-Corpus and Cross-Language Speech Emotion Recognition
Apr 19, 2022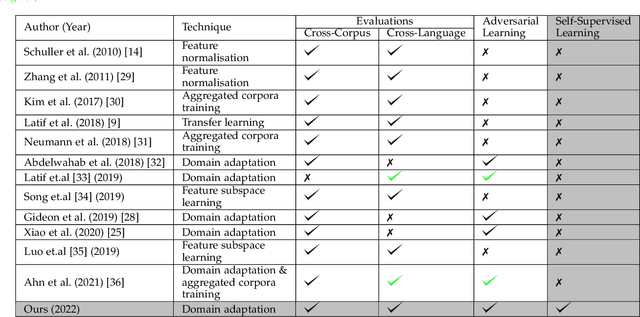
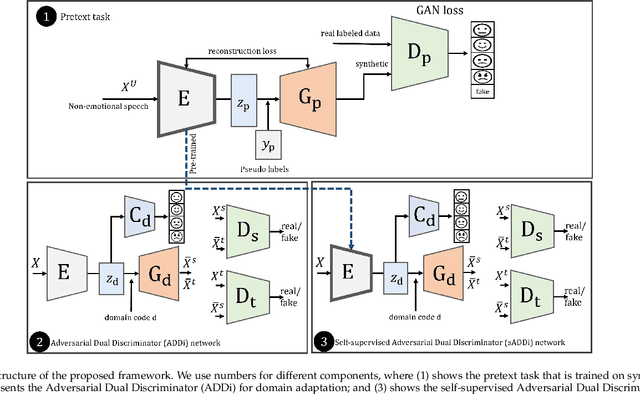
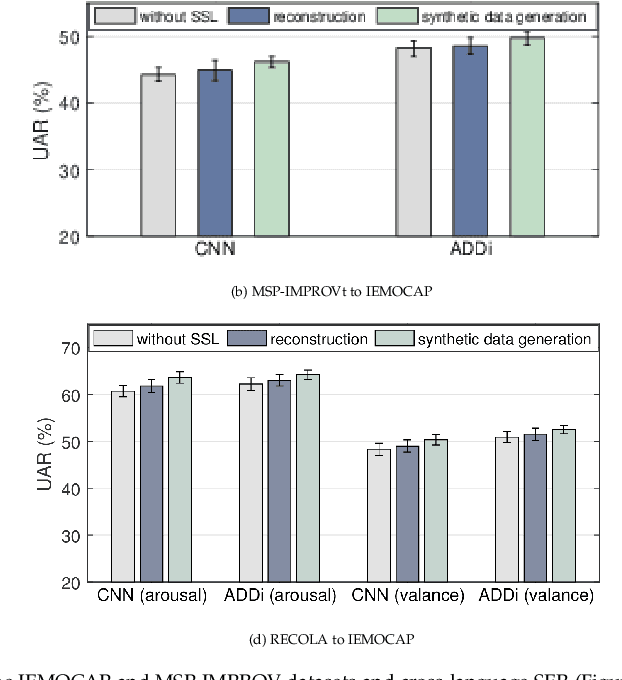
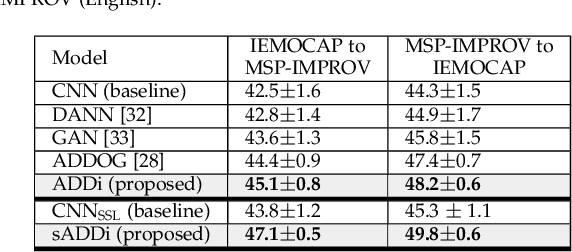
Despite the recent advancement in speech emotion recognition (SER) within a single corpus setting, the performance of these SER systems degrades significantly for cross-corpus and cross-language scenarios. The key reason is the lack of generalisation in SER systems towards unseen conditions, which causes them to perform poorly in cross-corpus and cross-language settings. Recent studies focus on utilising adversarial methods to learn domain generalised representation for improving cross-corpus and cross-language SER to address this issue. However, many of these methods only focus on cross-corpus SER without addressing the cross-language SER performance degradation due to a larger domain gap between source and target language data. This contribution proposes an adversarial dual discriminator (ADDi) network that uses the three-players adversarial game to learn generalised representations without requiring any target data labels. We also introduce a self-supervised ADDi (sADDi) network that utilises self-supervised pre-training with unlabelled data. We propose synthetic data generation as a pretext task in sADDi, enabling the network to produce emotionally discriminative and domain invariant representations and providing complementary synthetic data to augment the system. The proposed model is rigorously evaluated using five publicly available datasets in three languages and compared with multiple studies on cross-corpus and cross-language SER. Experimental results demonstrate that the proposed model achieves improved performance compared to the state-of-the-art methods.
Comparison of Soft and Hard Target RNN-T Distillation for Large-scale ASR
Oct 11, 2022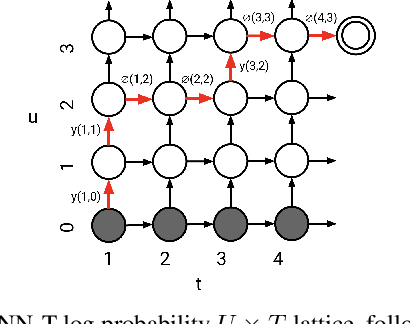
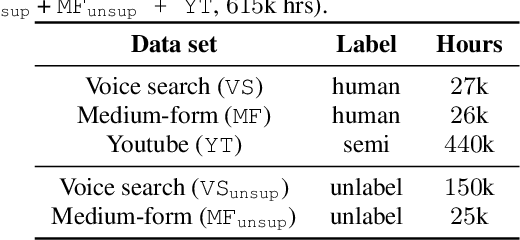

Knowledge distillation is an effective machine learning technique to transfer knowledge from a teacher model to a smaller student model, especially with unlabeled data. In this paper, we focus on knowledge distillation for the RNN-T model, which is widely used in state-of-the-art (SoTA) automatic speech recognition (ASR). Specifically, we compared using soft and hard target distillation to train large-scaleRNN-T models on the LibriSpeech/LibriLight public dataset (60k hours) and our in-house data (600k hours). We found that hard tar-gets are more effective when the teacher and student have different architecture, such as large teacher and small streaming student. On the other hand, soft target distillation works better in self-training scenario like iterative large teacher training. For a large model with0.6B weights, we achieve a new SoTA word error rate (WER) on LibriSpeech (8% relative improvement on dev-other) using Noisy Student Training with soft target distillation. It also allows our production teacher to adapt new data domain continuously.
ConvRNN-T: Convolutional Augmented Recurrent Neural Network Transducers for Streaming Speech Recognition
Sep 29, 2022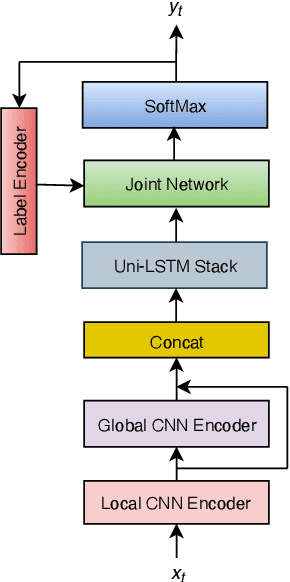
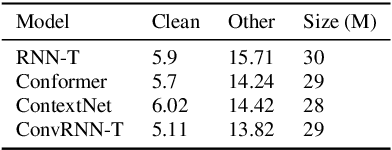
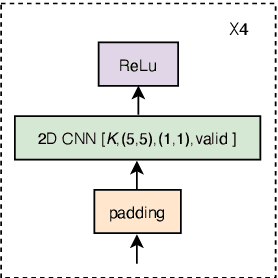

The recurrent neural network transducer (RNN-T) is a prominent streaming end-to-end (E2E) ASR technology. In RNN-T, the acoustic encoder commonly consists of stacks of LSTMs. Very recently, as an alternative to LSTM layers, the Conformer architecture was introduced where the encoder of RNN-T is replaced with a modified Transformer encoder composed of convolutional layers at the frontend and between attention layers. In this paper, we introduce a new streaming ASR model, Convolutional Augmented Recurrent Neural Network Transducers (ConvRNN-T) in which we augment the LSTM-based RNN-T with a novel convolutional frontend consisting of local and global context CNN encoders. ConvRNN-T takes advantage of causal 1-D convolutional layers, squeeze-and-excitation, dilation, and residual blocks to provide both global and local audio context representation to LSTM layers. We show ConvRNN-T outperforms RNN-T, Conformer, and ContextNet on Librispeech and in-house data. In addition, ConvRNN-T offers less computational complexity compared to Conformer. ConvRNN-T's superior accuracy along with its low footprint make it a promising candidate for on-device streaming ASR technologies.
Continual-wav2vec2: an Application of Continual Learning for Self-Supervised Automatic Speech Recognition
Jul 26, 2021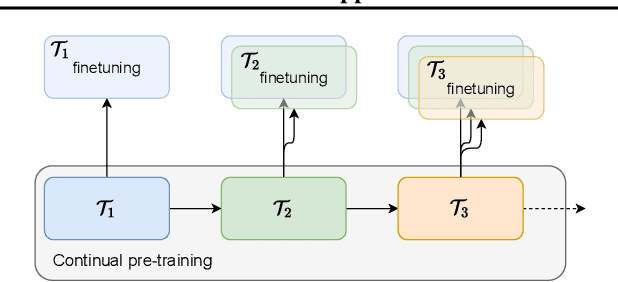
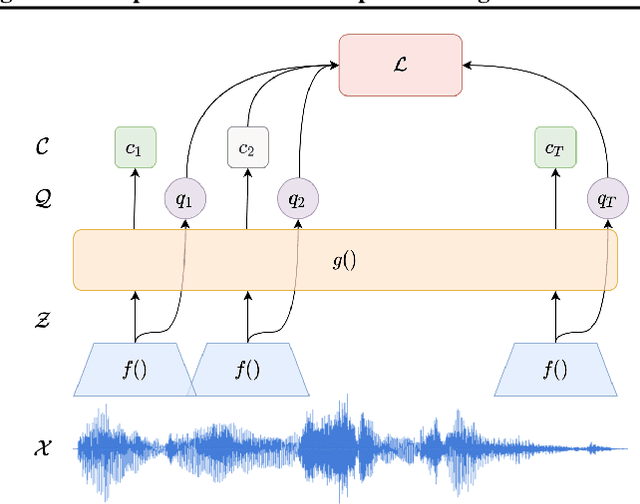
We present a method for continual learning of speech representations for multiple languages using self-supervised learning (SSL) and applying these for automatic speech recognition. There is an abundance of unannotated speech, so creating self-supervised representations from raw audio and finetuning on a small annotated datasets is a promising direction to build speech recognition systems. Wav2vec models perform SSL on raw audio in a pretraining phase and then finetune on a small fraction of annotated data. SSL models have produced state of the art results for ASR. However, these models are very expensive to pretrain with self-supervision. We tackle the problem of learning new language representations continually from audio without forgetting a previous language representation. We use ideas from continual learning to transfer knowledge from a previous task to speed up pretraining a new language task. Our continual-wav2vec2 model can decrease pretraining times by 32% when learning a new language task, and learn this new audio-language representation without forgetting previous language representation.
A Comparative Study on Speaker-attributed Automatic Speech Recognition in Multi-party Meetings
Apr 01, 2022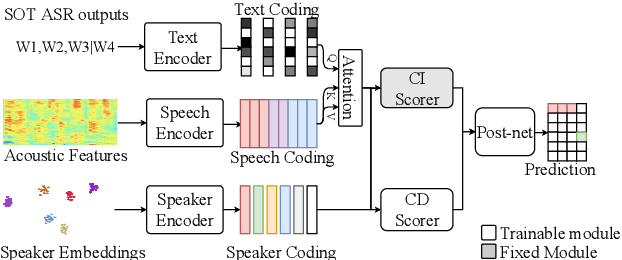
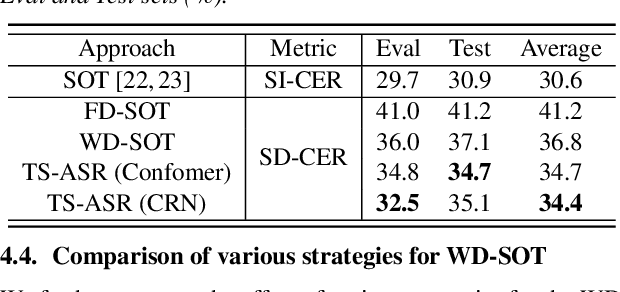
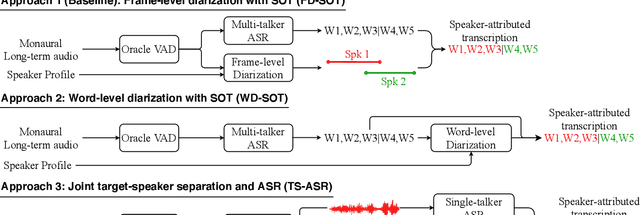
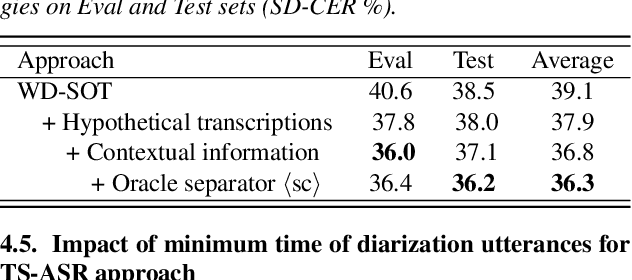
In this paper, we conduct a comparative study on speaker-attributed automatic speech recognition (SA-ASR) in the multi-party meeting scenario, a topic with increasing attention in meeting rich transcription. Specifically, three approaches are evaluated in this study. The first approach, FD-SOT, consists of a frame-level diarization model to identify speakers and a multi-talker ASR to recognize utterances. The speaker-attributed transcriptions are obtained by aligning the diarization results and recognized hypotheses. However, such an alignment strategy may suffer from erroneous timestamps due to the modular independence, severely hindering the model performance. Therefore, we propose the second approach, WD-SOT, to address alignment errors by introducing a word-level diarization model, which can get rid of such timestamp alignment dependency. To further mitigate the alignment issues, we propose the third approach, TS-ASR, which trains a target-speaker separation module and an ASR module jointly. By comparing various strategies for each SA-ASR approach, experimental results on a real meeting scenario corpus, AliMeeting, reveal that the WD-SOT approach achieves 10.7% relative reduction on averaged speaker-dependent character error rate (SD-CER), compared with the FD-SOT approach. In addition, the TS-ASR approach also outperforms the FD-SOT approach and brings 16.5% relative average SD-CER reduction.