 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech2Slot: An End-to-End Knowledge-based Slot Filling from Speech
Paper and Code
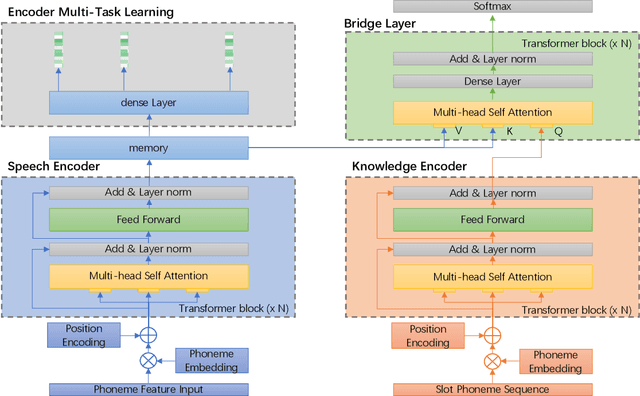
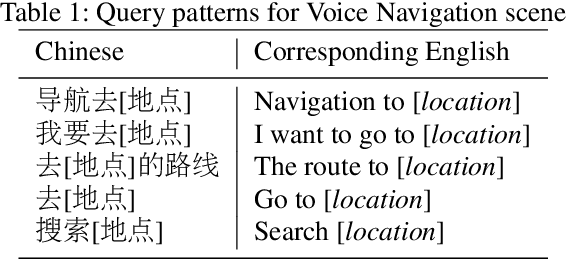
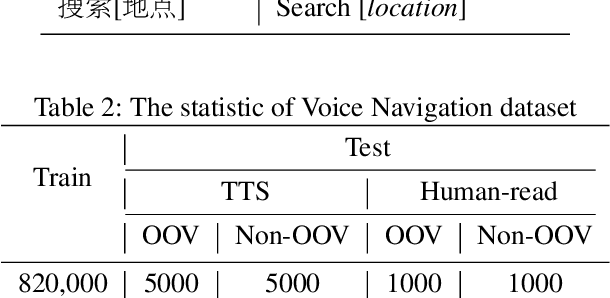
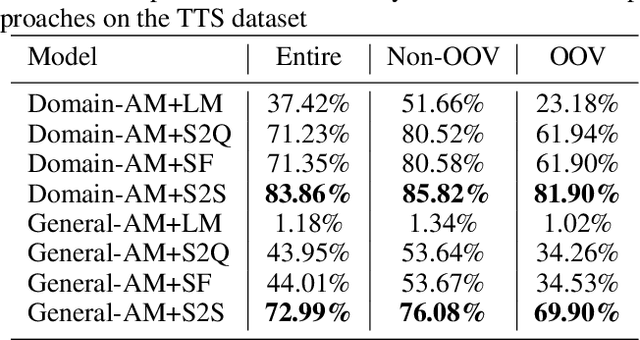
In contrast to conventional pipeline Spoken Language Understanding (SLU) which consists of automatic speech recognition (ASR) and natural language understanding (NLU), end-to-end SLU infers the semantic meaning directly from speech and overcomes the error propagation caused by ASR. End-to-end slot filling (SF) from speech is an essential component of end-to-end SLU, and is usually regarded as a sequence-to-sequence generation problem, heavily relied on the performance of language model of ASR. However, it is hard to generate a correct slot when the slot is out-of-vovabulary (OOV) in training data, especially when a slot is an anti-linguistic entity without grammatical rule. Inspired by object detection in computer vision that is to detect the object from an image, we consider SF as the task of slot detection from speech. In this paper, we formulate the SF task as a matching task and propose an end-to-end knowledge-based SF model, named Speech-to-Slot (Speech2Slot), to leverage knowledge to detect the boundary of a slot from the speech. We also release a large-scale dataset of Chinese speech for slot filling, containing more than 830,000 samples. The experiments show that our approach is markedly superior to the conventional pipeline SLU approach, and outperforms the state-of-the-art end-to-end SF approach with 12.51% accuracy improvement.