 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study on Speaker-attributed Automatic Speech Recognition in Multi-party Meetings
Paper and Code
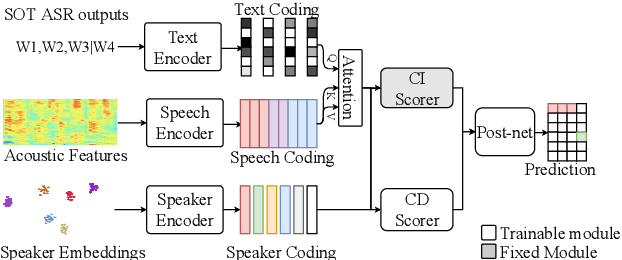
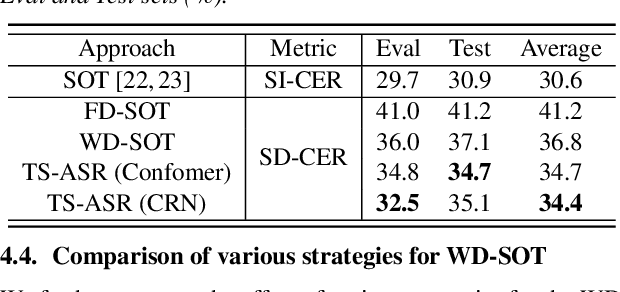
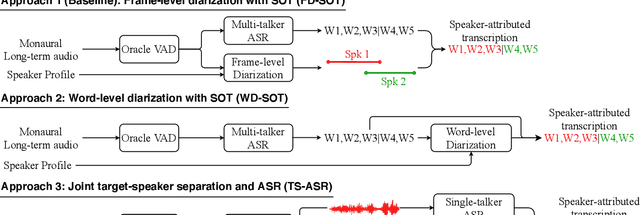
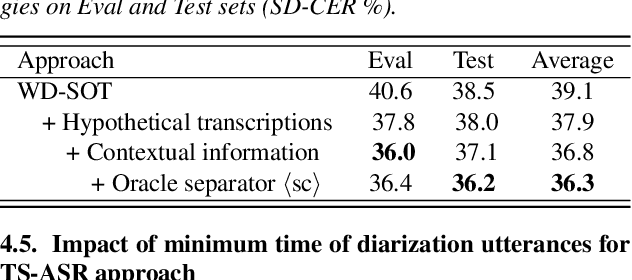
In this paper, we conduct a comparative study on speaker-attributed automatic speech recognition (SA-ASR) in the multi-party meeting scenario, a topic with increasing attention in meeting rich transcription. Specifically, three approaches are evaluated in this study. The first approach, FD-SOT, consists of a frame-level diarization model to identify speakers and a multi-talker ASR to recognize utterances. The speaker-attributed transcriptions are obtained by aligning the diarization results and recognized hypotheses. However, such an alignment strategy may suffer from erroneous timestamps due to the modular independence, severely hindering the model performance. Therefore, we propose the second approach, WD-SOT, to address alignment errors by introducing a word-level diarization model, which can get rid of such timestamp alignment dependency. To further mitigate the alignment issues, we propose the third approach, TS-ASR, which trains a target-speaker separation module and an ASR module jointly. By comparing various strategies for each SA-ASR approach, experimental results on a real meeting scenario corpus, AliMeeting, reveal that the WD-SOT approach achieves 10.7% relative reduction on averaged speaker-dependent character error rate (SD-CER), compared with the FD-SOT approach. In addition, the TS-ASR approach also outperforms the FD-SOT approach and brings 16.5% relative average SD-CER reduction.