 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
SpeechUT: Bridging Speech and Text with Hidden-Unit for Encoder-Decoder Based Speech-Text Pre-training
Oct 07, 2022
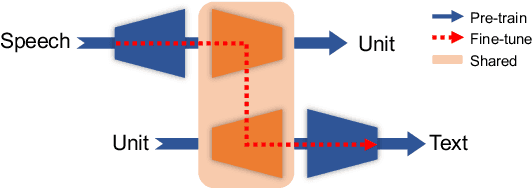
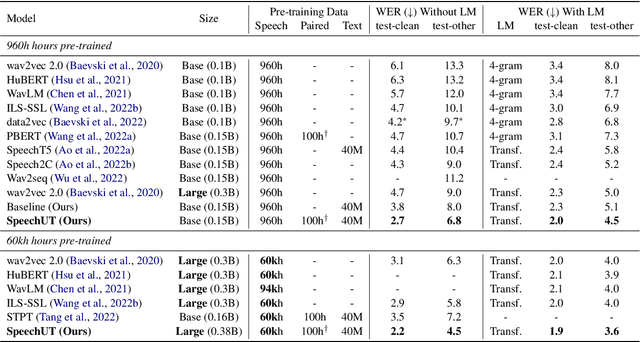
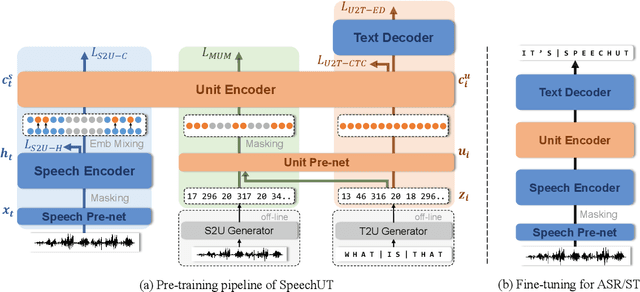
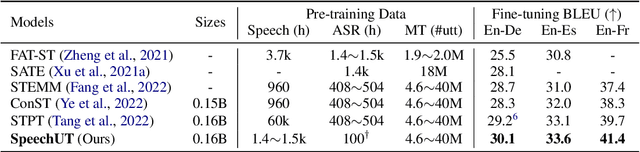
The rapid development of single-modal pre-training has prompted researchers to pay more attention to cross-modal pre-training methods. In this paper, we propose a unified-modal speech-unit-text pre-training model, SpeechUT, to connect the representations of a speech encoder and a text decoder with a shared unit encoder. Leveraging hidden-unit as an interface to align speech and text, we can decompose the speech-to-text model into a speech-to-unit model and a unit-to-text model, which can be jointly pre-trained with unpaired speech and text data respectively. Our proposed SpeechUT is fine-tuned and evaluated on automatic speech recognition (ASR) and speech translation (ST) tasks. Experimental results show that SpeechUT gets substantial improvements over strong baselines, and achieves state-of-the-art performance on both the LibriSpeech ASR and MuST-C ST tasks. To better understand the proposed SpeechUT, detailed analyses are conducted. The code and pre-trained models are available at https://aka.ms/SpeechUT.
Evaluation of the syllables pronunciation quality in speech rehabilitation through the solution of the classification problem
Jan 25, 2023
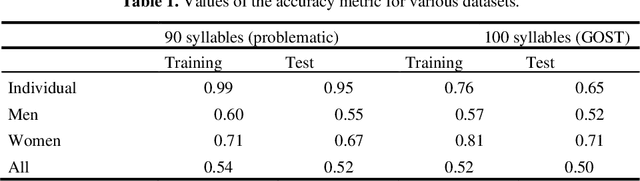
The solution of the problem of assessing the quality of the pronunciation of syllables during speech rehabilitation after surgical treatment of oncological diseases of the organs of the speech-forming tract is considered in the work. The assessment is carried out by solving the problem of classifying syllables into two classes: before and immediately after surgical treatment. A classifier is built on the basis of the LSTM neural network and trained on the records before the operation and immediately after it, before the start of speech rehabilitation. The measure of assessing the quality of syllables pronunciation in the process of rehabilitation is the metric of belonging to the class before the operation. A study is being made of the influence of taking into account problematic phonemes, the gender of the patient, his individual characteristics on the resulting estimates of the quality of pronunciation. A comparison with existing types of syllable pronunciation quality assessments is carried out, recommendations are given for the practical application of the resulting new class of pronunciation quality assessments.
Speech MOS multi-task learning and rater bias correction
Dec 04, 2022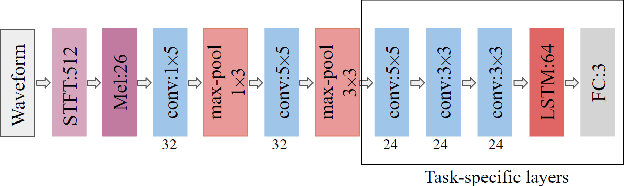

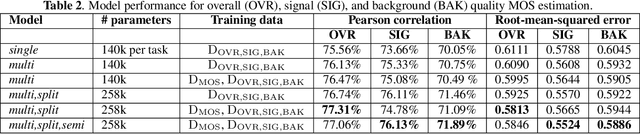
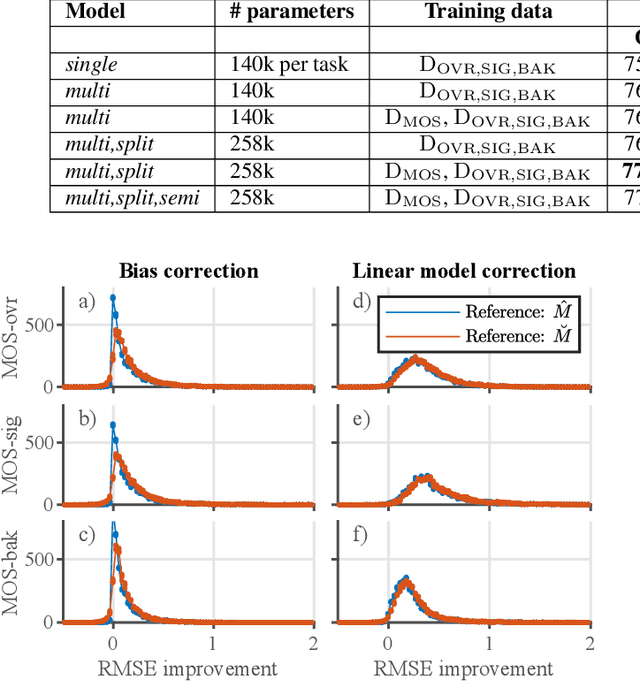
Perceptual speech quality is an important performance metric for teleconferencing applications. The mean opinion score (MOS) is standardized for the perceptual evaluation of speech quality and is obtained by asking listeners to rate the quality of a speech sample. Recently, there has been increasing research interest in developing models for estimating MOS blindly. Here we propose a multi-task framework to include additional labels and data in training to improve the performance of a blind MOS estimation model. Experimental results indicate that the proposed model can be trained to jointly estimate MOS, reverberation time (T60), and clarity (C50) by combining two disjoint data sets in training, one containing only MOS labels and the other containing only T60 and C50 labels. Furthermore, we use a semi-supervised framework to combine two MOS data sets in training, one containing only MOS labels (per ITU-T Recommendation P.808), and the other containing separate scores for speech signal, background noise, and overall quality (per ITU-T Recommendation P.835). Finally, we present preliminary results for addressing individual rater bias in the MOS labels.
Learning from Invalid Data: On Constraint Satisfaction in Generative Models
Jun 27, 2023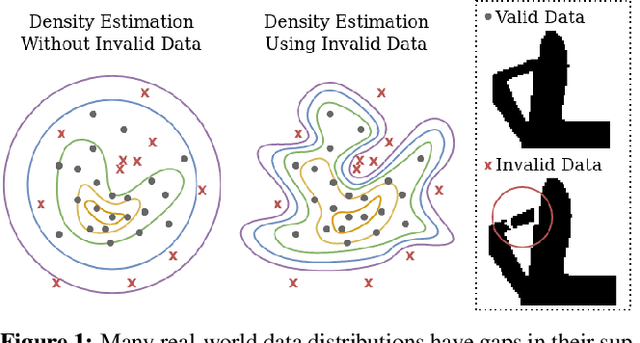

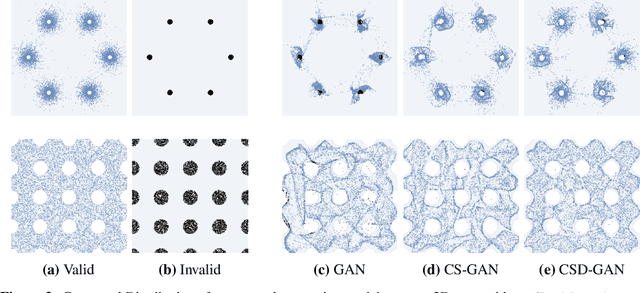
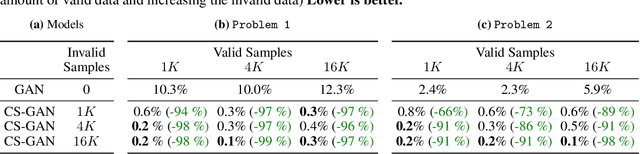
Generative models have demonstrated impressive results in vision, language, and speech. However, even with massive datasets, they struggle with precision, generating physically invalid or factually incorrect data. This is particularly problematic when the generated data must satisfy constraints, for example, to meet product specifications in engineering design or to adhere to the laws of physics in a natural scene. To improve precision while preserving diversity and fidelity, we propose a novel training mechanism that leverages datasets of constraint-violating data points, which we consider invalid. Our approach minimizes the divergence between the generative distribution and the valid prior while maximizing the divergence with the invalid distribution. We demonstrate how generative models like GANs and DDPMs that we augment to train with invalid data vastly outperform their standard counterparts which solely train on valid data points. For example, our training procedure generates up to 98 % fewer invalid samples on 2D densities, improves connectivity and stability four-fold on a stacking block problem, and improves constraint satisfaction by 15 % on a structural topology optimization benchmark in engineering design. We also analyze how the quality of the invalid data affects the learning procedure and the generalization properties of models. Finally, we demonstrate significant improvements in sample efficiency, showing that a tenfold increase in valid samples leads to a negligible difference in constraint satisfaction, while less than 10 % invalid samples lead to a tenfold improvement. Our proposed mechanism offers a promising solution for improving precision in generative models while preserving diversity and fidelity, particularly in domains where constraint satisfaction is critical and data is limited, such as engineering design, robotics, and medicine.
Reducing Barriers to Self-Supervised Learning: HuBERT Pre-training with Academic Compute
Jun 11, 2023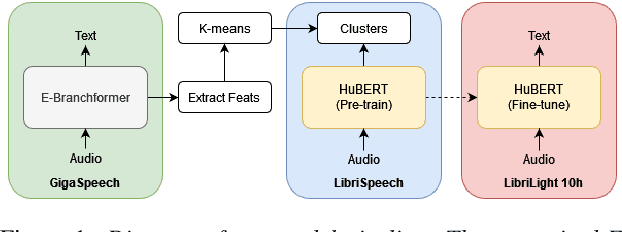
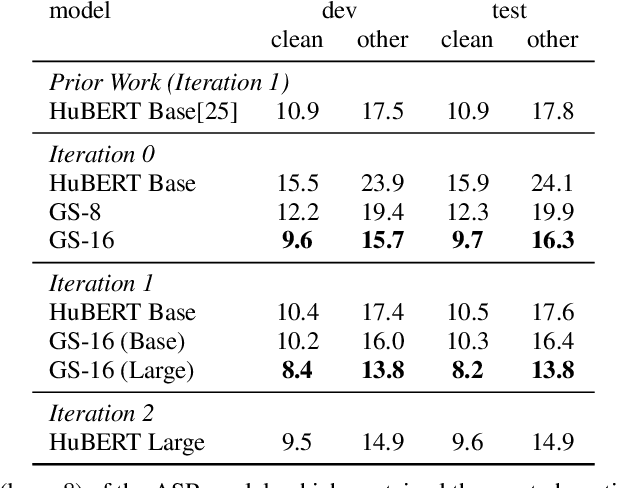
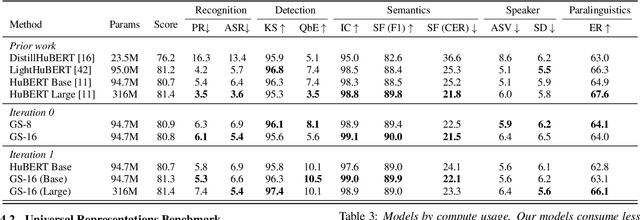
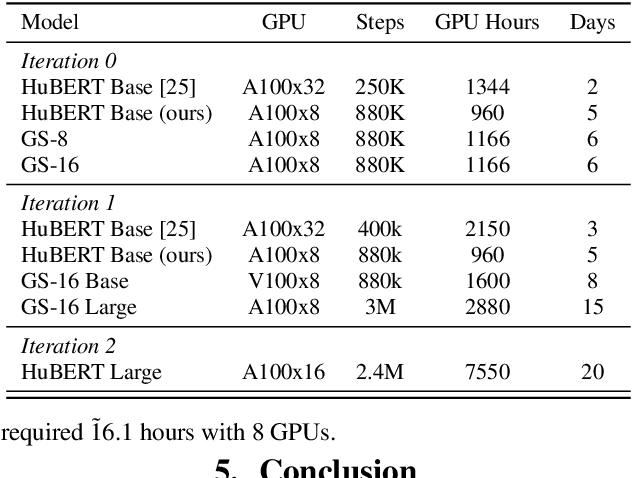
Self-supervised learning (SSL) has led to great strides in speech processing. However, the resources needed to train these models has become prohibitively large as they continue to scale. Currently, only a few groups with substantial resources are capable of creating SSL models, which harms reproducibility. In this work, we optimize HuBERT SSL to fit in academic constraints. We reproduce HuBERT independently from the original implementation, with no performance loss. Our code and training optimizations make SSL feasible with only 8 GPUs, instead of the 32 used in the original work. We also explore a semi-supervised route, using an ASR model to skip the first pre-training iteration. Within one iteration of pre-training, our models improve over HuBERT on several tasks. Furthermore, our HuBERT Large variant requires only 8 GPUs, achieving similar performance to the original trained on 128. As our contribution to the community, all models, configurations, and code are made open-source in ESPnet.
LEACE: Perfect linear concept erasure in closed form
Jun 06, 2023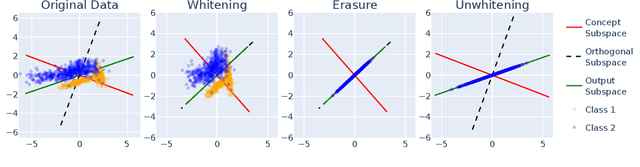
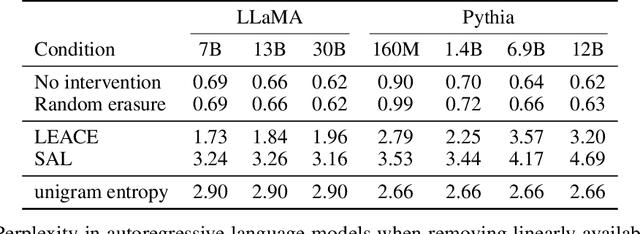
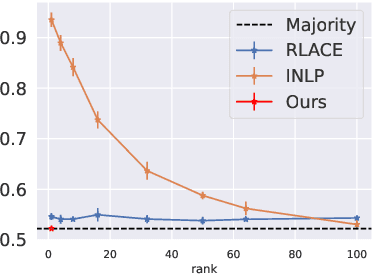
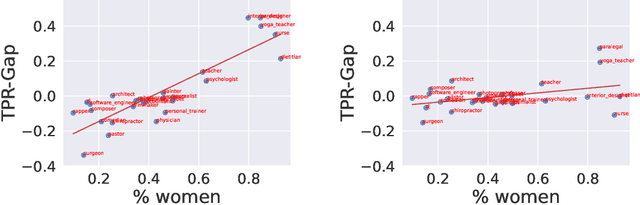
Concept erasure aims to remove specified features from a representation. It can be used to improve fairness (e.g. preventing a classifier from using gender or race) and interpretability (e.g. removing a concept to observe changes in model behavior). In this paper, we introduce LEAst-squares Concept Erasure (LEACE), a closed-form method which provably prevents all linear classifiers from detecting a concept while inflicting the least possible damage to the representation. We apply LEACE to large language models with a novel procedure called "concept scrubbing," which erases target concept information from every layer in the network. We demonstrate the usefulness of our method on two tasks: measuring the reliance of language models on part-of-speech information, and reducing gender bias in BERT embeddings. Code is available at https://github.com/EleutherAI/concept-erasure.
Automatic Assessment of Oral Reading Accuracy for Reading Diagnostics
Jun 06, 2023

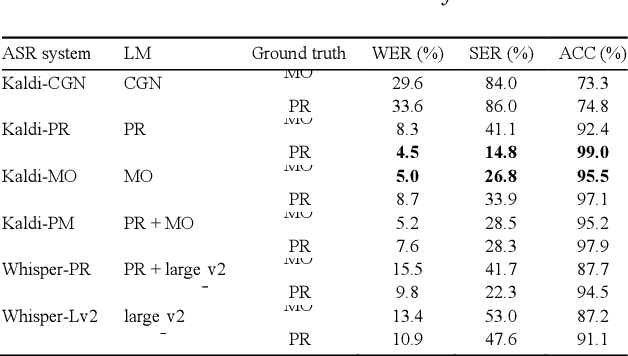
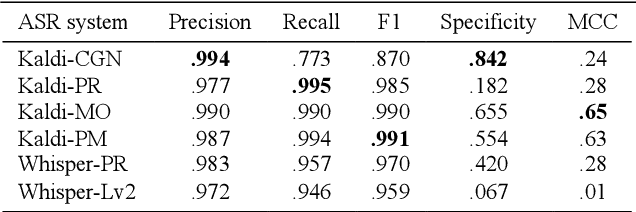
Automatic assessment of reading fluency using automatic speech recognition (ASR) holds great potential for early detection of reading difficulties and subsequent timely intervention. Precise assessment tools are required, especially for languages other than English. In this study, we evaluate six state-of-the-art ASR-based systems for automatically assessing Dutch oral reading accuracy using Kaldi and Whisper. Results show our most successful system reached substantial agreement with human evaluations (MCC = .63). The same system reached the highest correlation between forced decoding confidence scores and word correctness (r = .45). This system's language model (LM) consisted of manual orthographic transcriptions and reading prompts of the test data, which shows that including reading errors in the LM improves assessment performance. We discuss the implications for developing automatic assessment systems and identify possible avenues of future research.
Speech Driven Video Editing via an Audio-Conditioned Diffusion Model
Jan 12, 2023
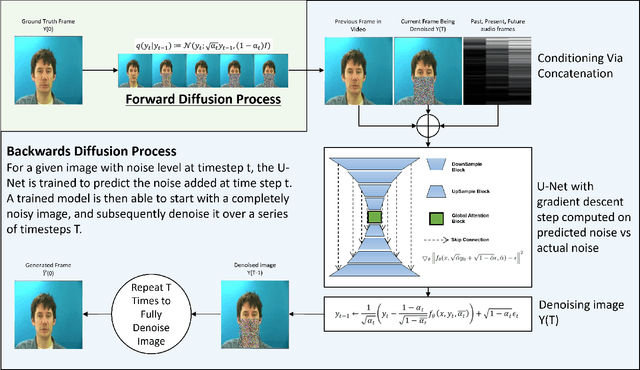
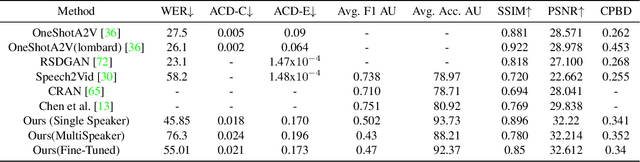
In this paper we propose a method for end-to-end speech driven video editing using a denoising diffusion model. Given a video of a person speaking, we aim to re-synchronise the lip and jaw motion of the person in response to a separate auditory speech recording without relying on intermediate structural representations such as facial landmarks or a 3D face model. We show this is possible by conditioning a denoising diffusion model with audio spectral features to generate synchronised facial motion. We achieve convincing results on the task of unstructured single-speaker video editing, achieving a word error rate of 45% using an off the shelf lip reading model. We further demonstrate how our approach can be extended to the multi-speaker domain. To our knowledge, this is the first work to explore the feasibility of applying denoising diffusion models to the task of audio-driven video editing.
Learning From Yourself: A Self-Distillation Method for Fake Speech Detection
Mar 02, 2023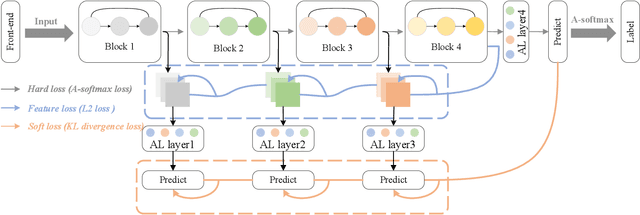
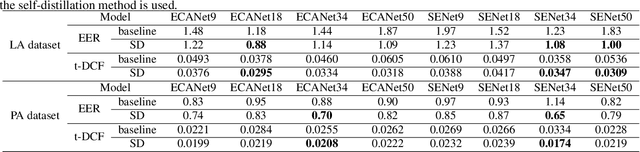
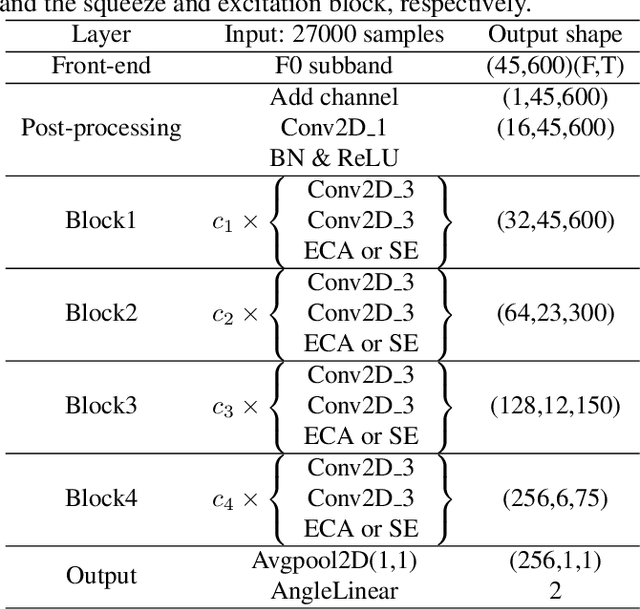
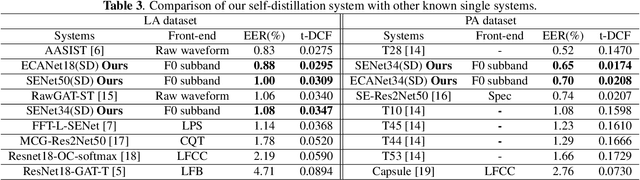
In this paper, we propose a novel self-distillation method for fake speech detection (FSD), which can significantly improve the performance of FSD without increasing the model complexity. For FSD, some fine-grained information is very important, such as spectrogram defects, mute segments, and so on, which are often perceived by shallow networks. However, shallow networks have much noise, which can not capture this very well. To address this problem, we propose using the deepest network instruct shallow network for enhancing shallow networks. Specifically, the networks of FSD are divided into several segments, the deepest network being used as the teacher model, and all shallow networks become multiple student models by adding classifiers. Meanwhile, the distillation path between the deepest network feature and shallow network features is used to reduce the feature difference. A series of experimental results on the ASVspoof 2019 LA and PA datasets show the effectiveness of the proposed method, with significant improvements compared to the baseline.
Record Deduplication for Entity Distribution Modeling in ASR Transcripts
Jun 09, 2023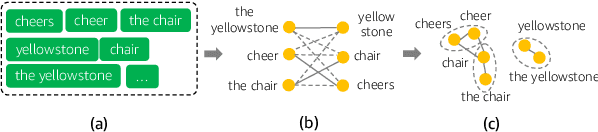
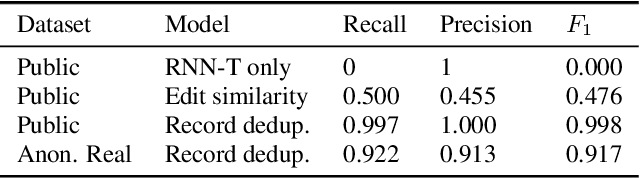
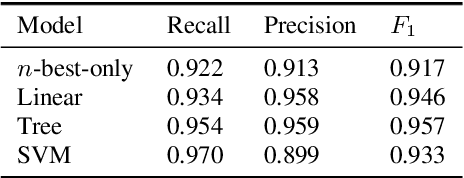

Voice digital assistants must keep up with trending search queries. We rely on a speech recognition model using contextual biasing with a rapidly updated set of entities, instead of frequent model retraining, to keep up with trends. There are several challenges with this approach: (1) the entity set must be frequently reconstructed, (2) the entity set is of limited size due to latency and accuracy trade-offs, and (3) finding the true entity distribution for biasing is complicated by ASR misrecognition. We address these challenges and define an entity set by modeling customers true requested entity distribution from ASR output in production using record deduplication, a technique from the field of entity resolution. Record deduplication resolves or deduplicates coreferences, including misrecognitions, of the same latent entity. Our method successfully retrieves 95% of misrecognized entities and when used for contextual biasing shows an estimated 5% relative word error rate reduction.