 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Voices: Generating A-Roll Video from Audio with Mirage
Jun 09, 2025



From professional filmmaking to user-generated content, creators and consumers have long recognized that the power of video depends on the harmonious integration of what we hear (the video's audio track) with what we see (the video's image sequence). Current approaches to video generation either ignore sound to focus on general-purpose but silent image sequence generation or address both visual and audio elements but focus on restricted application domains such as re-dubbing. We introduce Mirage, an audio-to-video foundation model that excels at generating realistic, expressive output imagery from scratch given an audio input. When integrated with existing methods for speech synthesis (text-to-speech, or TTS), Mirage results in compelling multimodal video. When trained on audio-video footage of people talking (A-roll) and conditioned on audio containing speech, Mirage generates video of people delivering a believable interpretation of the performance implicit in input audio. Our central technical contribution is a unified method for training self-attention-based audio-to-video generation models, either from scratch or given existing weights. This methodology allows Mirage to retain generality as an approach to audio-to-video generation while producing outputs of superior subjective quality to methods that incorporate audio-specific architectures or loss components specific to people, speech, or details of how images or audio are captured. We encourage readers to watch and listen to the results of Mirage for themselves (see paper and comments for links).
LatentColorization: Latent Diffusion-Based Speaker Video Colorization
May 09, 2024While current research predominantly focuses on image-based colorization, the domain of video-based colorization remains relatively unexplored. Most existing video colorization techniques operate on a frame-by-frame basis, often overlooking the critical aspect of temporal coherence between successive frames. This approach can result in inconsistencies across frames, leading to undesirable effects like flickering or abrupt color transitions between frames. To address these challenges, we harness the generative capabilities of a fine-tuned latent diffusion model designed specifically for video colorization, introducing a novel solution for achieving temporal consistency in video colorization, as well as demonstrating strong improvements on established image quality metrics compared to other existing methods. Furthermore, we perform a subjective study, where users preferred our approach to the existing state of the art. Our dataset encompasses a combination of conventional datasets and videos from television/movies. In short, by leveraging the power of a fine-tuned latent diffusion-based colorization system with a temporal consistency mechanism, we can improve the performance of automatic video colorization by addressing the challenges of temporal inconsistency. A short demonstration of our results can be seen in some example videos available at https://youtu.be/vDbzsZdFuxM.
Synthetic Speaking Children -- Why We Need Them and How to Make Them
Nov 08, 2023



Contemporary Human Computer Interaction (HCI) research relies primarily on neural network models for machine vision and speech understanding of a system user. Such models require extensively annotated training datasets for optimal performance and when building interfaces for users from a vulnerable population such as young children, GDPR introduces significant complexities in data collection, management, and processing. Motivated by the training needs of an Edge AI smart toy platform this research explores the latest advances in generative neural technologies and provides a working proof of concept of a controllable data generation pipeline for speech driven facial training data at scale. In this context, we demonstrate how StyleGAN2 can be finetuned to create a gender balanced dataset of children's faces. This dataset includes a variety of controllable factors such as facial expressions, age variations, facial poses, and even speech-driven animations with realistic lip synchronization. By combining generative text to speech models for child voice synthesis and a 3D landmark based talking heads pipeline, we can generate highly realistic, entirely synthetic, talking child video clips. These video clips can provide valuable, and controllable, synthetic training data for neural network models, bridging the gap when real data is scarce or restricted due to privacy regulations.
Speech Driven Video Editing via an Audio-Conditioned Diffusion Model
Jan 12, 2023



In this paper we propose a method for end-to-end speech driven video editing using a denoising diffusion model. Given a video of a person speaking, we aim to re-synchronise the lip and jaw motion of the person in response to a separate auditory speech recording without relying on intermediate structural representations such as facial landmarks or a 3D face model. We show this is possible by conditioning a denoising diffusion model with audio spectral features to generate synchronised facial motion. We achieve convincing results on the task of unstructured single-speaker video editing, achieving a word error rate of 45% using an off the shelf lip reading model. We further demonstrate how our approach can be extended to the multi-speaker domain. To our knowledge, this is the first work to explore the feasibility of applying denoising diffusion models to the task of audio-driven video editing.
Can Self-Supervised Learning solve the problem of child speech recognition?
Apr 06, 2022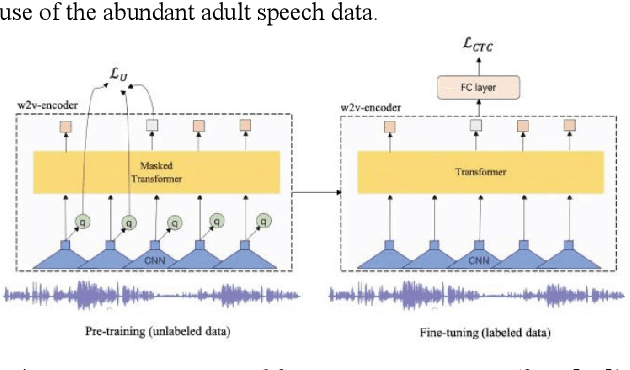
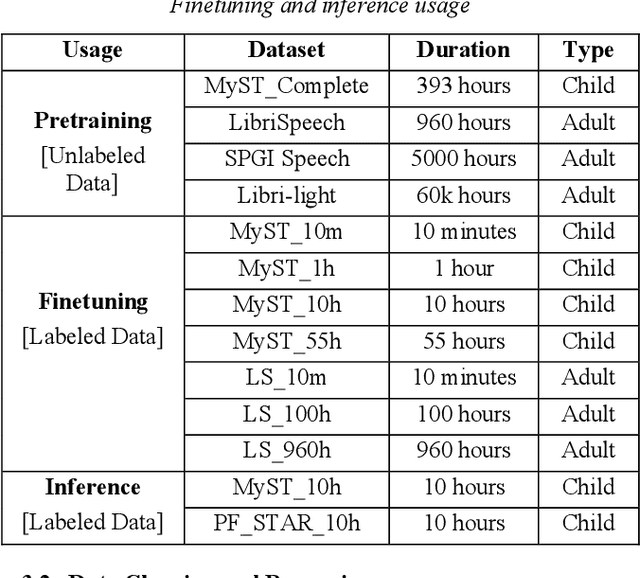
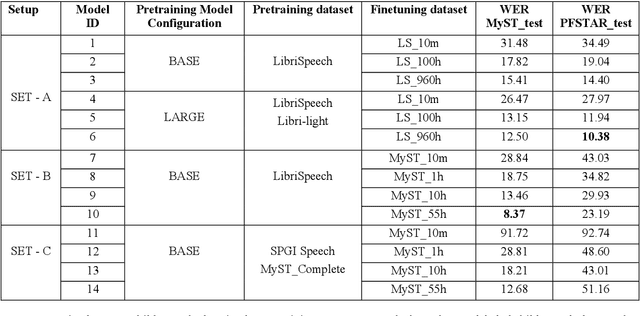
Despite recent advancements in deep learning technologies, Child Speech Recognition remains a challenging task. Current Automatic Speech Recognition (ASR) models required substantial amounts of annotated data for training, which is scarce. In this work, we explore using the ASR model, wav2vec2, with different pretraining and finetuning configurations for self supervised learning (SSL) towards improving automatic child speech recognition. The pretrained wav2vec2 models were finetuned using different amounts of child speech training data to discover the optimum amount of data required to finetune the model for the task of child ASR. Our trained model receives the best word error rate (WER) of 8.37 on the in domain MyST dataset and WER of 10.38 on the out of domain PFSTAR dataset. We do not use any Language Models (LM) in our experiments.
A Text-to-Speech Pipeline, Evaluation Methodology, and Initial Fine-Tuning Results for Child Speech Synthesis
Apr 04, 2022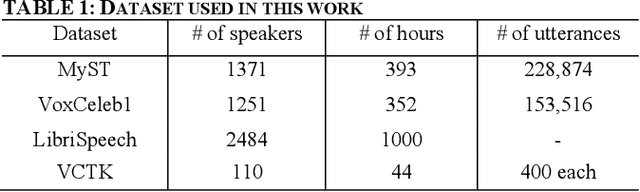
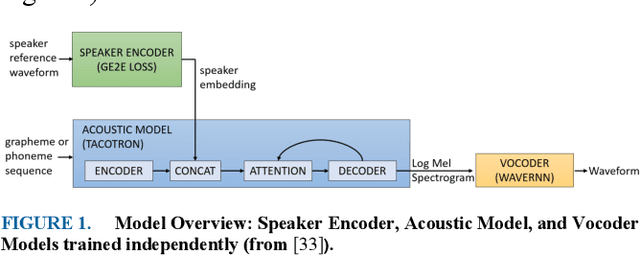
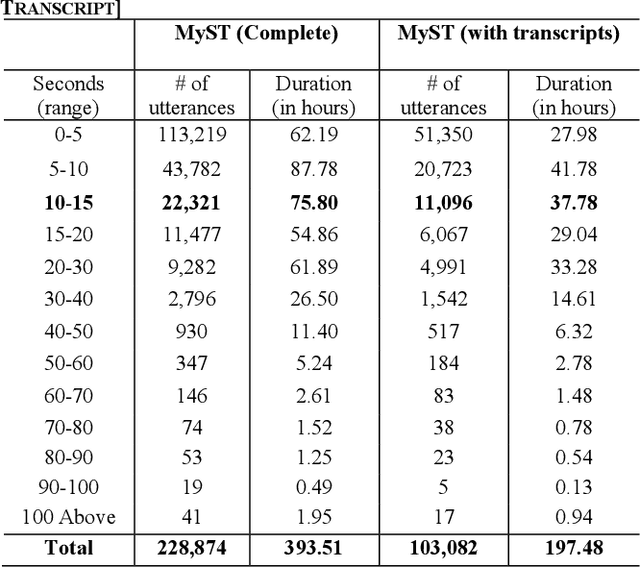
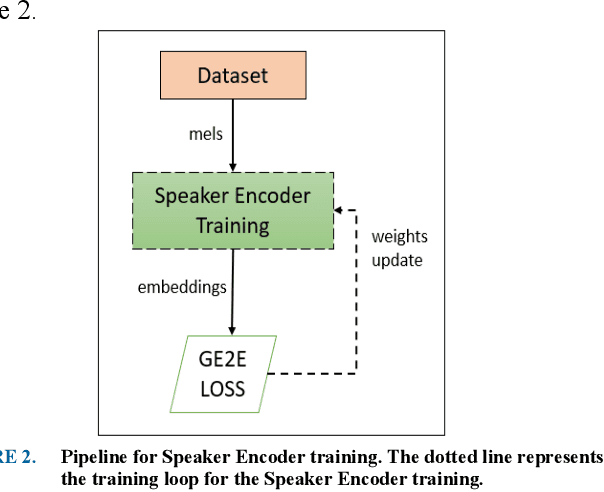
Speech synthesis has come a long way as current text-to-speech (TTS) models can now generate natural human-sounding speech. However, most of the TTS research focuses on using adult speech data and there has been very limited work done on child speech synthesis. This study developed and validated a training pipeline for fine-tuning state-of-the-art (SOTA) neural TTS models using child speech datasets. This approach adopts a multi-speaker TTS retuning workflow to provide a transfer-learning pipeline. A publicly available child speech dataset was cleaned to provide a smaller subset of approximately 19 hours, which formed the basis of our fine-tuning experiments. Both subjective and objective evaluations were performed using a pretrained MOSNet for objective evaluation and a novel subjective framework for mean opinion score (MOS) evaluations. Subjective evaluations achieved the MOS of 3.95 for speech intelligibility, 3.89 for voice naturalness, and 3.96 for voice consistency. Objective evaluation using a pretrained MOSNet showed a strong correlation between real and synthetic child voices. Speaker similarity was also verified by calculating the cosine similarity between the embeddings of utterances. An automatic speech recognition (ASR) model is also used to provide a word error rate (WER) comparison between the real and synthetic child voices. The final trained TTS model was able to synthesize child-like speech from reference audio samples as short as 5 seconds.