 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
deHuBERT: Disentangling Noise in a Self-supervised Model for Robust Speech Recognition
Feb 28, 2023
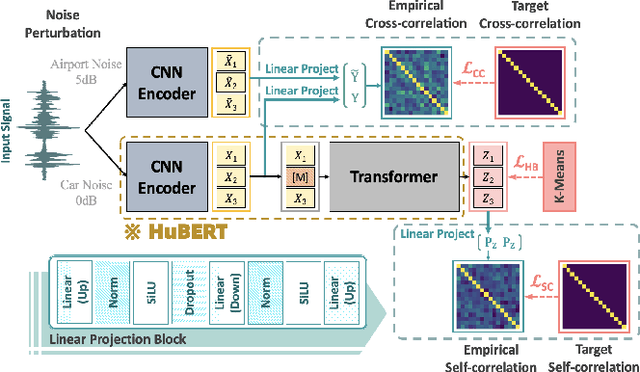
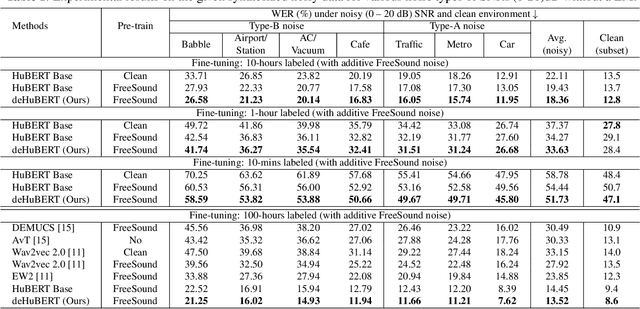

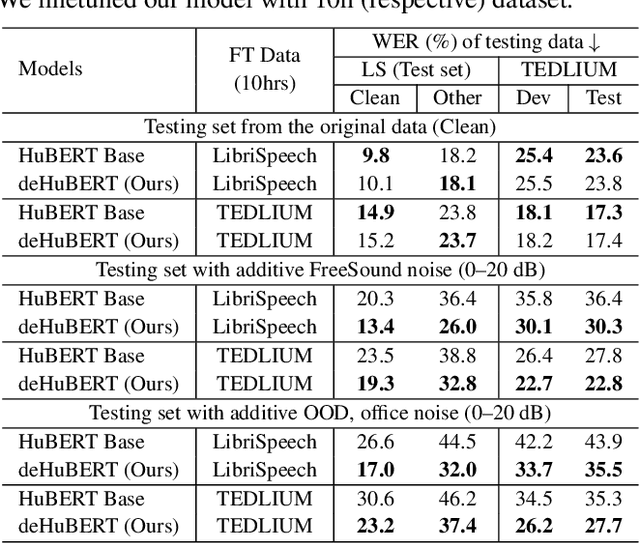
Existing self-supervised pre-trained speech models have offered an effective way to leverage massive unannotated corpora to build good automatic speech recognition (ASR). However, many current models are trained on a clean corpus from a single source, which tends to do poorly when noise is present during testing. Nonetheless, it is crucial to overcome the adverse influence of noise for real-world applications. In this work, we propose a novel training framework, called deHuBERT, for noise reduction encoding inspired by H. Barlow's redundancy-reduction principle. The new framework improves the HuBERT training algorithm by introducing auxiliary losses that drive the self- and cross-correlation matrix between pairwise noise-distorted embeddings towards identity matrix. This encourages the model to produce noise-agnostic speech representations. With this method, we report improved robustness in noisy environments, including unseen noises, without impairing the performance on the clean set.
Masking Kernel for Learning Energy-Efficient Speech Representation
Feb 08, 2023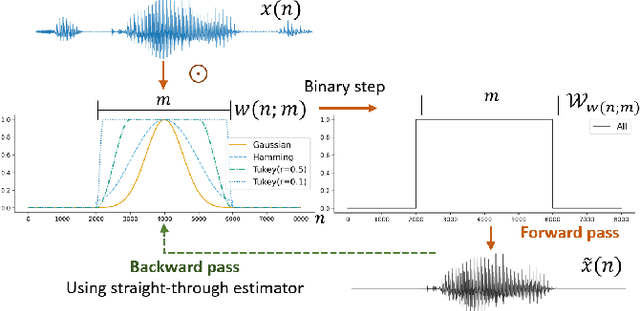
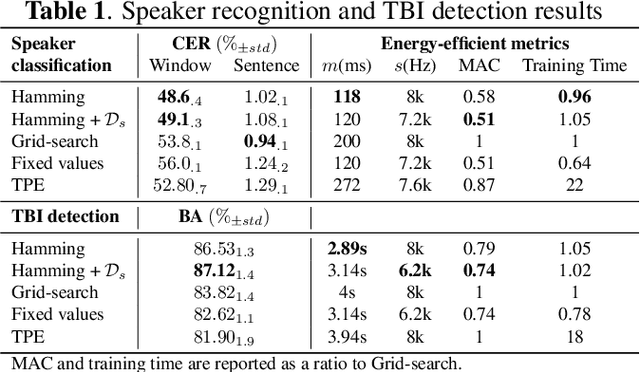

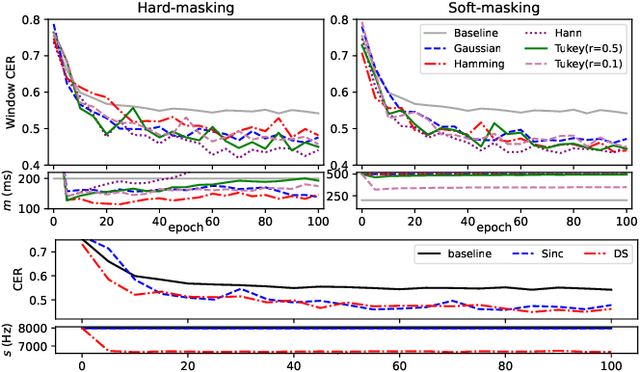
Modern smartphones are equipped with powerful audio hardware and processors, allowing them to acquire and perform on-device speech processing at high sampling rates. However, energy consumption remains a concern, especially for resource-intensive DNNs. Prior mobile speech processing reduced computational complexity by compacting the model or reducing input dimensions via hyperparameter tuning, which reduced accuracy or required more training iterations. This paper proposes gradient descent for optimizing energy-efficient speech recording format (length and sampling rate). The goal is to reduce the input size, which reduces data collection and inference energy. For a backward pass, a masking function with non-zero derivatives (Gaussian, Hann, and Hamming) is used as a windowing function and a lowpass filter. An energy-efficient penalty is introduced to incentivize the reduction of the input size. The proposed masking outperformed baselines by 8.7% in speaker recognition and traumatic brain injury detection using 49% shorter duration, sampled at a lower frequency.
Computational Language Assessment: Open Brain AI
Jun 11, 2023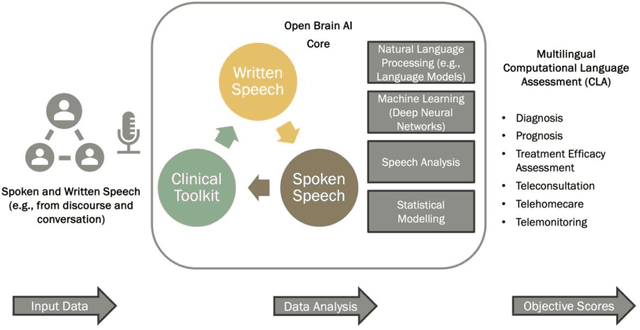
Language assessment plays a crucial role in diagnosing and treating individuals with speech, language, and communication disorders caused by neurogenic conditions, whether developmental or acquired. However, traditional manual assessment methods have several drawbacks. They are often laborious and time-consuming to administer and score, causing additional patient stress. Moreover, they divert valuable resources from treatment. To address these challenges, we introduce Open Brain AI (openbrainai.com), a computational platform that harnesses innovative AI techniques, including machine learning and natural language processing, to automatically analyze spoken and written speech productions. The platform leverages state-of-the-art AI techniques and aims to present a promising advancement in language assessment. Its ability to provide reliable and efficient measurements can enhance the accuracy of diagnoses and optimize treatment strategies for individuals with speech, language, and communication disorders. Furthermore, the automation and objectivity offered by the platform alleviate the burden on clinicians, enabling them to streamline their workflow and allocate more time and resources to direct patient care. Notably, the platform is freely accessible, empowering clinicians to conduct critical analyses of their data and allowing them to allocate more attention to other critical aspects of therapy and treatment.
The defender's perspective on automatic speaker verification: An overview
May 22, 2023

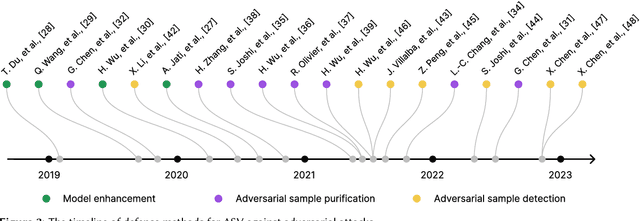
Automatic speaker verification (ASV) plays a critical role in security-sensitive environments. Regrettably, the reliability of ASV has been undermined by the emergence of spoofing attacks, such as replay and synthetic speech, as well as adversarial attacks and the relatively new partially fake speech. While there are several review papers that cover replay and synthetic speech, and adversarial attacks, there is a notable gap in a comprehensive review that addresses defense against adversarial attacks and the recently emerged partially fake speech. Thus, the aim of this paper is to provide a thorough and systematic overview of the defense methods used against these types of attacks.
Impact of Experiencing Misrecognition by Teachable Agents on Learning and Rapport
Jun 11, 2023

While speech-enabled teachable agents have some advantages over typing-based ones, they are vulnerable to errors stemming from misrecognition by automatic speech recognition (ASR). These errors may propagate, resulting in unexpected changes in the flow of conversation. We analyzed how such changes are linked with learning gains and learners' rapport with the agents. Our results show they are not related to learning gains or rapport, regardless of the types of responses the agents should have returned given the correct input from learners without ASR errors. We also discuss the implications for optimal error-recovery policies for teachable agents that can be drawn from these findings.
Testing Hateful Speeches against Policies
Jul 23, 2023In the recent years, many software systems have adopted AI techniques, especially deep learning techniques. Due to their black-box nature, AI-based systems brought challenges to traceability, because AI system behaviors are based on models and data, whereas the requirements or policies are rules in the form of natural or programming language. To the best of our knowledge, there is a limited amount of studies on how AI and deep neural network-based systems behave against rule-based requirements/policies. This experience paper examines deep neural network behaviors against rule-based requirements described in natural language policies. In particular, we focus on a case study to check AI-based content moderation software against content moderation policies. First, using crowdsourcing, we collect natural language test cases which match each moderation policy, we name this dataset HateModerate; second, using the test cases in HateModerate, we test the failure rates of state-of-the-art hate speech detection software, and we find that these models have high failure rates for certain policies; finally, since manual labeling is costly, we further proposed an automated approach to augument HateModerate by finetuning OpenAI's large language models to automatically match new examples to policies. The dataset and code of this work can be found on our anonymous website: \url{https://sites.google.com/view/content-moderation-project}.
ACO-tagger: A Novel Method for Part-of-Speech Tagging using Ant Colony Optimization
Mar 27, 2023
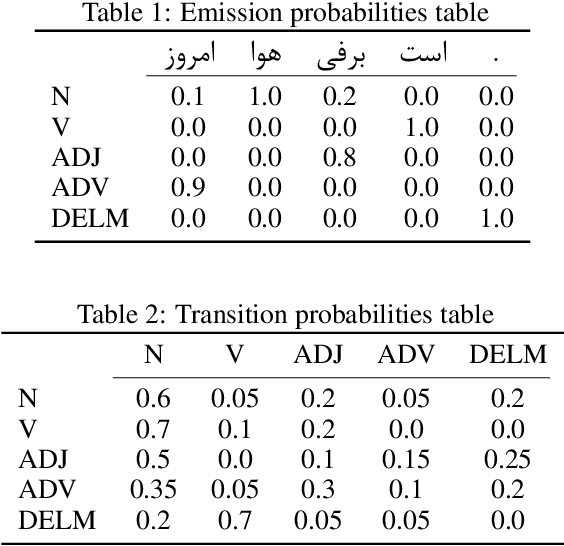
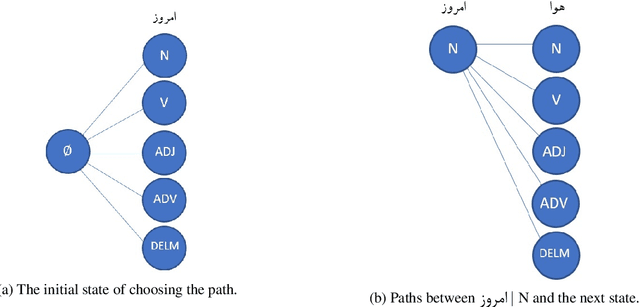

Swarm Intelligence algorithms have gained significant attention in recent years as a means of solving complex and non-deterministic problems. These algorithms are inspired by the collective behavior of natural creatures, and they simulate this behavior to develop intelligent agents for computational tasks. One such algorithm is Ant Colony Optimization (ACO), which is inspired by the foraging behavior of ants and their pheromone laying mechanism. ACO is used for solving difficult problems that are discrete and combinatorial in nature. Part-of-Speech (POS) tagging is a fundamental task in natural language processing that aims to assign a part-of-speech role to each word in a sentence. In this research paper, proposed a high-performance POS-tagging method based on ACO called ACO-tagger. This method achieved a high accuracy rate of 96.867%, outperforming several state-of-the-art methods. The proposed method is fast and efficient, making it a viable option for practical applications.
Unsupervised Domain Adaptation using Lexical Transformations and Label Injection for Twitter Data
Jul 14, 2023


Domain adaptation is an important and widely studied problem in natural language processing. A large body of literature tries to solve this problem by adapting models trained on the source domain to the target domain. In this paper, we instead solve this problem from a dataset perspective. We modify the source domain dataset with simple lexical transformations to reduce the domain shift between the source dataset distribution and the target dataset distribution. We find that models trained on the transformed source domain dataset performs significantly better than zero-shot models. Using our proposed transformations to convert standard English to tweets, we reach an unsupervised part-of-speech (POS) tagging accuracy of 92.14% (from 81.54% zero shot accuracy), which is only slightly below the supervised performance of 94.45%. We also use our proposed transformations to synthetically generate tweets and augment the Twitter dataset to achieve state-of-the-art performance for POS tagging.
Joint Pre-Training with Speech and Bilingual Text for Direct Speech to Speech Translation
Oct 31, 2022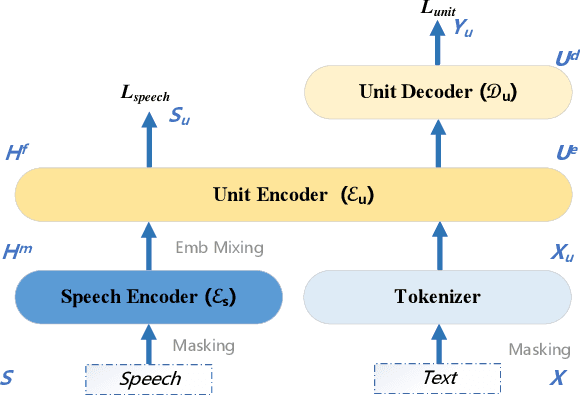
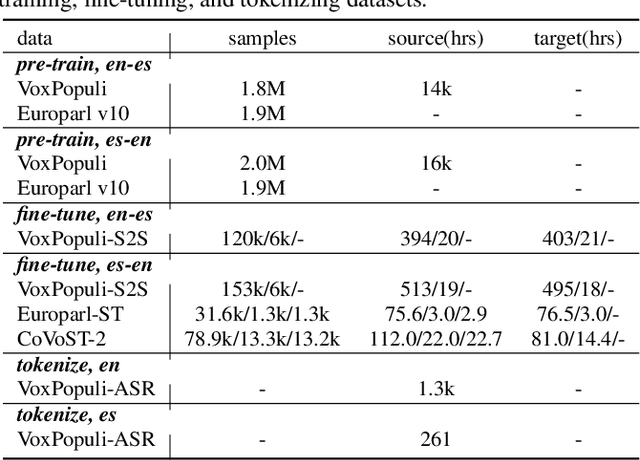
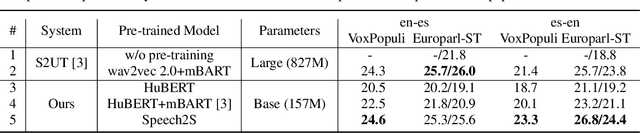
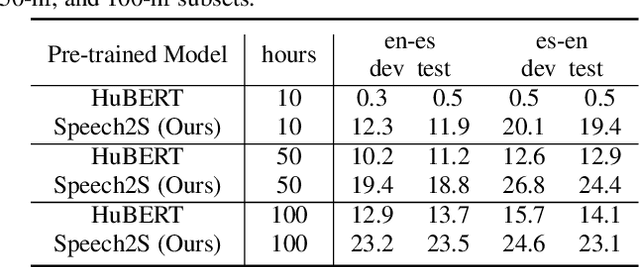
Direct speech-to-speech translation (S2ST) is an attractive research topic with many advantages compared to cascaded S2ST. However, direct S2ST suffers from the data scarcity problem because the corpora from speech of the source language to speech of the target language are very rare. To address this issue, we propose in this paper a Speech2S model, which is jointly pre-trained with unpaired speech and bilingual text data for direct speech-to-speech translation tasks. By effectively leveraging the paired text data, Speech2S is capable of modeling the cross-lingual speech conversion from source to target language. We verify the performance of the proposed Speech2S on Europarl-ST and VoxPopuli datasets. Experimental results demonstrate that Speech2S gets an improvement of about 5 BLEU scores compared to encoder-only pre-training models, and achieves a competitive or even better performance than existing state-of-the-art models1.
Metric-oriented Speech Enhancement using Diffusion Probabilistic Model
Feb 23, 2023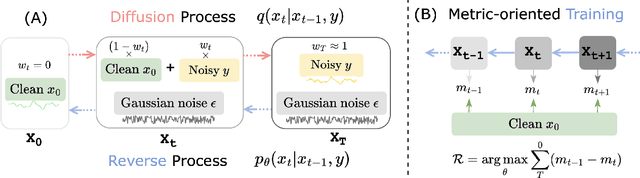
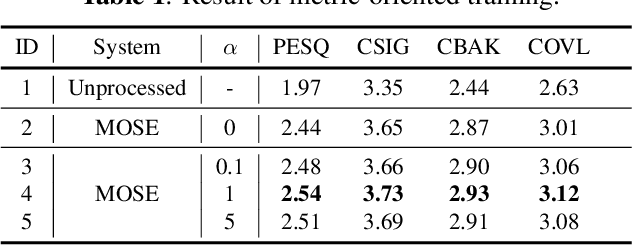
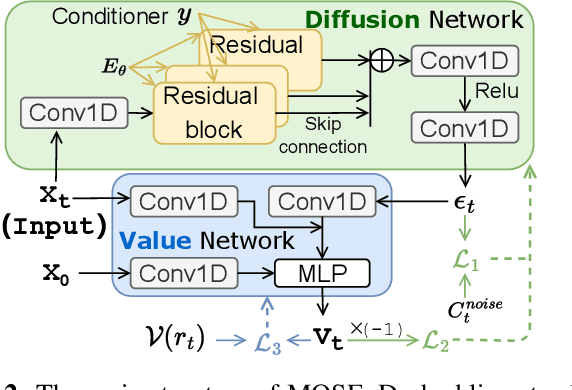
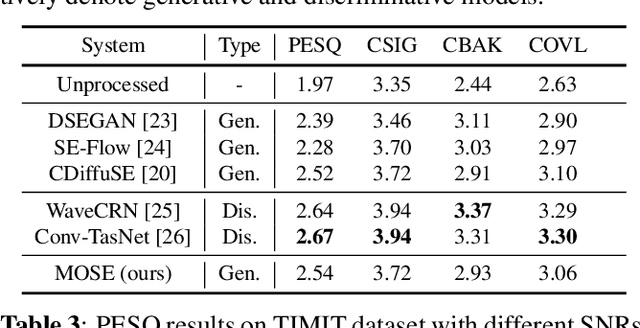
Deep neural network based speech enhancement technique focuses on learning a noisy-to-clean transformation supervised by paired training data. However, the task-specific evaluation metric (e.g., PESQ) is usually non-differentiable and can not be directly constructed in the training criteria. This mismatch between the training objective and evaluation metric likely results in sub-optimal performance. To alleviate it, we propose a metric-oriented speech enhancement method (MOSE), which leverages the recent advances in the diffusion probabilistic model and integrates a metric-oriented training strategy into its reverse process. Specifically, we design an actor-critic based framework that considers the evaluation metric as a posterior reward, thus guiding the reverse process to the metric-increasing direction. The experimental results demonstrate that MOSE obviously benefits from metric-oriented training and surpasses the generative baselines in terms of all evaluation metrics.