 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid LLM-Embedded Dialogue Agents for Learner Reflection: Designing Responsive and Theory-Driven Interactions
Feb 24, 2026Dialogue systems have long supported learner reflections, with theoretically grounded, rule-based designs offering structured scaffolding but often struggling to respond to shifts in engagement. Large Language Models (LLMs), in contrast, can generate context-sensitive responses but are not informed by decades of research on how learning interactions should be structured, raising questions about their alignment with pedagogical theories. This paper presents a hybrid dialogue system that embeds LLM responsiveness within a theory-aligned, rule-based framework to support learner reflections in a culturally responsive robotics summer camp. The rule-based structure grounds dialogue in self-regulated learning theory, while the LLM decides when and how to prompt deeper reflections, responding to evolving conversation context. We analyze themes across dialogues to explore how our hybrid system shaped learner reflections. Our findings indicate that LLM-embedded dialogues supported richer learner reflections on goals and activities, but also introduced challenges due to repetitiveness and misalignment in prompts, reducing engagement.
What metrics of participation balance predict outcomes of collaborative learning with a robot?
May 17, 2024



One of the keys to the success of collaborative learning is balanced participation by all learners, but this does not always happen naturally. Pedagogical robots have the potential to facilitate balance. However, it remains unclear what participation balance robots should aim at; various metrics have been proposed, but it is still an open question whether we should balance human participation in human-human interactions (HHI) or human-robot interactions (HRI) and whether we should consider robots' participation in collaborative learning involving multiple humans and a robot. This paper examines collaborative learning between a pair of students and a teachable robot that acts as a peer tutee to answer the aforementioned question. Through an exploratory study, we hypothesize which balance metrics in the literature and which portions of dialogues (including vs. excluding robots' participation and human participation in HHI vs. HRI) will better predict learning as a group. We test the hypotheses with another study and replicate them with automatically obtained units of participation to simulate the information available to robots when they adaptively fix imbalances in real-time. Finally, we discuss recommendations on which metrics learning science researchers should choose when trying to understand how to facilitate collaboration.
Impact of Experiencing Misrecognition by Teachable Agents on Learning and Rapport
Jun 11, 2023

While speech-enabled teachable agents have some advantages over typing-based ones, they are vulnerable to errors stemming from misrecognition by automatic speech recognition (ASR). These errors may propagate, resulting in unexpected changes in the flow of conversation. We analyzed how such changes are linked with learning gains and learners' rapport with the agents. Our results show they are not related to learning gains or rapport, regardless of the types of responses the agents should have returned given the correct input from learners without ASR errors. We also discuss the implications for optimal error-recovery policies for teachable agents that can be drawn from these findings.
Dominance as an Indicator of Rapport and Learning in Human-Agent Communication
Dec 05, 2022Power dynamics in human-human communication can impact rapport-building and learning gains, but little is known about how power impacts human-agent communication. In this paper, we examine dominance behavior in utterances between middle-school students and a teachable robot as they work through math problems, as coded by Rogers and Farace's Relational Communication Control Coding Scheme (RCCCS). We hypothesize that relatively dominant students will show increased learning gains, as will students with greater dominance agreement with the robot. We also hypothesize that gender could be an indicator of difference in dominance behavior. We present a preliminary analysis of dominance characteristics in some of the transactions between robot and student. Ultimately, we hope to determine if manipulating the dominance behavior of a learning robot could support learning.
Comparison of Lexical Alignment with a Teachable Robot in Human-Robot and Human-Human-Robot Interactions
Sep 23, 2022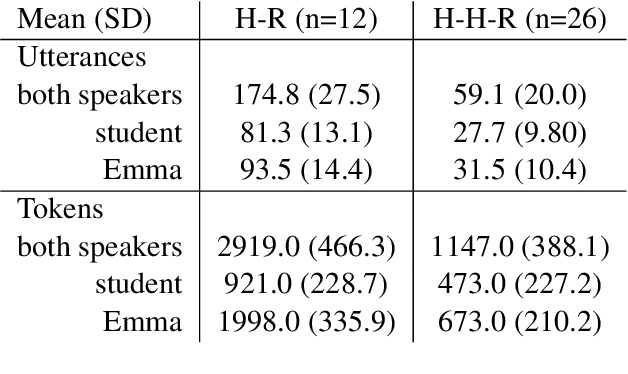
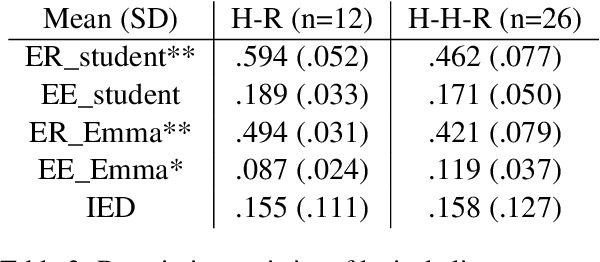

Speakers build rapport in the process of aligning conversational behaviors with each other. Rapport engendered with a teachable agent while instructing domain material has been shown to promote learning. Past work on lexical alignment in the field of education suffers from limitations in both the measures used to quantify alignment and the types of interactions in which alignment with agents has been studied. In this paper, we apply alignment measures based on a data-driven notion of shared expressions (possibly composed of multiple words) and compare alignment in one-on-one human-robot (H-R) interactions with the H-R portions of collaborative human-human-robot (H-H-R) interactions. We find that students in the H-R setting align with a teachable robot more than in the H-H-R setting and that the relationship between lexical alignment and rapport is more complex than what is predicted by previous theoretical and empirical work.
Words of Wisdom: Representational Harms in Learning From AI Communication
Nov 16, 2021
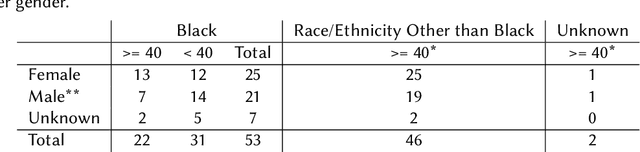
Many educational technologies use artificial intelligence (AI) that presents generated or produced language to the learner. We contend that all language, including all AI communication, encodes information about the identity of the human or humans who contributed to crafting the language. With AI communication, however, the user may index identity information that does not match the source. This can lead to representational harms if language associated with one cultural group is presented as "standard" or "neutral", if the language advantages one group over another, or if the language reinforces negative stereotypes. In this work, we discuss a case study using a Visual Question Generation (VQG) task involving gathering crowdsourced data from targeted demographic groups. Generated questions will be presented to human evaluators to understand how they index the identity behind the language, whether and how they perceive any representational harms, and how they would ideally address any such harms caused by AI communication. We reflect on the educational applications of this work as well as the implications for equality, diversity, and inclusion (EDI).