 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
A Study on the Reliability of Automatic Dysarthric Speech Assessments
Jun 07, 2023
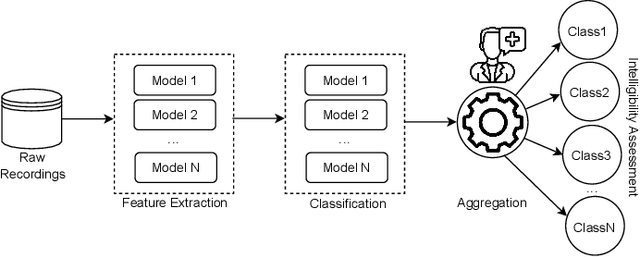
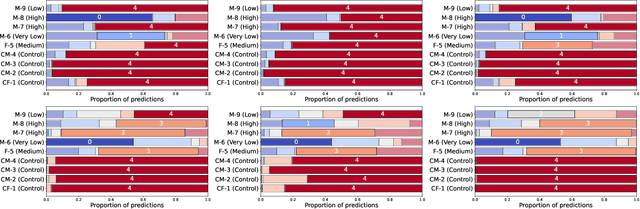
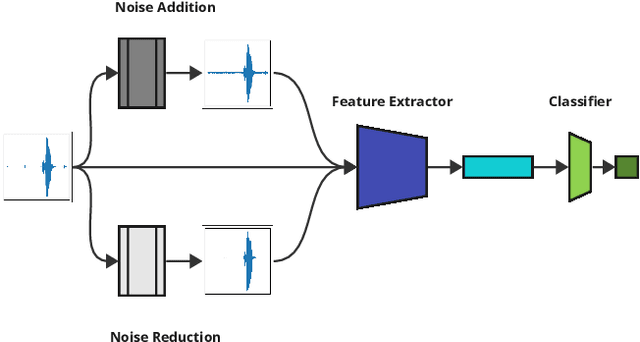
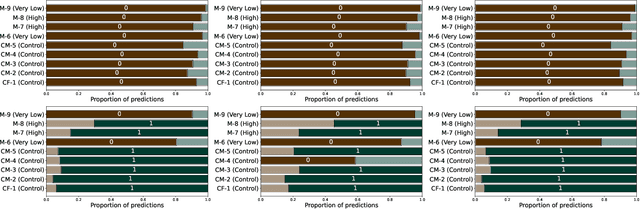
Automating dysarthria assessments offers the opportunity to develop effective, low-cost tools that address the current limitations of manual and subjective assessments. Nonetheless, it is unclear whether current approaches rely on dysarthria-related speech patterns or external factors. We aim toward obtaining a clearer understanding of dysarthria patterns. To this extent, we study the effects of noise in recordings, both through addition and reduction. We design and implement a new method for visualizing and comparing feature extractors and models, at a patient level, in a more interpretable way. We use the UA-Speech dataset with a speaker-based split of the dataset. Results reported in the literature appear to have been done irrespective of such split, leading to models that may be overconfident due to data-leakage. We hope that these results raise awareness in the research community regarding the requirements for establishing reliable automatic dysarthria assessment systems.
Enhancing Speaker Diarization with Large Language Models: A Contextual Beam Search Approach
Sep 14, 2023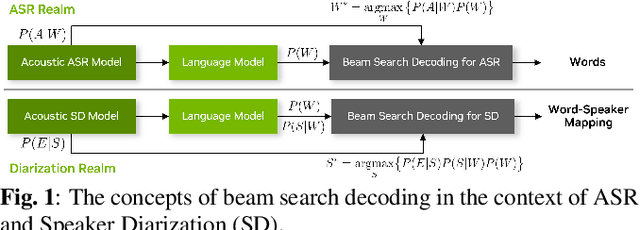
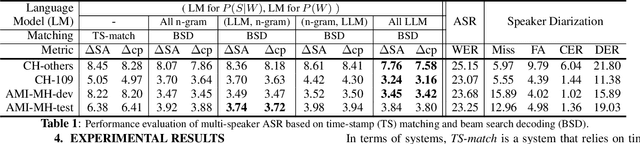

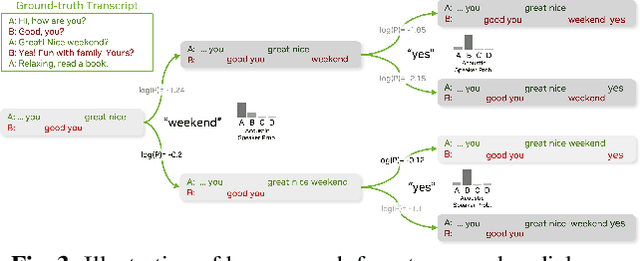
Large language models (LLMs) have shown great promise for capturing contextual information in natural language processing tasks. We propose a novel approach to speaker diarization that incorporates the prowess of LLMs to exploit contextual cues in human dialogues. Our method builds upon an acoustic-based speaker diarization system by adding lexical information from an LLM in the inference stage. We model the multi-modal decoding process probabilistically and perform joint acoustic and lexical beam search to incorporate cues from both modalities: audio and text. Our experiments demonstrate that infusing lexical knowledge from the LLM into an acoustics-only diarization system improves overall speaker-attributed word error rate (SA-WER). The experimental results show that LLMs can provide complementary information to acoustic models for the speaker diarization task via proposed beam search decoding approach showing up to 39.8% relative delta-SA-WER improvement from the baseline system. Thus, we substantiate that the proposed technique is able to exploit contextual information that is inaccessible to acoustics-only systems which is represented by speaker embeddings. In addition, these findings point to the potential of using LLMs to improve speaker diarization and other speech processing tasks by capturing semantic and contextual cues.
USM-SCD: Multilingual Speaker Change Detection Based on Large Pretrained Foundation Models
Sep 14, 2023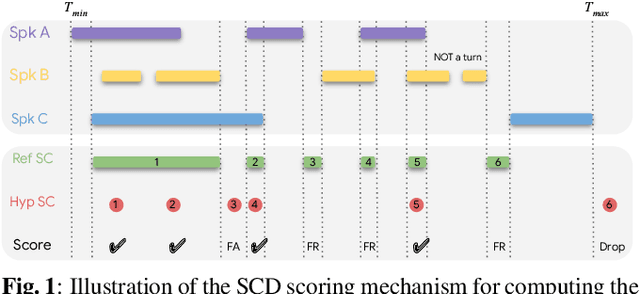
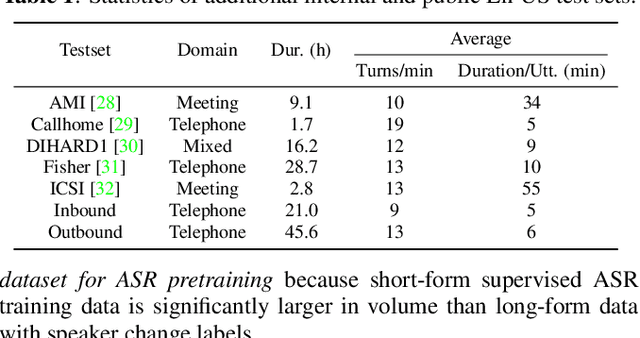
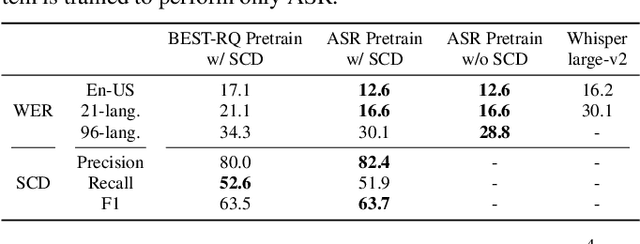
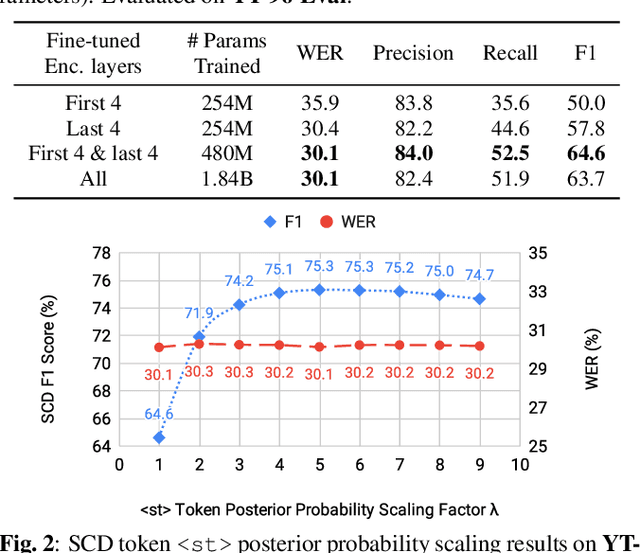
We introduce a multilingual speaker change detection model (USM-SCD) that can simultaneously detect speaker turns and perform ASR for 96 languages. This model is adapted from a speech foundation model trained on a large quantity of supervised and unsupervised data, demonstrating the utility of fine-tuning from a large generic foundation model for a downstream task. We analyze the performance of this multilingual speaker change detection model through a series of ablation studies. We show that the USM-SCD model can achieve more than 75% average speaker change detection F1 score across a test set that consists of data from 96 languages. On American English, the USM-SCD model can achieve an 85.8% speaker change detection F1 score across various public and internal test sets, beating the previous monolingual baseline model by 21% relative. We also show that we only need to fine-tune one-quarter of the trainable model parameters to achieve the best model performance. The USM-SCD model exhibits state-of-the-art ASR quality compared with a strong public ASR baseline, making it suitable to handle both tasks with negligible additional computational cost.
Quantifying the perceptual value of lexical and non-lexical channels in speech
Jul 07, 2023
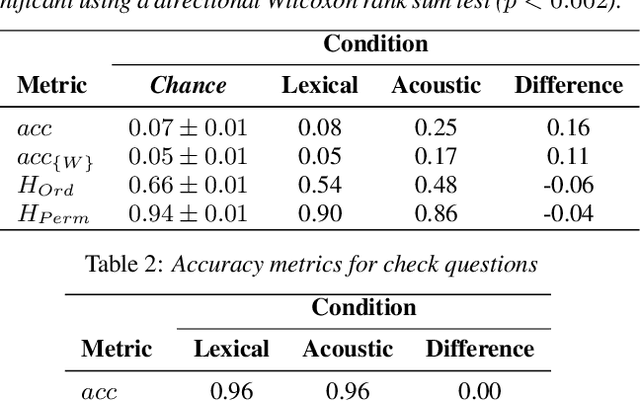
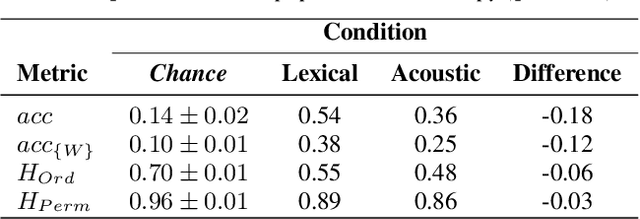
Speech is a fundamental means of communication that can be seen to provide two channels for transmitting information: the lexical channel of which words are said, and the non-lexical channel of how they are spoken. Both channels shape listener expectations of upcoming communication; however, directly quantifying their relative effect on expectations is challenging. Previous attempts require spoken variations of lexically-equivalent dialogue turns or conspicuous acoustic manipulations. This paper introduces a generalised paradigm to study the value of non-lexical information in dialogue across unconstrained lexical content. By quantifying the perceptual value of the non-lexical channel with both accuracy and entropy reduction, we show that non-lexical information produces a consistent effect on expectations of upcoming dialogue: even when it leads to poorer discriminative turn judgements than lexical content alone, it yields higher consensus among participants.
Multilingual Text-to-Speech Synthesis for Turkic Languages Using Transliteration
May 25, 2023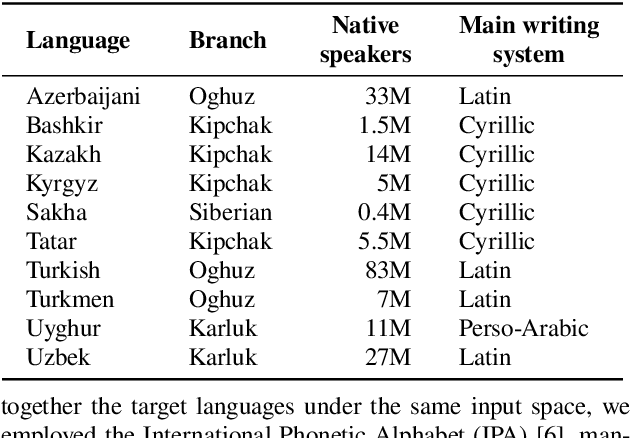
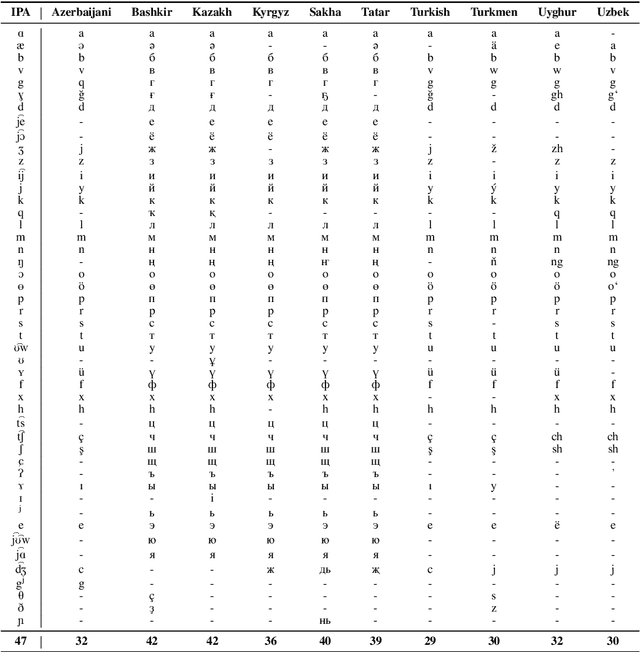
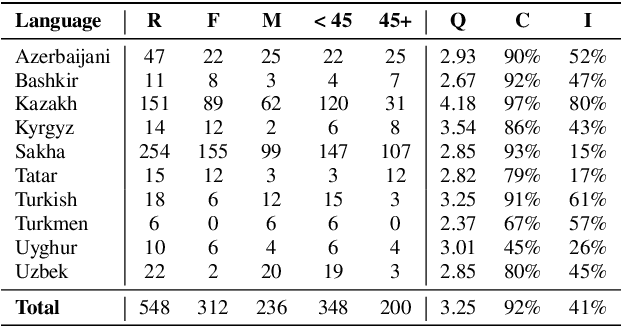
This work aims to build a multilingual text-to-speech (TTS) synthesis system for ten lower-resourced Turkic languages: Azerbaijani, Bashkir, Kazakh, Kyrgyz, Sakha, Tatar, Turkish, Turkmen, Uyghur, and Uzbek. We specifically target the zero-shot learning scenario, where a TTS model trained using the data of one language is applied to synthesise speech for other, unseen languages. An end-to-end TTS system based on the Tacotron 2 architecture was trained using only the available data of the Kazakh language. To generate speech for the other Turkic languages, we first mapped the letters of the Turkic alphabets onto the symbols of the International Phonetic Alphabet (IPA), which were then converted to the Kazakh alphabet letters. To demonstrate the feasibility of the proposed approach, we evaluated the multilingual Turkic TTS model subjectively and obtained promising results. To enable replication of the experiments, we make our code and dataset publicly available in our GitHub repository.
Automatic Data Augmentation for Domain Adapted Fine-Tuning of Self-Supervised Speech Representations
Jun 01, 2023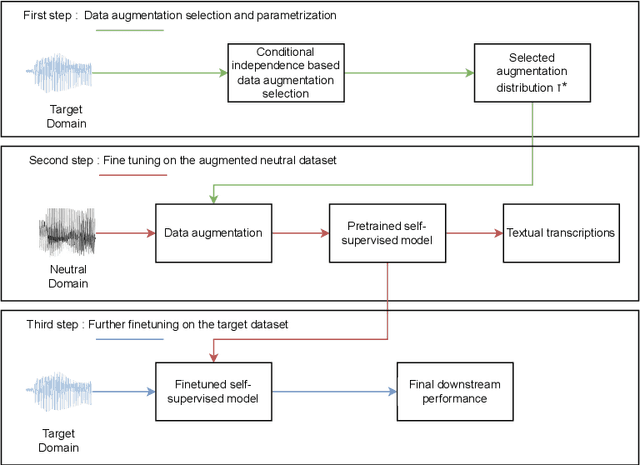


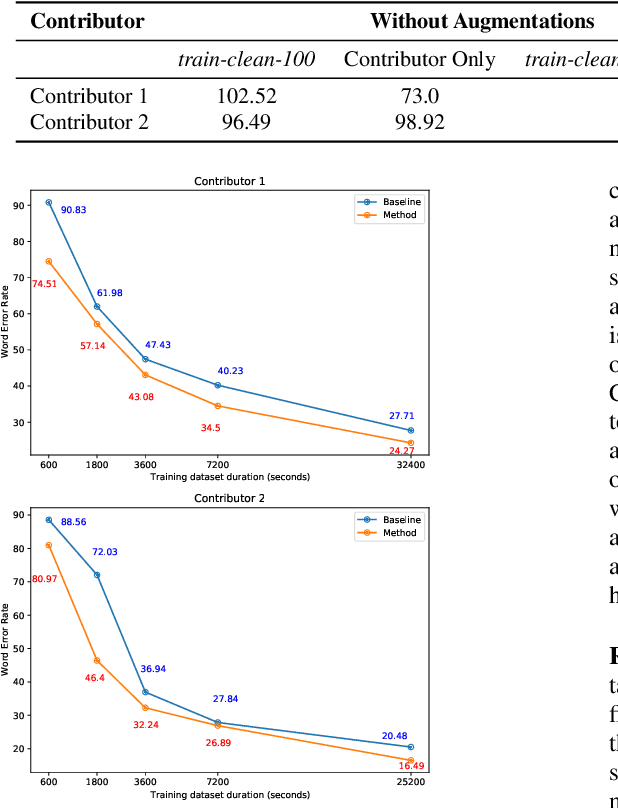
Self-Supervised Learning (SSL) has allowed leveraging large amounts of unlabeled speech data to improve the performance of speech recognition models even with small annotated datasets. Despite this, speech SSL representations may fail while facing an acoustic mismatch between the pretraining and target datasets. To address this issue, we propose a novel supervised domain adaptation method, designed for cases exhibiting such a mismatch in acoustic domains. It consists in applying properly calibrated data augmentations on a large clean dataset, bringing it closer to the target domain, and using it as part of an initial fine-tuning stage. Augmentations are automatically selected through the minimization of a conditional-dependence estimator, based on the target dataset. The approach is validated during an oracle experiment with controlled distortions and on two amateur-collected low-resource domains, reaching better performances compared to the baselines in both cases.
Tagged End-to-End Simultaneous Speech Translation Training using Simultaneous Interpretation Data
Jun 14, 2023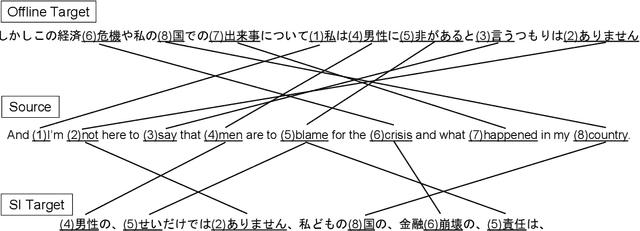


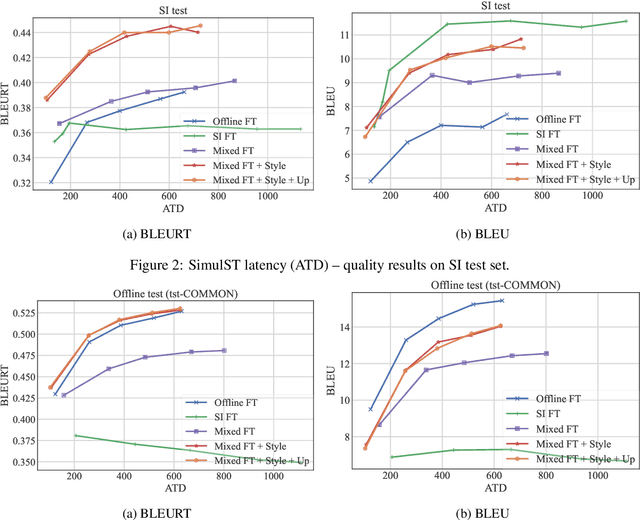
Simultaneous speech translation (SimulST) translates partial speech inputs incrementally. Although the monotonic correspondence between input and output is preferable for smaller latency, it is not the case for distant language pairs such as English and Japanese. A prospective approach to this problem is to mimic simultaneous interpretation (SI) using SI data to train a SimulST model. However, the size of such SI data is limited, so the SI data should be used together with ordinary bilingual data whose translations are given in offline. In this paper, we propose an effective way to train a SimulST model using mixed data of SI and offline. The proposed method trains a single model using the mixed data with style tags that tell the model to generate SI- or offline-style outputs. Experiment results show improvements of BLEURT in different latency ranges, and our analyses revealed the proposed model generates SI-style outputs more than the baseline.
Downstream Task Agnostic Speech Enhancement with Self-Supervised Representation Loss
May 24, 2023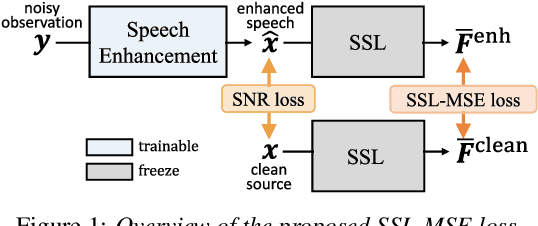
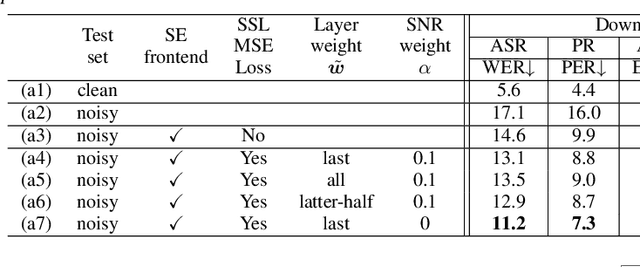
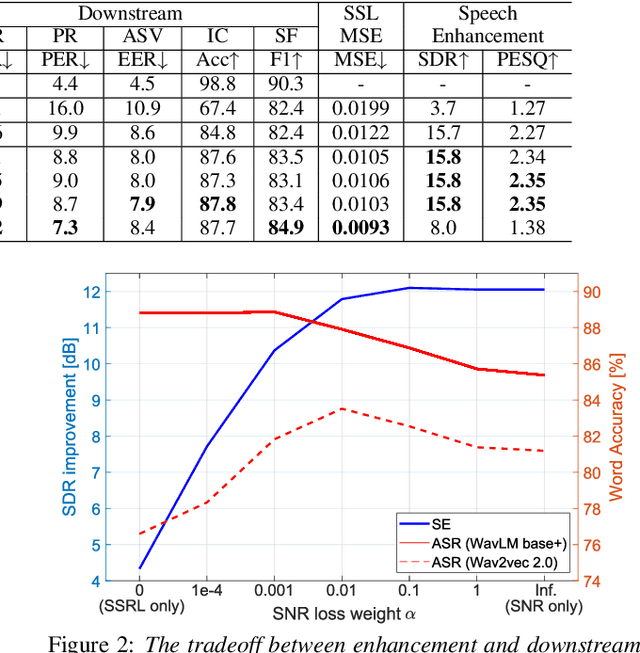
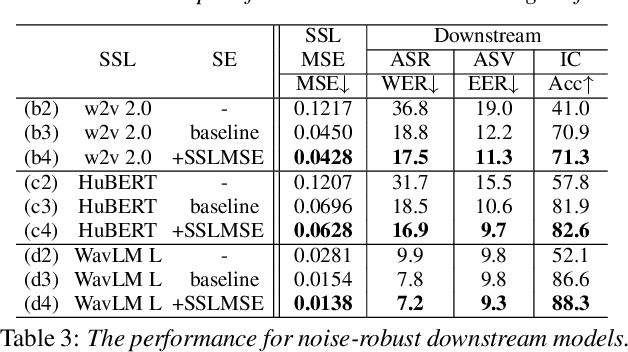
Self-supervised learning (SSL) is the latest breakthrough in speech processing, especially for label-scarce downstream tasks by leveraging massive unlabeled audio data. The noise robustness of the SSL is one of the important challenges to expanding its application. We can use speech enhancement (SE) to tackle this issue. However, the mismatch between the SE model and SSL models potentially limits its effect. In this work, we propose a new SE training criterion that minimizes the distance between clean and enhanced signals in the feature representation of the SSL model to alleviate the mismatch. We expect that the loss in the SSL domain could guide SE training to preserve or enhance various levels of characteristics of the speech signals that may be required for high-level downstream tasks. Experiments show that our proposal improves the performance of an SE and SSL pipeline on five downstream tasks with noisy input while maintaining the SE performance.
AlignSTS: Speech-to-Singing Conversion via Cross-Modal Alignment
May 13, 2023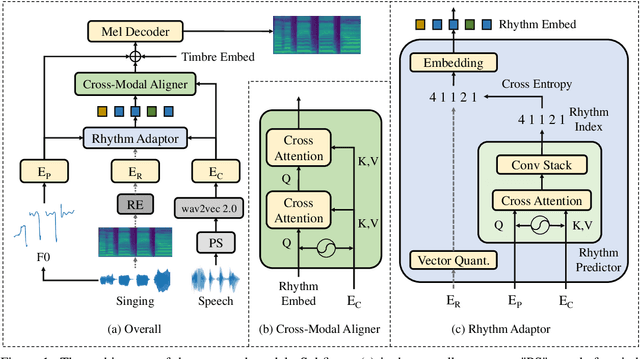
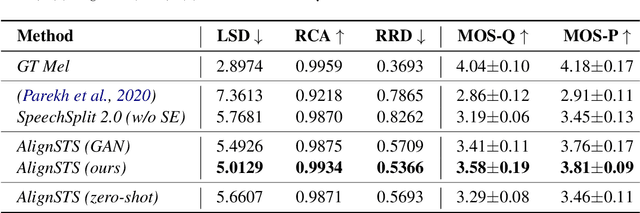
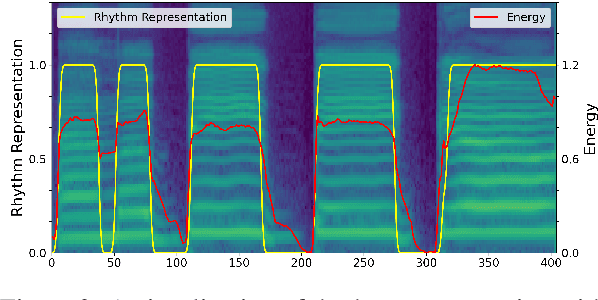
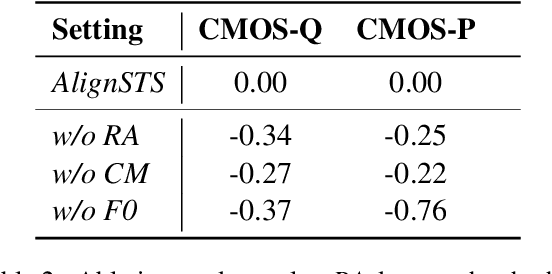
The speech-to-singing (STS) voice conversion task aims to generate singing samples corresponding to speech recordings while facing a major challenge: the alignment between the target (singing) pitch contour and the source (speech) content is difficult to learn in a text-free situation. This paper proposes AlignSTS, an STS model based on explicit cross-modal alignment, which views speech variance such as pitch and content as different modalities. Inspired by the mechanism of how humans will sing the lyrics to the melody, AlignSTS: 1) adopts a novel rhythm adaptor to predict the target rhythm representation to bridge the modality gap between content and pitch, where the rhythm representation is computed in a simple yet effective way and is quantized into a discrete space; and 2) uses the predicted rhythm representation to re-align the content based on cross-attention and conducts a cross-modal fusion for re-synthesize. Extensive experiments show that AlignSTS achieves superior performance in terms of both objective and subjective metrics. Audio samples are available at https://alignsts.github.io.
The ART of Conversation: Measuring Phonetic Convergence and Deliberate Imitation in L2-Speech with a Siamese RNN
Jun 08, 2023

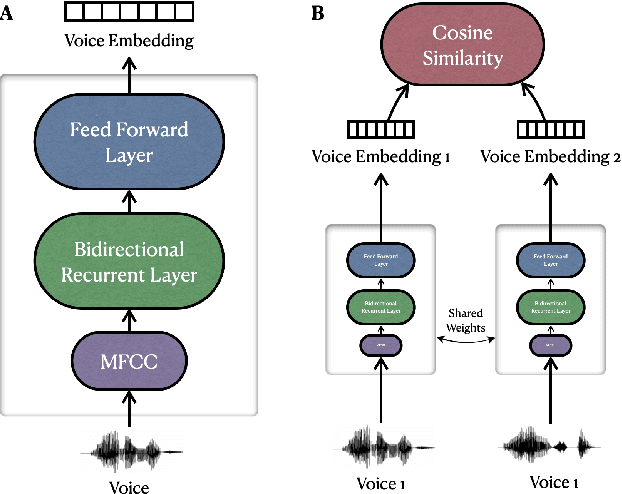
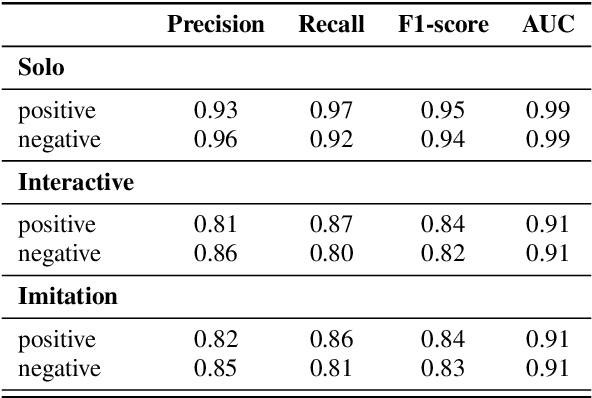
Phonetic convergence describes the automatic and unconscious speech adaptation of two interlocutors in a conversation. This paper proposes a Siamese recurrent neural network (RNN) architecture to measure the convergence of the holistic spectral characteristics of speech sounds in an L2-L2 interaction. We extend an alternating reading task (the ART) dataset by adding 20 native Slovak L2 English speakers. We train and test the Siamese RNN model to measure phonetic convergence of L2 English speech from three different native language groups: Italian (9 dyads), French (10 dyads) and Slovak (10 dyads). Our results indicate that the Siamese RNN model effectively captures the dynamics of phonetic convergence and the speaker's imitation ability. Moreover, this text-independent model is scalable and capable of handling L1-induced speaker variability.