 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet's Put Ourselves in Sally's Shoes: Shoes-of-Others Prefixing Improves Theory of Mind in Large Language Models
Jun 06, 2025Recent studies have shown that Theory of Mind (ToM) in large language models (LLMs) has not reached human-level performance yet. Since fine-tuning LLMs on ToM datasets often degrades their generalization, several inference-time methods have been proposed to enhance ToM in LLMs. However, existing inference-time methods for ToM are specialized for inferring beliefs from contexts involving changes in the world state. In this study, we present a new inference-time method for ToM, Shoes-of-Others (SoO) prefixing, which makes fewer assumptions about contexts and is applicable to broader scenarios. SoO prefixing simply specifies the beginning of LLM outputs with ``Let's put ourselves in A's shoes.'', where A denotes the target character's name. We evaluate SoO prefixing on two benchmarks that assess ToM in conversational and narrative contexts without changes in the world state and find that it consistently improves ToM across five categories of mental states. Our analysis suggests that SoO prefixing elicits faithful thoughts, thereby improving the ToM performance.
ToMATO: Verbalizing the Mental States of Role-Playing LLMs for Benchmarking Theory of Mind
Jan 15, 2025



Existing Theory of Mind (ToM) benchmarks diverge from real-world scenarios in three aspects: 1) they assess a limited range of mental states such as beliefs, 2) false beliefs are not comprehensively explored, and 3) the diverse personality traits of characters are overlooked. To address these challenges, we introduce ToMATO, a new ToM benchmark formulated as multiple-choice QA over conversations. ToMATO is generated via LLM-LLM conversations featuring information asymmetry. By employing a prompting method that requires role-playing LLMs to verbalize their thoughts before each utterance, we capture both first- and second-order mental states across five categories: belief, intention, desire, emotion, and knowledge. These verbalized thoughts serve as answers to questions designed to assess the mental states of characters within conversations. Furthermore, the information asymmetry introduced by hiding thoughts from others induces the generation of false beliefs about various mental states. Assigning distinct personality traits to LLMs further diversifies both utterances and thoughts. ToMATO consists of 5.4k questions, 753 conversations, and 15 personality trait patterns. Our analysis shows that this dataset construction approach frequently generates false beliefs due to the information asymmetry between role-playing LLMs, and effectively reflects diverse personalities. We evaluate nine LLMs on ToMATO and find that even GPT-4o mini lags behind human performance, especially in understanding false beliefs, and lacks robustness to various personality traits.
End-to-End Joint Target and Non-Target Speakers ASR
Jun 04, 2023


This paper proposes a novel automatic speech recognition (ASR) system that can transcribe individual speaker's speech while identifying whether they are target or non-target speakers from multi-talker overlapped speech. Target-speaker ASR systems are a promising way to only transcribe a target speaker's speech by enrolling the target speaker's information. However, in conversational ASR applications, transcribing both the target speaker's speech and non-target speakers' ones is often required to understand interactive information. To naturally consider both target and non-target speakers in a single ASR model, our idea is to extend autoregressive modeling-based multi-talker ASR systems to utilize the enrollment speech of the target speaker. Our proposed ASR is performed by recursively generating both textual tokens and tokens that represent target or non-target speakers. Our experiments demonstrate the effectiveness of our proposed method.
Downstream Task Agnostic Speech Enhancement with Self-Supervised Representation Loss
May 24, 2023
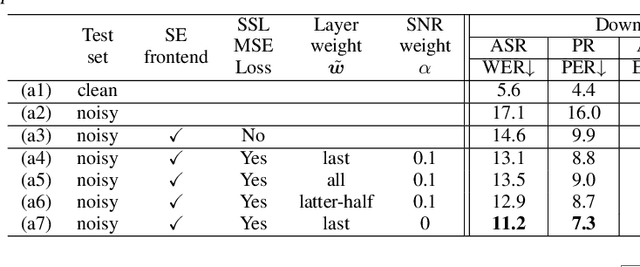


Self-supervised learning (SSL) is the latest breakthrough in speech processing, especially for label-scarce downstream tasks by leveraging massive unlabeled audio data. The noise robustness of the SSL is one of the important challenges to expanding its application. We can use speech enhancement (SE) to tackle this issue. However, the mismatch between the SE model and SSL models potentially limits its effect. In this work, we propose a new SE training criterion that minimizes the distance between clean and enhanced signals in the feature representation of the SSL model to alleviate the mismatch. We expect that the loss in the SSL domain could guide SE training to preserve or enhance various levels of characteristics of the speech signals that may be required for high-level downstream tasks. Experiments show that our proposal improves the performance of an SE and SSL pipeline on five downstream tasks with noisy input while maintaining the SE performance.
MaskCycleGAN-VC: Learning Non-parallel Voice Conversion with Filling in Frames
Feb 25, 2021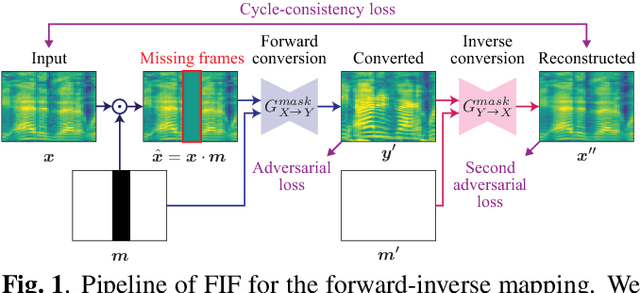
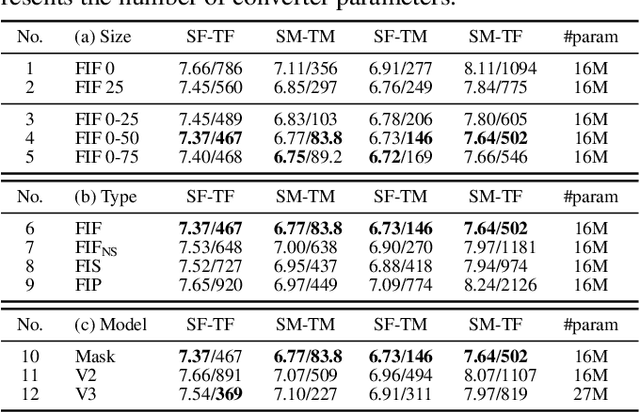
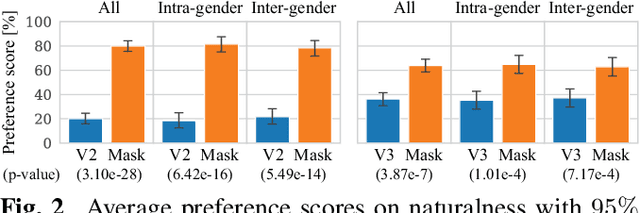
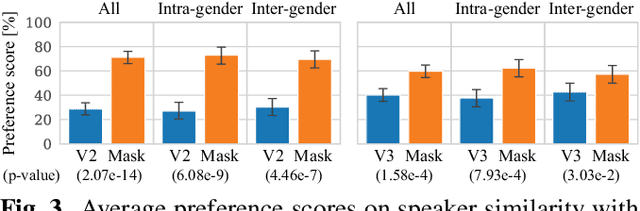
Non-parallel voice conversion (VC) is a technique for training voice converters without a parallel corpus. Cycle-consistent adversarial network-based VCs (CycleGAN-VC and CycleGAN-VC2) are widely accepted as benchmark methods. However, owing to their insufficient ability to grasp time-frequency structures, their application is limited to mel-cepstrum conversion and not mel-spectrogram conversion despite recent advances in mel-spectrogram vocoders. To overcome this, CycleGAN-VC3, an improved variant of CycleGAN-VC2 that incorporates an additional module called time-frequency adaptive normalization (TFAN), has been proposed. However, an increase in the number of learned parameters is imposed. As an alternative, we propose MaskCycleGAN-VC, which is another extension of CycleGAN-VC2 and is trained using a novel auxiliary task called filling in frames (FIF). With FIF, we apply a temporal mask to the input mel-spectrogram and encourage the converter to fill in missing frames based on surrounding frames. This task allows the converter to learn time-frequency structures in a self-supervised manner and eliminates the need for an additional module such as TFAN. A subjective evaluation of the naturalness and speaker similarity showed that MaskCycleGAN-VC outperformed both CycleGAN-VC2 and CycleGAN-VC3 with a model size similar to that of CycleGAN-VC2. Audio samples are available at http://www.kecl.ntt.co.jp/people/kaneko.takuhiro/projects/maskcyclegan-vc/index.html.
Model architectures to extrapolate emotional expressions in DNN-based text-to-speech
Feb 20, 2021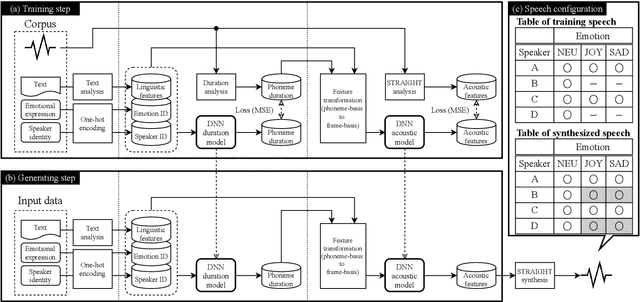
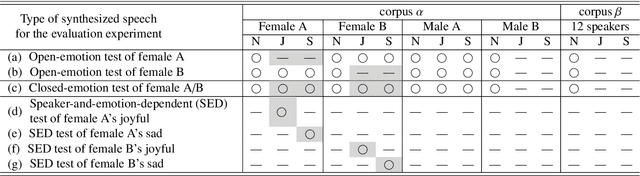
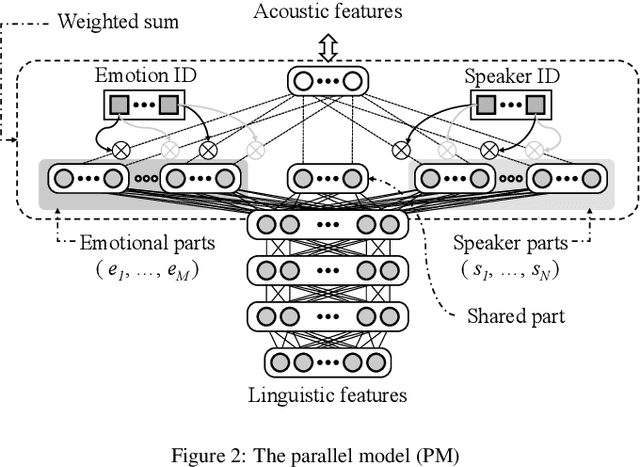

This paper proposes architectures that facilitate the extrapolation of emotional expressions in deep neural network (DNN)-based text-to-speech (TTS). In this study, the meaning of "extrapolate emotional expressions" is to borrow emotional expressions from others, and the collection of emotional speech uttered by target speakers is unnecessary. Although a DNN has potential power to construct DNN-based TTS with emotional expressions and some DNN-based TTS systems have demonstrated satisfactory performances in the expression of the diversity of human speech, it is necessary and troublesome to collect emotional speech uttered by target speakers. To solve this issue, we propose architectures to separately train the speaker feature and the emotional feature and to synthesize speech with any combined quality of speakers and emotions. The architectures are parallel model (PM), serial model (SM), auxiliary input model (AIM), and hybrid models (PM&AIM and SM&AIM). These models are trained through emotional speech uttered by few speakers and neutral speech uttered by many speakers. Objective evaluations demonstrate that the performances in the open-emotion test provide insufficient information. They make a comparison with those in the closed-emotion test, but each speaker has their own manner of expressing emotion. However, subjective evaluation results indicate that the proposed models could convey emotional information to some extent. Notably, the PM can correctly convey sad and joyful emotions at a rate of >60%.
CycleGAN-VC3: Examining and Improving CycleGAN-VCs for Mel-spectrogram Conversion
Oct 22, 2020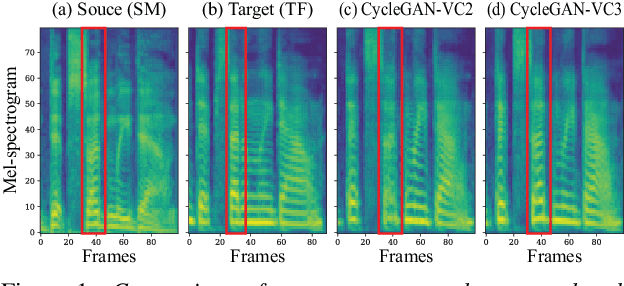
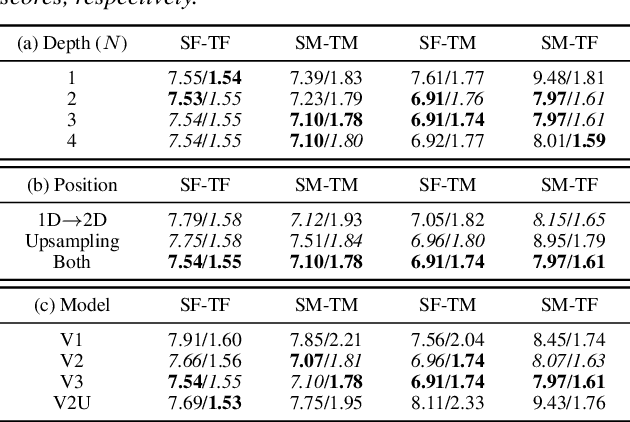
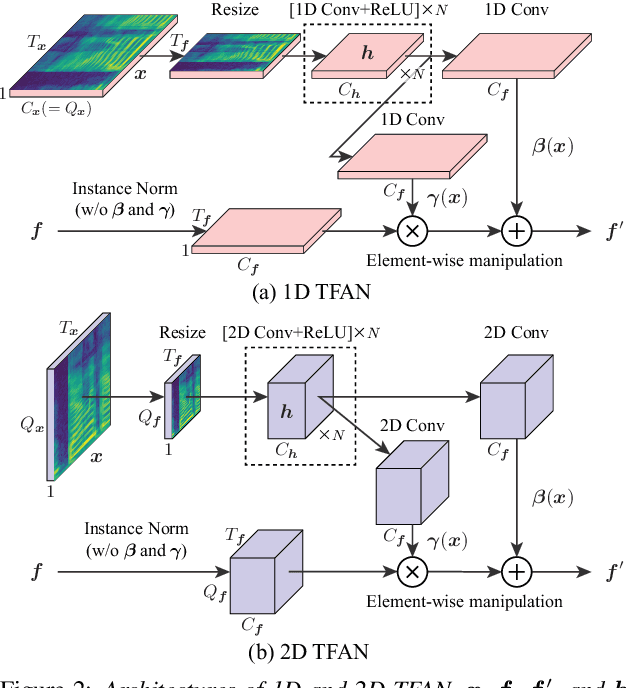
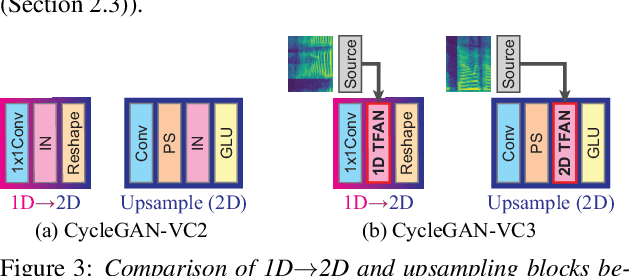
Non-parallel voice conversion (VC) is a technique for learning mappings between source and target speeches without using a parallel corpus. Recently, cycle-consistent adversarial network (CycleGAN)-VC and CycleGAN-VC2 have shown promising results regarding this problem and have been widely used as benchmark methods. However, owing to the ambiguity of the effectiveness of CycleGAN-VC/VC2 for mel-spectrogram conversion, they are typically used for mel-cepstrum conversion even when comparative methods employ mel-spectrogram as a conversion target. To address this, we examined the applicability of CycleGAN-VC/VC2 to mel-spectrogram conversion. Through initial experiments, we discovered that their direct applications compromised the time-frequency structure that should be preserved during conversion. To remedy this, we propose CycleGAN-VC3, an improvement of CycleGAN-VC2 that incorporates time-frequency adaptive normalization (TFAN). Using TFAN, we can adjust the scale and bias of the converted features while reflecting the time-frequency structure of the source mel-spectrogram. We evaluated CycleGAN-VC3 on inter-gender and intra-gender non-parallel VC. A subjective evaluation of naturalness and similarity showed that for every VC pair, CycleGAN-VC3 outperforms or is competitive with the two types of CycleGAN-VC2, one of which was applied to mel-cepstrum and the other to mel-spectrogram. Audio samples are available at http://www.kecl.ntt.co.jp/people/kaneko.takuhiro/projects/cyclegan-vc3/index.html.
Non-Parallel Voice Conversion with Augmented Classifier Star Generative Adversarial Networks
Sep 11, 2020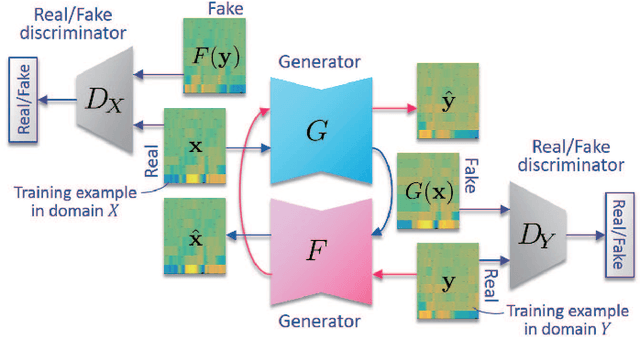
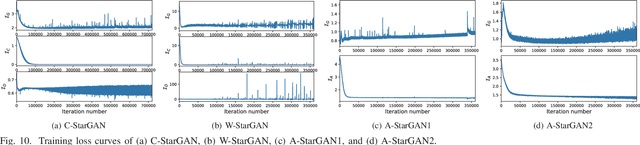
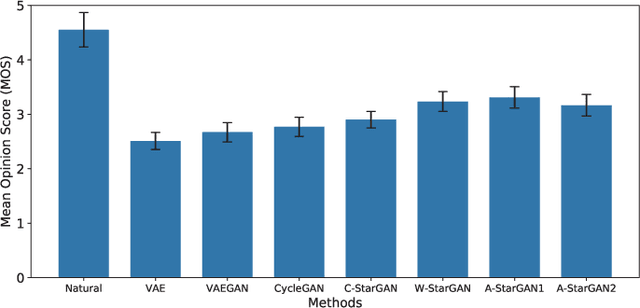
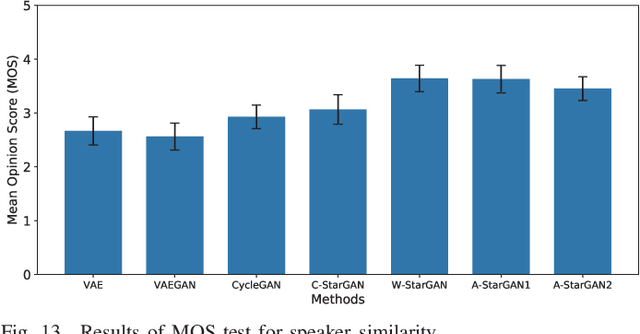
We previously proposed a method that allows for non-parallel voice conversion (VC) by using a variant of generative adversarial networks (GANs) called StarGAN. The main features of our method, called StarGAN-VC, are as follows: First, it requires no parallel utterances, transcriptions, or time alignment procedures for speech generator training. Second, it can simultaneously learn mappings across multiple domains using a single generator network so that it can fully exploit available training data collected from multiple domains to capture latent features that are common to all the domains. Third, it is able to generate converted speech signals quickly enough to allow real-time implementations and requires only several minutes of training examples to generate reasonably realistic-sounding speech. In this paper, we describe three formulations of StarGAN, including a newly introduced novel StarGAN variant called "Augmented classifier StarGAN (A-StarGAN)", and compare them in a non-parallel VC task. We also compare them with several baseline methods.
Many-to-Many Voice Transformer Network
Jun 07, 2020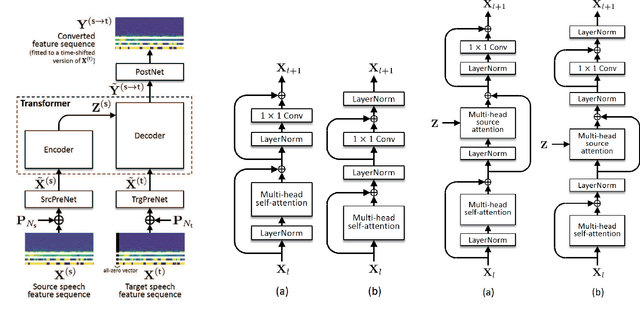
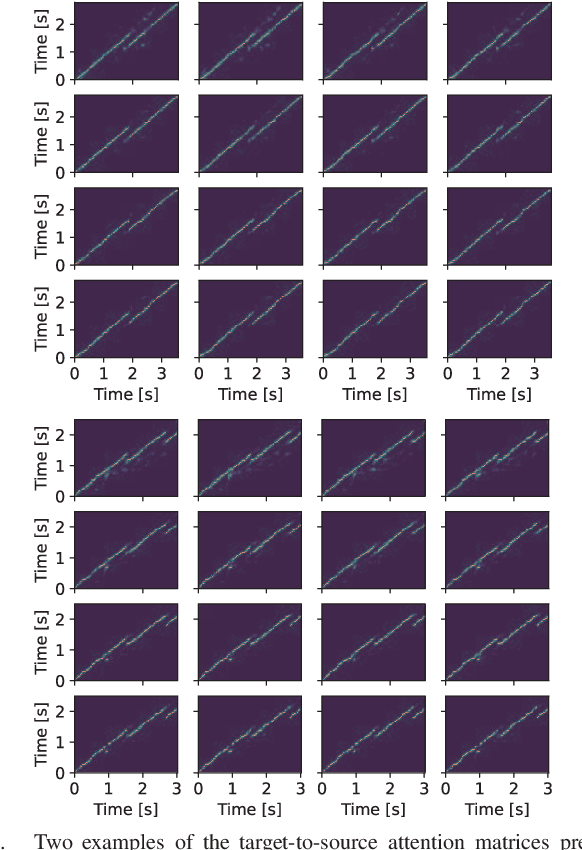
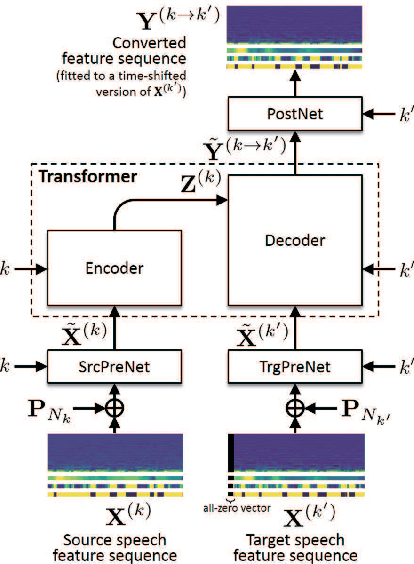
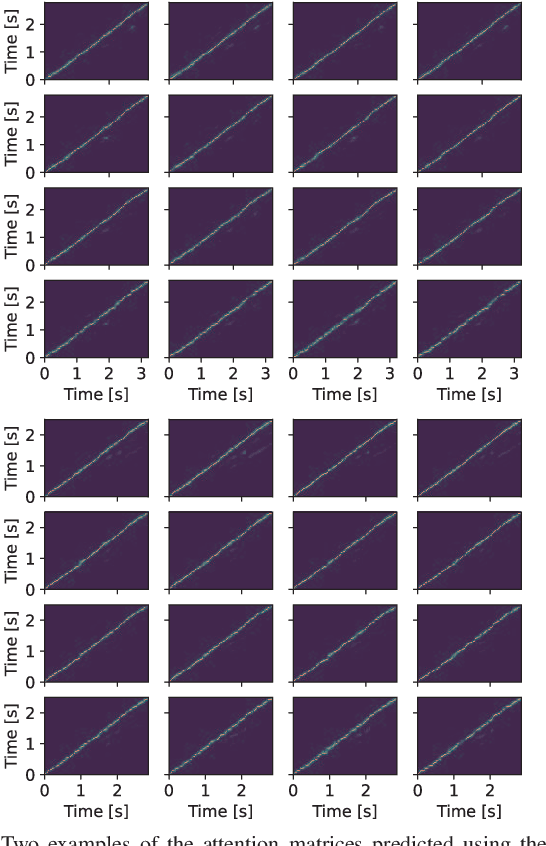
This paper proposes a voice conversion (VC) method based on a sequence-to-sequence (S2S) learning framework, which enables simultaneous conversion of the voice characteristics, pitch contour, and duration of input speech. We previously proposed an S2S-based VC method using a transformer network architecture called the voice transformer network (VTN). The original VTN was designed to learn only a mapping of speech feature sequences from one domain into another. The main idea we propose is an extension of the original VTN that can simultaneously learn mappings among multiple domains. This extension called the many-to-many VTN makes it able to fully use available training data collected from multiple domains by capturing common latent features that can be shared across different domains. It also allows us to introduce a training loss called the identity mapping loss to ensure that the input feature sequence will remain unchanged when it already belongs to the target domain. Using this particular loss for model training has been found to be extremely effective in improving the performance of the model at test time. We conducted speaker identity conversion experiments and found that our model obtained higher sound quality and speaker similarity than baseline methods. We also found that our model, with a slight modification to its architecture, could handle any-to-many conversion tasks reasonably well.
StarGAN-VC2: Rethinking Conditional Methods for StarGAN-Based Voice Conversion
Aug 07, 2019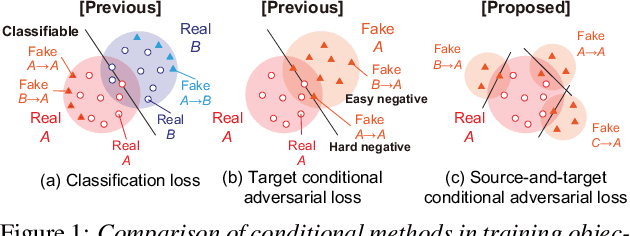
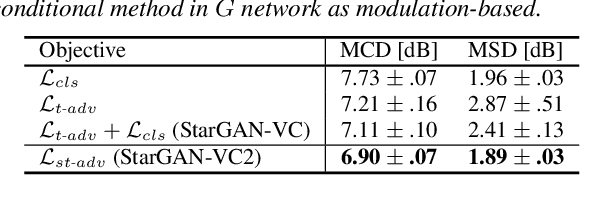
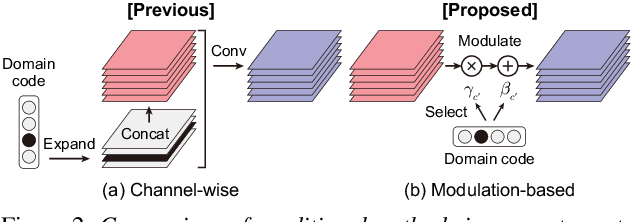
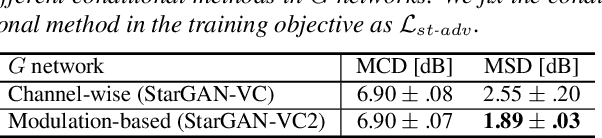
Non-parallel multi-domain voice conversion (VC) is a technique for learning mappings among multiple domains without relying on parallel data. This is important but challenging owing to the requirement of learning multiple mappings and the non-availability of explicit supervision. Recently, StarGAN-VC has garnered attention owing to its ability to solve this problem only using a single generator. However, there is still a gap between real and converted speech. To bridge this gap, we rethink conditional methods of StarGAN-VC, which are key components for achieving non-parallel multi-domain VC in a single model, and propose an improved variant called StarGAN-VC2. Particularly, we rethink conditional methods in two aspects: training objectives and network architectures. For the former, we propose a source-and-target conditional adversarial loss that allows all source domain data to be convertible to the target domain data. For the latter, we introduce a modulation-based conditional method that can transform the modulation of the acoustic feature in a domain-specific manner. We evaluated our methods on non-parallel multi-speaker VC. An objective evaluation demonstrates that our proposed methods improve speech quality in terms of both global and local structure measures. Furthermore, a subjective evaluation shows that StarGAN-VC2 outperforms StarGAN-VC in terms of naturalness and speaker similarity. The converted speech samples are provided at http://www.kecl.ntt.co.jp/people/kaneko.takuhiro/projects/stargan-vc2/index.html.