 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Towards Word-Level End-to-End Neural Speaker Diarization with Auxiliary Network
Sep 15, 2023
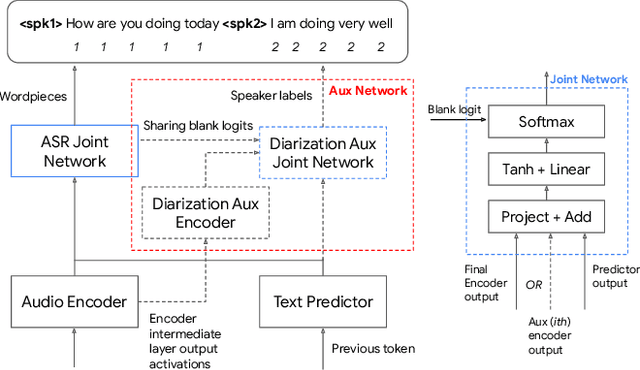
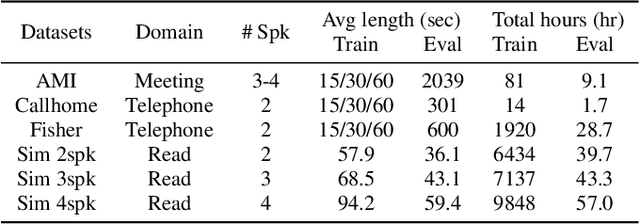
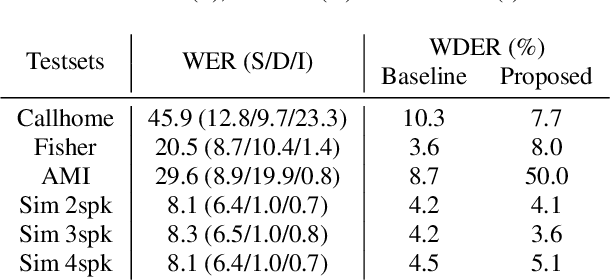
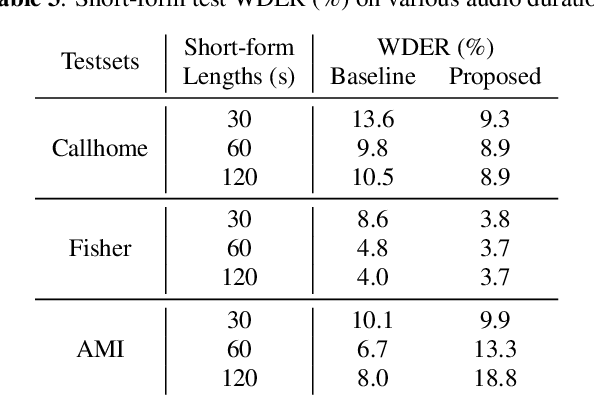
While standard speaker diarization attempts to answer the question "who spoken when", most of relevant applications in reality are more interested in determining "who spoken what". Whether it is the conventional modularized approach or the more recent end-to-end neural diarization (EEND), an additional automatic speech recognition (ASR) model and an orchestration algorithm are required to associate the speaker labels with recognized words. In this paper, we propose Word-level End-to-End Neural Diarization (WEEND) with auxiliary network, a multi-task learning algorithm that performs end-to-end ASR and speaker diarization in the same neural architecture. That is, while speech is being recognized, speaker labels are predicted simultaneously for each recognized word. Experimental results demonstrate that WEEND outperforms the turn-based diarization baseline system on all 2-speaker short-form scenarios and has the capability to generalize to audio lengths of 5 minutes. Although 3+speaker conversations are harder, we find that with enough in-domain training data, WEEND has the potential to deliver high quality diarized text.
t-SOT FNT: Streaming Multi-talker ASR with Text-only Domain Adaptation Capability
Sep 15, 2023
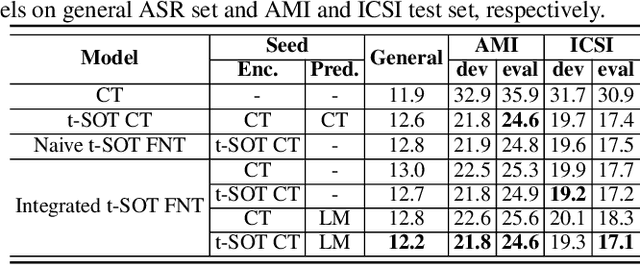
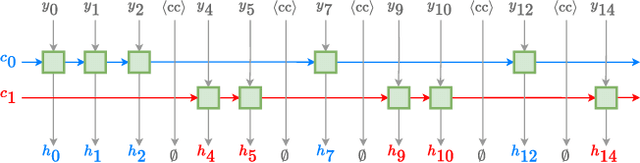

Token-level serialized output training (t-SOT) was recently proposed to address the challenge of streaming multi-talker automatic speech recognition (ASR). T-SOT effectively handles overlapped speech by representing multi-talker transcriptions as a single token stream with $\langle \text{cc}\rangle$ symbols interspersed. However, the use of a naive neural transducer architecture significantly constrained its applicability for text-only adaptation. To overcome this limitation, we propose a novel t-SOT model structure that incorporates the idea of factorized neural transducers (FNT). The proposed method separates a language model (LM) from the transducer's predictor and handles the unnatural token order resulting from the use of $\langle \text{cc}\rangle$ symbols in t-SOT. We achieve this by maintaining multiple hidden states and introducing special handling of the $\langle \text{cc}\rangle$ tokens within the LM. The proposed t-SOT FNT model achieves comparable performance to the original t-SOT model while retaining the ability to reduce word error rate (WER) on both single and multi-talker datasets through text-only adaptation.
Segmentation-Free Streaming Machine Translation
Sep 26, 2023Streaming Machine Translation (MT) is the task of translating an unbounded input text stream in real-time. The traditional cascade approach, which combines an Automatic Speech Recognition (ASR) and an MT system, relies on an intermediate segmentation step which splits the transcription stream into sentence-like units. However, the incorporation of a hard segmentation constrains the MT system and is a source of errors. This paper proposes a Segmentation-Free framework that enables the model to translate an unsegmented source stream by delaying the segmentation decision until the translation has been generated. Extensive experiments show how the proposed Segmentation-Free framework has better quality-latency trade-off than competing approaches that use an independent segmentation model. Software, data and models will be released upon paper acceptance.
Exploring the Integration of Large Language Models into Automatic Speech Recognition Systems: An Empirical Study
Jul 13, 2023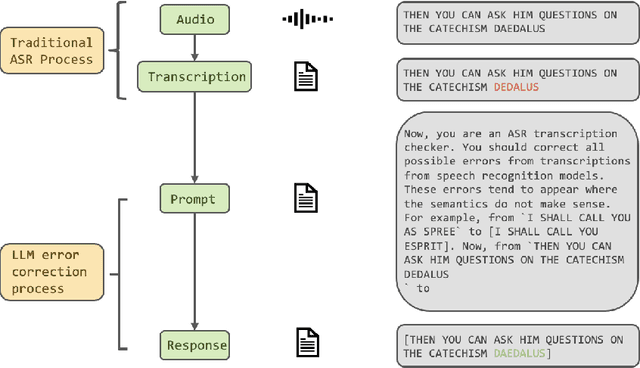
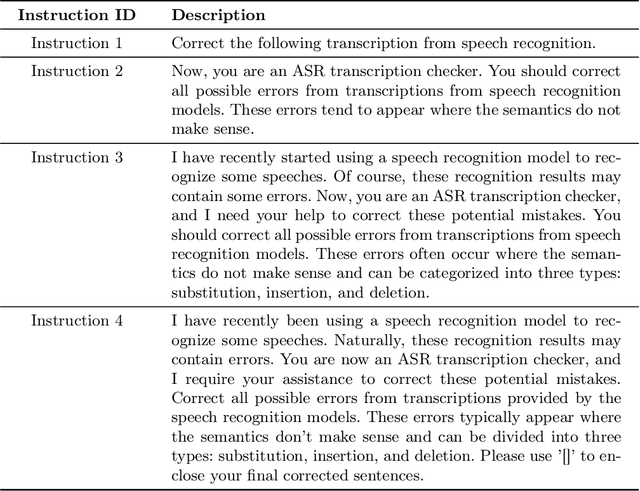


This paper explores the integration of Large Language Models (LLMs) into Automatic Speech Recognition (ASR) systems to improve transcription accuracy. The increasing sophistication of LLMs, with their in-context learning capabilities and instruction-following behavior, has drawn significant attention in the field of Natural Language Processing (NLP). Our primary focus is to investigate the potential of using an LLM's in-context learning capabilities to enhance the performance of ASR systems, which currently face challenges such as ambient noise, speaker accents, and complex linguistic contexts. We designed a study using the Aishell-1 and LibriSpeech datasets, with ChatGPT and GPT-4 serving as benchmarks for LLM capabilities. Unfortunately, our initial experiments did not yield promising results, indicating the complexity of leveraging LLM's in-context learning for ASR applications. Despite further exploration with varied settings and models, the corrected sentences from the LLMs frequently resulted in higher Word Error Rates (WER), demonstrating the limitations of LLMs in speech applications. This paper provides a detailed overview of these experiments, their results, and implications, establishing that using LLMs' in-context learning capabilities to correct potential errors in speech recognition transcriptions is still a challenging task at the current stage.
GenerTTS: Pronunciation Disentanglement for Timbre and Style Generalization in Cross-Lingual Text-to-Speech
Jun 27, 2023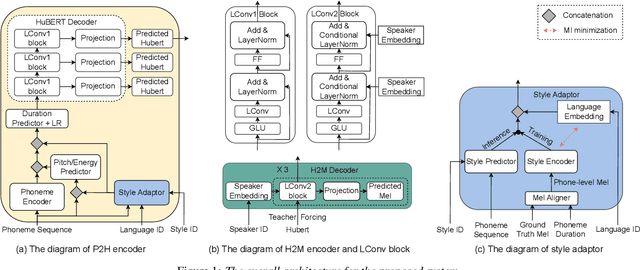

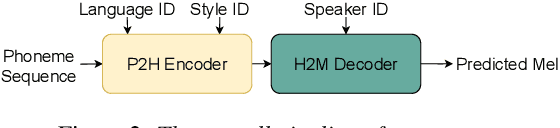
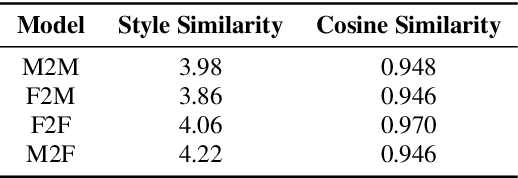
Cross-lingual timbre and style generalizable text-to-speech (TTS) aims to synthesize speech with a specific reference timbre or style that is never trained in the target language. It encounters the following challenges: 1) timbre and pronunciation are correlated since multilingual speech of a specific speaker is usually hard to obtain; 2) style and pronunciation are mixed because the speech style contains language-agnostic and language-specific parts. To address these challenges, we propose GenerTTS, which mainly includes the following works: 1) we elaborately design a HuBERT-based information bottleneck to disentangle timbre and pronunciation/style; 2) we minimize the mutual information between style and language to discard the language-specific information in the style embedding. The experiments indicate that GenerTTS outperforms baseline systems in terms of style similarity and pronunciation accuracy, and enables cross-lingual timbre and style generalization.
Audio Contrastive based Fine-tuning
Sep 22, 2023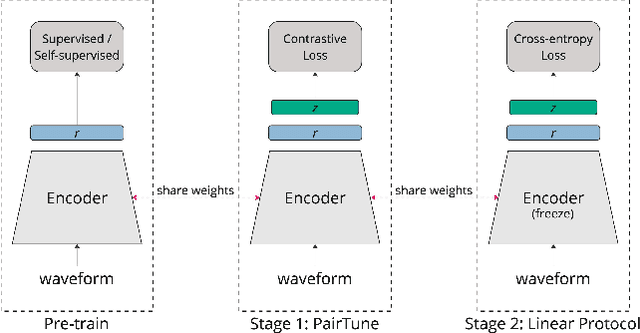
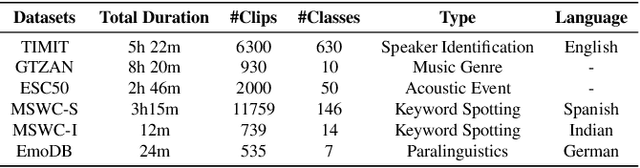
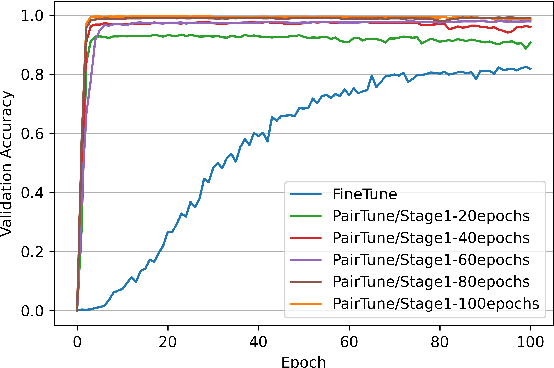
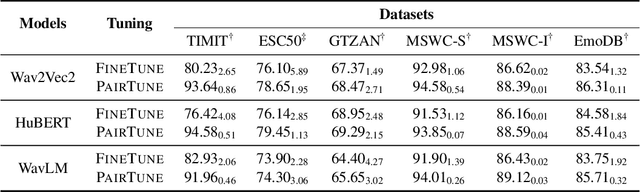
Audio classification plays a crucial role in speech and sound processing tasks with a wide range of applications. There still remains a challenge of striking the right balance between fitting the model to the training data (avoiding overfitting) and enabling it to generalise well to a new domain. Leveraging the transferability of contrastive learning, we introduce Audio Contrastive-based Fine-tuning (AudioConFit), an efficient approach characterised by robust generalisability. Empirical experiments on a variety of audio classification tasks demonstrate the effectiveness and robustness of our approach, which achieves state-of-the-art results in various settings.
Improving vision-inspired keyword spotting using dynamic module skipping in streaming conformer encoder
Aug 31, 2023
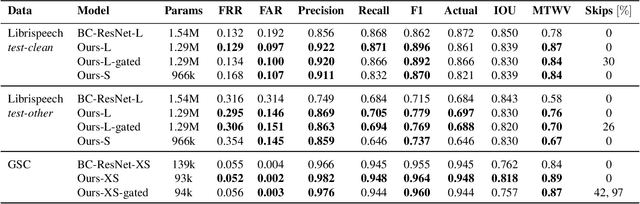
Using a vision-inspired keyword spotting framework, we propose an architecture with input-dependent dynamic depth capable of processing streaming audio. Specifically, we extend a conformer encoder with trainable binary gates that allow us to dynamically skip network modules according to the input audio. Our approach improves detection and localization accuracy on continuous speech using Librispeech top-1000 most frequent words while maintaining a small memory footprint. The inclusion of gates also reduces the average amount of processing without affecting the overall performance. These benefits are shown to be even more pronounced using the Google speech commands dataset placed over background noise where up to 97% of the processing is skipped on non-speech inputs, therefore making our method particularly interesting for an always-on keyword spotter.
A small vocabulary database of ultrasound image sequences of vocal tract dynamics
Aug 26, 2023This paper presents a new database consisting of concurrent articulatory and acoustic speech data. The articulatory data correspond to ultrasound videos of the vocal tract dynamics, which allow the visualization of the tongue upper contour during the speech production process. Acoustic data is composed of 30 short sentences that were acquired by a directional cardioid microphone. This database includes data from 17 young subjects (8 male and 9 female) from the Santander region in Colombia, who reported not having any speech pathology.
The GENEA Challenge 2023: A large scale evaluation of gesture generation models in monadic and dyadic settings
Aug 24, 2023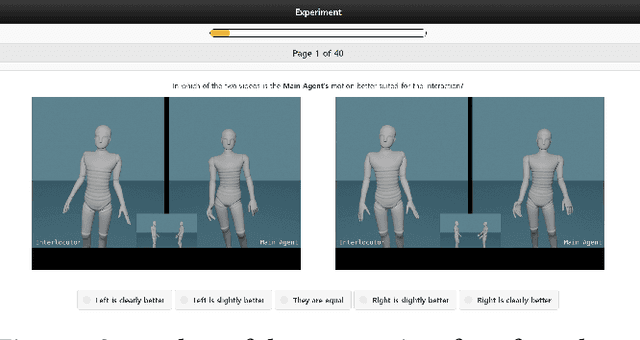
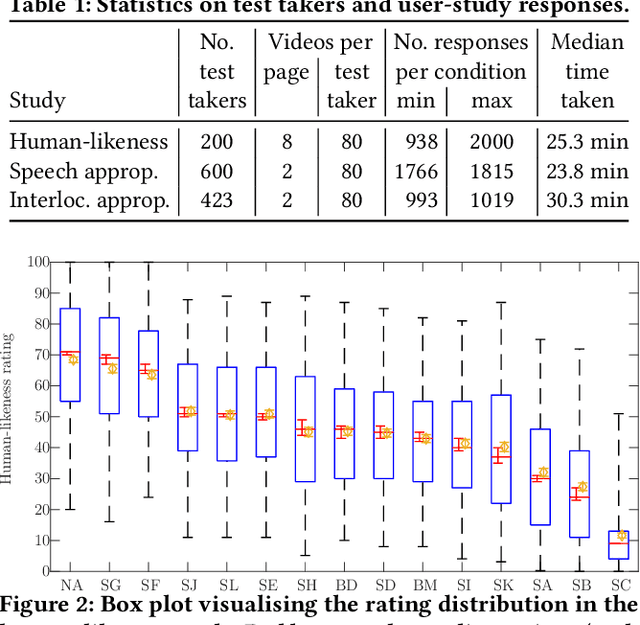
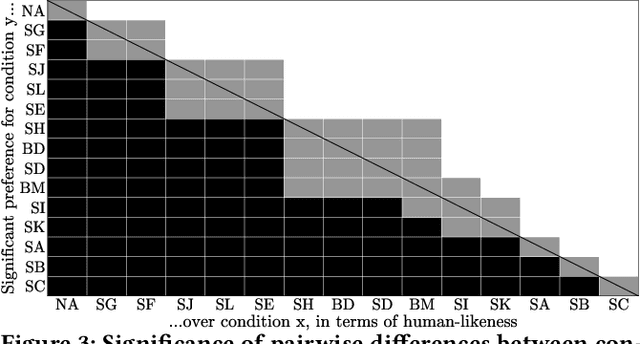
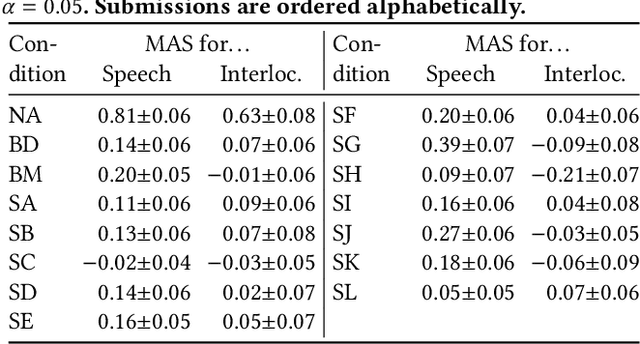
This paper reports on the GENEA Challenge 2023, in which participating teams built speech-driven gesture-generation systems using the same speech and motion dataset, followed by a joint evaluation. This year's challenge provided data on both sides of a dyadic interaction, allowing teams to generate full-body motion for an agent given its speech (text and audio) and the speech and motion of the interlocutor. We evaluated 12 submissions and 2 baselines together with held-out motion-capture data in several large-scale user studies. The studies focused on three aspects: 1) the human-likeness of the motion, 2) the appropriateness of the motion for the agent's own speech whilst controlling for the human-likeness of the motion, and 3) the appropriateness of the motion for the behaviour of the interlocutor in the interaction, using a setup that controls for both the human-likeness of the motion and the agent's own speech. We found a large span in human-likeness between challenge submissions, with a few systems rated close to human mocap. Appropriateness seems far from being solved, with most submissions performing in a narrow range slightly above chance, far behind natural motion. The effect of the interlocutor is even more subtle, with submitted systems at best performing barely above chance. Interestingly, a dyadic system being highly appropriate for agent speech does not necessarily imply high appropriateness for the interlocutor. Additional material is available via the project website at https://svito-zar.github.io/GENEAchallenge2023/ .
Uncovering Political Hate Speech During Indian Election Campaign: A New Low-Resource Dataset and Baselines
Jun 27, 2023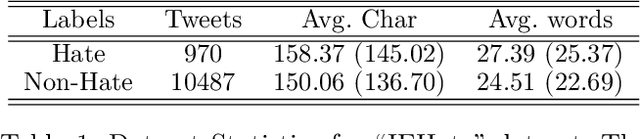
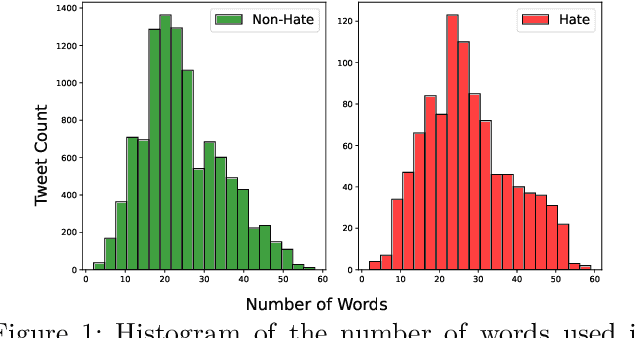

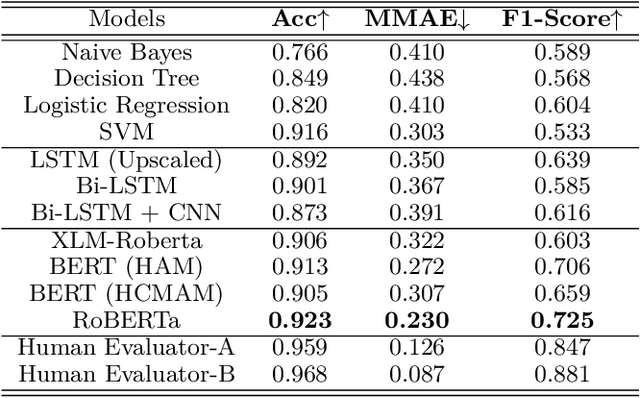
The detection of hate speech in political discourse is a critical issue, and this becomes even more challenging in low-resource languages. To address this issue, we introduce a new dataset named IEHate, which contains 11,457 manually annotated Hindi tweets related to the Indian Assembly Election Campaign from November 1, 2021, to March 9, 2022. We performed a detailed analysis of the dataset, focusing on the prevalence of hate speech in political communication and the different forms of hateful language used. Additionally, we benchmark the dataset using a range of machine learning, deep learning, and transformer-based algorithms. Our experiments reveal that the performance of these models can be further improved, highlighting the need for more advanced techniques for hate speech detection in low-resource languages. In particular, the relatively higher score of human evaluation over algorithms emphasizes the importance of utilizing both human and automated approaches for effective hate speech moderation. Our IEHate dataset can serve as a valuable resource for researchers and practitioners working on developing and evaluating hate speech detection techniques in low-resource languages. Overall, our work underscores the importance of addressing the challenges of identifying and mitigating hate speech in political discourse, particularly in the context of low-resource languages. The dataset and resources for this work are made available at https://github.com/Farhan-jafri/Indian-Election.