 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Teach me with a Whisper: Enhancing Large Language Models for Analyzing Spoken Transcripts using Speech Embeddings
Nov 13, 2023
Speech data has rich acoustic and paralinguistic information with important cues for understanding a speaker's tone, emotion, and intent, yet traditional large language models such as BERT do not incorporate this information. There has been an increased interest in multi-modal language models leveraging audio and/or visual information and text. However, current multi-modal language models require both text and audio/visual data streams during inference/test time. In this work, we propose a methodology for training language models leveraging spoken language audio data but without requiring the audio stream during prediction time. This leads to an improved language model for analyzing spoken transcripts while avoiding an audio processing overhead at test time. We achieve this via an audio-language knowledge distillation framework, where we transfer acoustic and paralinguistic information from a pre-trained speech embedding (OpenAI Whisper) teacher model to help train a student language model on an audio-text dataset. In our experiments, the student model achieves consistent improvement over traditional language models on tasks analyzing spoken transcripts.
Exploring Speech Enhancement for Low-resource Speech Synthesis
Sep 19, 2023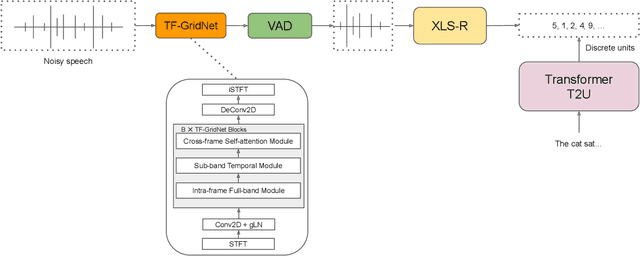

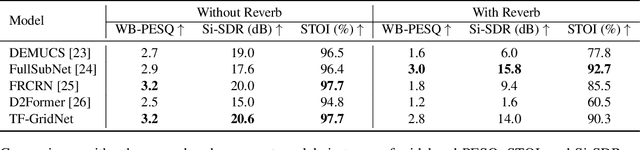
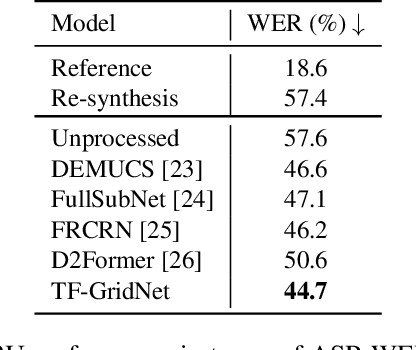
High-quality and intelligible speech is essential to text-to-speech (TTS) model training, however, obtaining high-quality data for low-resource languages is challenging and expensive. Applying speech enhancement on Automatic Speech Recognition (ASR) corpus mitigates the issue by augmenting the training data, while how the nonlinear speech distortion brought by speech enhancement models affects TTS training still needs to be investigated. In this paper, we train a TF-GridNet speech enhancement model and apply it to low-resource datasets that were collected for the ASR task, then train a discrete unit based TTS model on the enhanced speech. We use Arabic datasets as an example and show that the proposed pipeline significantly improves the low-resource TTS system compared with other baseline methods in terms of ASR WER metric. We also run empirical analysis on the correlation between speech enhancement and TTS performances.
Dementia Assessment Using Mandarin Speech with an Attention-based Speech Recognition Encoder
Oct 06, 2023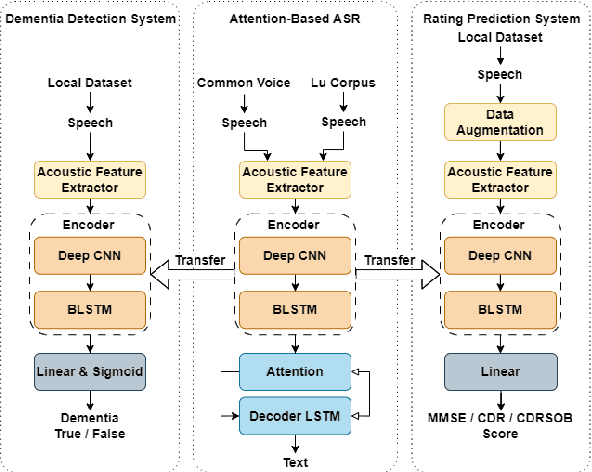
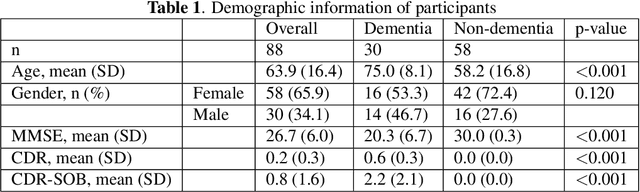
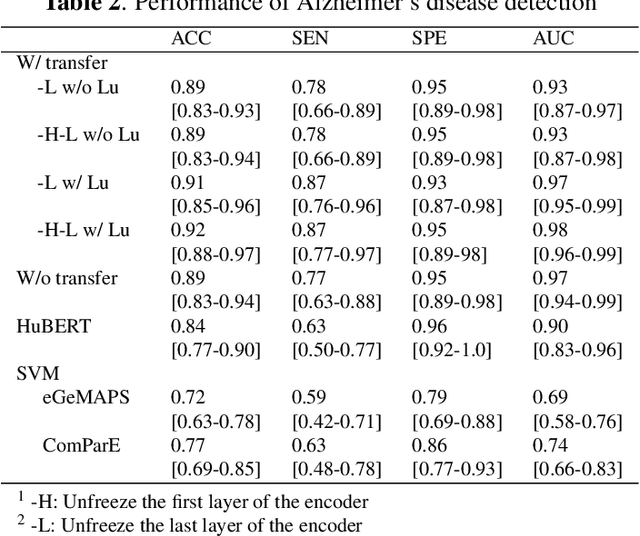
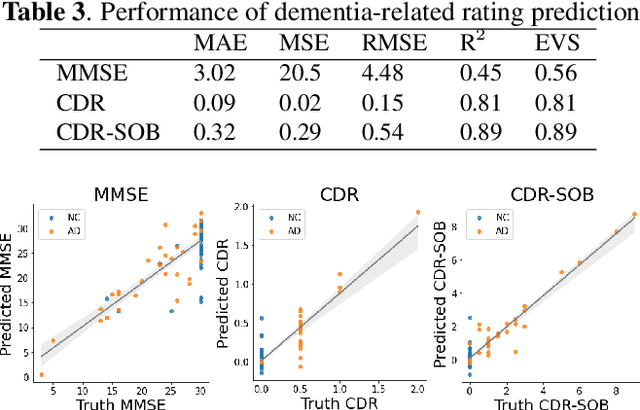
Dementia diagnosis requires a series of different testing methods, which is complex and time-consuming. Early detection of dementia is crucial as it can prevent further deterioration of the condition. This paper utilizes a speech recognition model to construct a dementia assessment system tailored for Mandarin speakers during the picture description task. By training an attention-based speech recognition model on voice data closely resembling real-world scenarios, we have significantly enhanced the model's recognition capabilities. Subsequently, we extracted the encoder from the speech recognition model and added a linear layer for dementia assessment. We collected Mandarin speech data from 99 subjects and acquired their clinical assessments from a local hospital. We achieved an accuracy of 92.04% in Alzheimer's disease detection and a mean absolute error of 9% in clinical dementia rating score prediction.
THOS: A Benchmark Dataset for Targeted Hate and Offensive Speech
Nov 11, 2023Detecting harmful content on social media, such as Twitter, is made difficult by the fact that the seemingly simple yes/no classification conceals a significant amount of complexity. Unfortunately, while several datasets have been collected for training classifiers in hate and offensive speech, there is a scarcity of datasets labeled with a finer granularity of target classes and specific targets. In this paper, we introduce THOS, a dataset of 8.3k tweets manually labeled with fine-grained annotations about the target of the message. We demonstrate that this dataset makes it feasible to train classifiers, based on Large Language Models, to perform classification at this level of granularity.
Towards Streaming Speech-to-Avatar Synthesis
Oct 25, 2023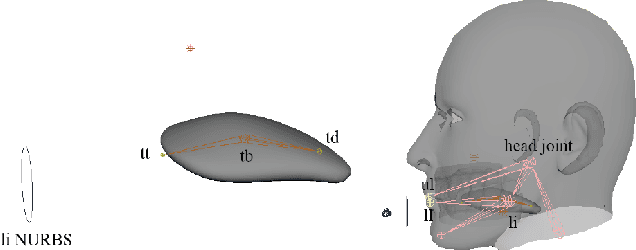
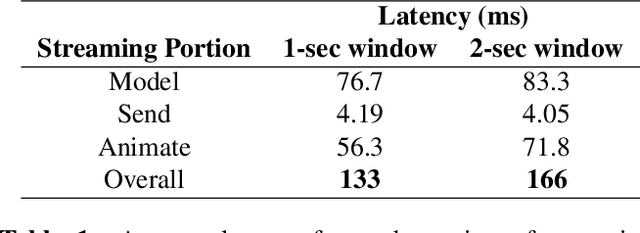
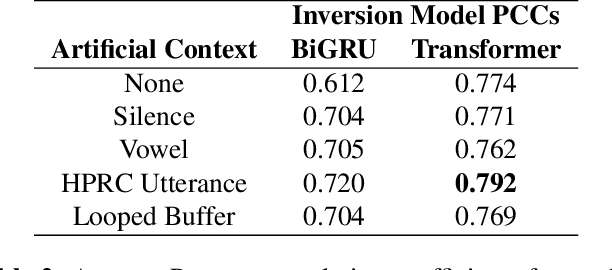

Streaming speech-to-avatar synthesis creates real-time animations for a virtual character from audio data. Accurate avatar representations of speech are important for the visualization of sound in linguistics, phonetics, and phonology, visual feedback to assist second language acquisition, and virtual embodiment for paralyzed patients. Previous works have highlighted the capability of deep articulatory inversion to perform high-quality avatar animation using electromagnetic articulography (EMA) features. However, these models focus on offline avatar synthesis with recordings rather than real-time audio, which is necessary for live avatar visualization or embodiment. To address this issue, we propose a method using articulatory inversion for streaming high quality facial and inner-mouth avatar animation from real-time audio. Our approach achieves 130ms average streaming latency for every 0.1 seconds of audio with a 0.792 correlation with ground truth articulations. Finally, we show generated mouth and tongue animations to demonstrate the efficacy of our methodology.
Multi-Speaker Expressive Speech Synthesis via Semi-supervised Contrastive Learning
Oct 26, 2023This paper aims to build an expressive TTS system for multi-speakers, synthesizing a target speaker's speech with multiple styles and emotions. To this end, we propose a novel contrastive learning-based TTS approach to transfer style and emotion across speakers. Specifically, we construct positive-negative sample pairs at both utterance and category (such as emotion-happy or style-poet or speaker A) levels and leverage contrastive learning to better extract disentangled style, emotion, and speaker representations from speech. Furthermore, we introduce a semi-supervised training strategy to the proposed approach to effectively leverage multi-domain data, including style-labeled data, emotion-labeled data, and unlabeled data. We integrate the learned representations into an improved VITS model, enabling it to synthesize expressive speech with diverse styles and emotions for a target speaker. Experiments on multi-domain data demonstrate the good design of our model.
Towards Probing Contact Center Large Language Models
Dec 26, 2023Fine-tuning large language models (LLMs) with domain-specific instructions has emerged as an effective method to enhance their domain-specific understanding. Yet, there is limited work that examines the core characteristics acquired during this process. In this study, we benchmark the fundamental characteristics learned by contact-center (CC) specific instruction fine-tuned LLMs with out-of-the-box (OOB) LLMs via probing tasks encompassing conversational, channel, and automatic speech recognition (ASR) properties. We explore different LLM architectures (Flan-T5 and Llama), sizes (3B, 7B, 11B, 13B), and fine-tuning paradigms (full fine-tuning vs PEFT). Our findings reveal remarkable effectiveness of CC-LLMs on the in-domain downstream tasks, with improvement in response acceptability by over 48% compared to OOB-LLMs. Additionally, we compare the performance of OOB-LLMs and CC-LLMs on the widely used SentEval dataset, and assess their capabilities in terms of surface, syntactic, and semantic information through probing tasks. Intriguingly, we note a relatively consistent performance of probing classifiers on the set of probing tasks. Our observations indicate that CC-LLMs, while outperforming their out-of-the-box counterparts, exhibit a tendency to rely less on encoding surface, syntactic, and semantic properties, highlighting the intricate interplay between domain-specific adaptation and probing task performance opening up opportunities to explore behavior of fine-tuned language models in specialized contexts.
Investigating Zero-Shot Generalizability on Mandarin-English Code-Switched ASR and Speech-to-text Translation of Recent Foundation Models with Self-Supervision and Weak Supervision
Dec 30, 2023This work evaluated several cutting-edge large-scale foundation models based on self-supervision or weak supervision, including SeamlessM4T, SeamlessM4T v2, and Whisper-large-v3, on three code-switched corpora. We found that self-supervised models can achieve performances close to the supervised model, indicating the effectiveness of multilingual self-supervised pre-training. We also observed that these models still have room for improvement as they kept making similar mistakes and had unsatisfactory performances on modeling intra-sentential code-switching. In addition, the validity of several variants of Whisper was explored, and we concluded that they remained effective in a code-switching scenario, and similar techniques for self-supervised models are worth studying to boost the performance of code-switched tasks.
Realistic Speech-to-Face Generation with Speech-Conditioned Latent Diffusion Model with Face Prior
Oct 05, 2023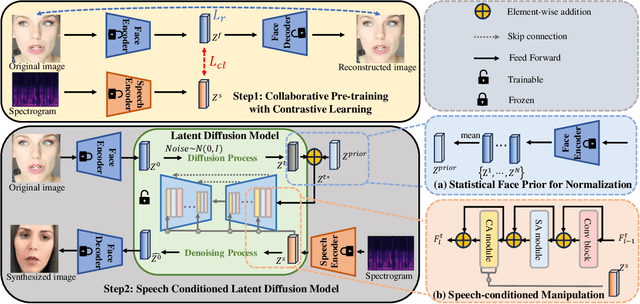
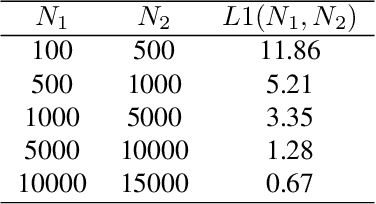

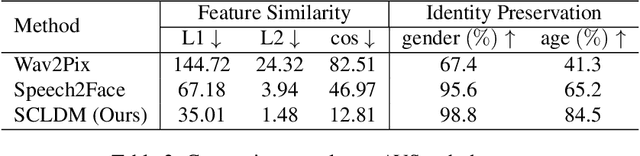
Speech-to-face generation is an intriguing area of research that focuses on generating realistic facial images based on a speaker's audio speech. However, state-of-the-art methods employing GAN-based architectures lack stability and cannot generate realistic face images. To fill this gap, we propose a novel speech-to-face generation framework, which leverages a Speech-Conditioned Latent Diffusion Model, called SCLDM. To the best of our knowledge, this is the first work to harness the exceptional modeling capabilities of diffusion models for speech-to-face generation. Preserving the shared identity information between speech and face is crucial in generating realistic results. Therefore, we employ contrastive pre-training for both the speech encoder and the face encoder. This pre-training strategy facilitates effective alignment between the attributes of speech, such as age and gender, and the corresponding facial characteristics in the face images. Furthermore, we tackle the challenge posed by excessive diversity in the synthesis process caused by the diffusion model. To overcome this challenge, we introduce the concept of residuals by integrating a statistical face prior to the diffusion process. This addition helps to eliminate the shared component across the faces and enhances the subtle variations captured by the speech condition. Extensive quantitative, qualitative, and user study experiments demonstrate that our method can produce more realistic face images while preserving the identity of the speaker better than state-of-the-art methods. Highlighting the notable enhancements, our method demonstrates significant gains in all metrics on the AVSpeech dataset and Voxceleb dataset, particularly noteworthy are the improvements of 32.17 and 32.72 on the cosine distance metric for the two datasets, respectively.
DiaPer: End-to-End Neural Diarization with Perceiver-Based Attractors
Dec 22, 2023Until recently, the field of speaker diarization was dominated by cascaded systems. Due to their limitations, mainly regarding overlapped speech and cumbersome pipelines, end-to-end models have gained great popularity lately. One of the most successful models is end-to-end neural diarization with encoder-decoder based attractors (EEND-EDA). In this work, we replace the EDA module with a Perceiver-based one and show its advantages over EEND-EDA; namely obtaining better performance on the largely studied Callhome dataset, finding the quantity of speakers in a conversation more accurately, and running inference on almost half of the time on long recordings. Furthermore, when exhaustively compared with other methods, our model, DiaPer, reaches remarkable performance with a very lightweight design. Besides, we perform comparisons with other works and a cascaded baseline across more than ten public wide-band datasets. Together with this publication, we release the code of DiaPer as well as models trained on public and free data.