 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Spatio-Temporal Representation Learning Enhanced Source Cell-phone Recognition from Speech Recordings
Aug 25, 2022

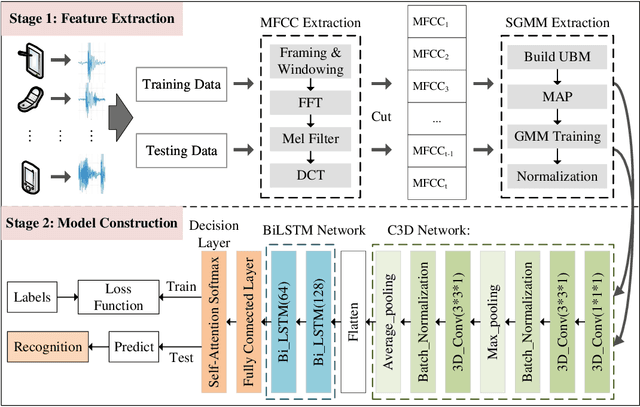
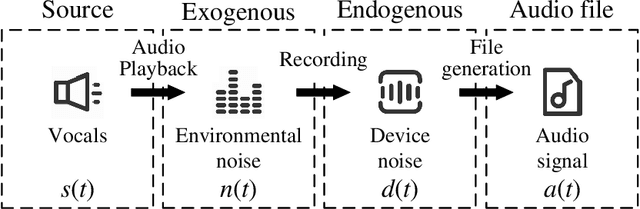

The existing source cell-phone recognition method lacks the long-term feature characterization of the source device, resulting in inaccurate representation of the source cell-phone related features which leads to insufficient recognition accuracy. In this paper, we propose a source cell-phone recognition method based on spatio-temporal representation learning, which includes two main parts: extraction of sequential Gaussian mean matrix features and construction of a recognition model based on spatio-temporal representation learning. In the feature extraction part, based on the analysis of time-series representation of recording source signals, we extract sequential Gaussian mean matrix with long-term and short-term representation ability by using the sensitivity of Gaussian mixture model to data distribution. In the model construction part, we design a structured spatio-temporal representation learning network C3D-BiLSTM to fully characterize the spatio-temporal information, combine 3D convolutional network and bidirectional long short-term memory network for short-term spectral information and long-time fluctuation information representation learning, and achieve accurate recognition of cell-phones by fusing spatio-temporal feature information of recording source signals. The method achieves an average accuracy of 99.03% for the closed-set recognition of 45 cell-phones under the CCNU\_Mobile dataset, and 98.18% in small sample size experiments, with recognition performance better than the existing state-of-the-art methods. The experimental results show that the method exhibits excellent recognition performance in multi-class cell-phones recognition.
Leveraging Acoustic and Linguistic Embeddings from Pretrained speech and language Models for Intent Classification
Feb 15, 2021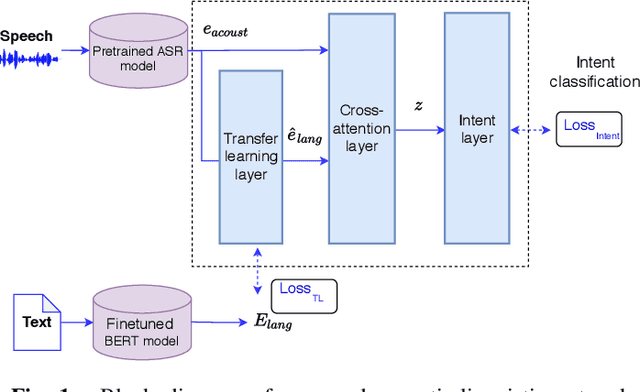
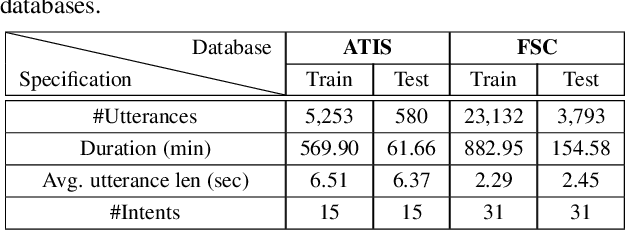
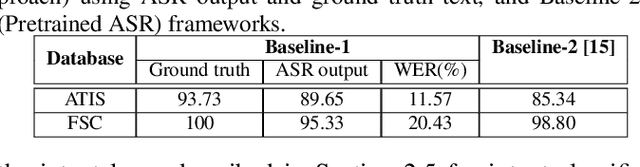
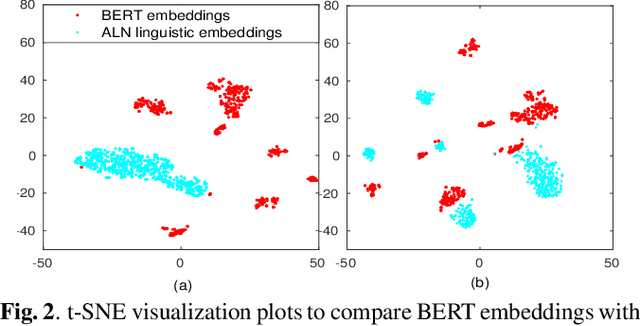
Intent classification is a task in spoken language understanding. An intent classification system is usually implemented as a pipeline process, with a speech recognition module followed by text processing that classifies the intents. There are also studies of end-to-end system that takes acoustic features as input and classifies the intents directly. Such systems don't take advantage of relevant linguistic information, and suffer from limited training data. In this work, we propose a novel intent classification framework that employs acoustic features extracted from a pretrained speech recognition system and linguistic features learned from a pretrained language model. We use knowledge distillation technique to map the acoustic embeddings towards linguistic embeddings. We perform fusion of both acoustic and linguistic embeddings through cross-attention approach to classify intents. With the proposed method, we achieve 90.86% and 99.07% accuracy on ATIS and Fluent speech corpus, respectively.
Scenario Aware Speech Recognition: Advancements for Apollo Fearless Steps & CHiME-4 Corpora
Sep 23, 2021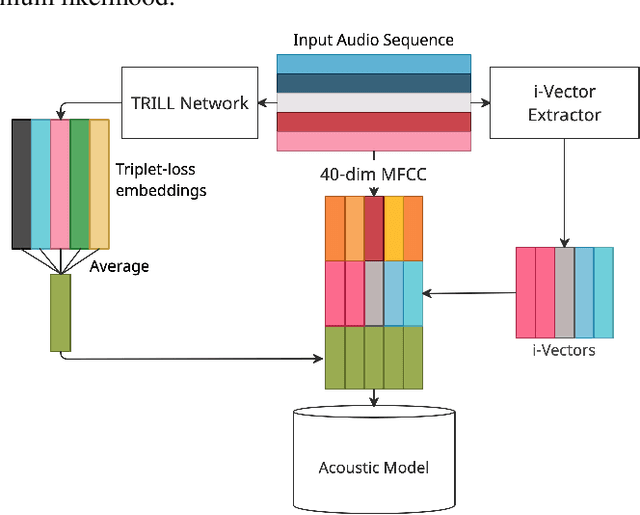
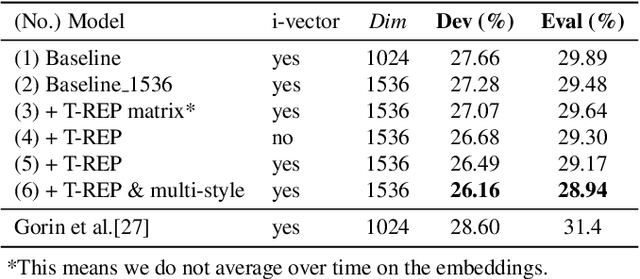
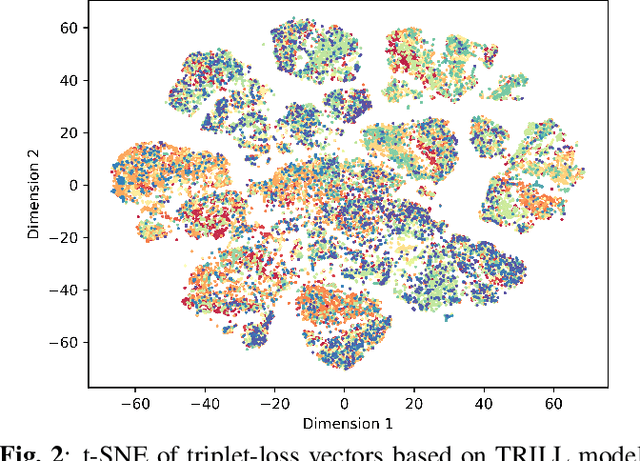

In this study, we propose to investigate triplet loss for the purpose of an alternative feature representation for ASR. We consider a general non-semantic speech representation, which is trained with a self-supervised criteria based on triplet loss called TRILL, for acoustic modeling to represent the acoustic characteristics of each audio. This strategy is then applied to the CHiME-4 corpus and CRSS-UTDallas Fearless Steps Corpus, with emphasis on the 100-hour challenge corpus which consists of 5 selected NASA Apollo-11 channels. An analysis of the extracted embeddings provides the foundation needed to characterize training utterances into distinct groups based on acoustic distinguishing properties. Moreover, we also demonstrate that triplet-loss based embedding performs better than i-Vector in acoustic modeling, confirming that the triplet loss is more effective than a speaker feature. With additional techniques such as pronunciation and silence probability modeling, plus multi-style training, we achieve a +5.42% and +3.18% relative WER improvement for the development and evaluation sets of the Fearless Steps Corpus. To explore generalization, we further test the same technique on the 1 channel track of CHiME-4 and observe a +11.90% relative WER improvement for real test data.
Learning Transferable Features for Speech Emotion Recognition
Dec 23, 2019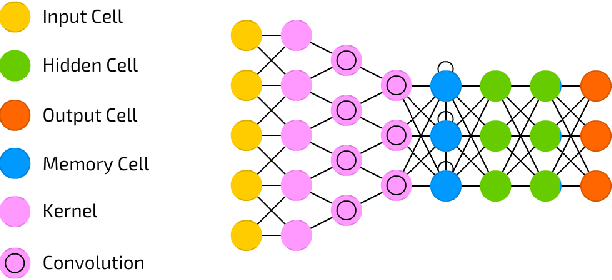
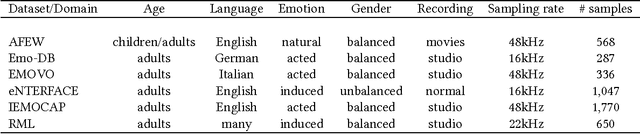
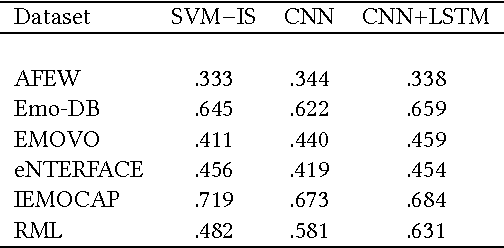

Emotion recognition from speech is one of the key steps towards emotional intelligence in advanced human-machine interaction. Identifying emotions in human speech requires learning features that are robust and discriminative across diverse domains that differ in terms of language, spontaneity of speech, recording conditions, and types of emotions. This corresponds to a learning scenario in which the joint distributions of features and labels may change substantially across domains. In this paper, we propose a deep architecture that jointly exploits a convolutional network for extracting domain-shared features and a long short-term memory network for classifying emotions using domain-specific features. We use transferable features to enable model adaptation from multiple source domains, given the sparseness of speech emotion data and the fact that target domains are short of labeled data. A comprehensive cross-corpora experiment with diverse speech emotion domains reveals that transferable features provide gains ranging from 4.3% to 18.4% in speech emotion recognition. We evaluate several domain adaptation approaches, and we perform an ablation study to understand which source domains add the most to the overall recognition effectiveness for a given target domain.
* ACM-MM'17, October 23-27, 2017
The HW-TSC's Offline Speech Translation Systems for IWSLT 2021 Evaluation
Aug 09, 2021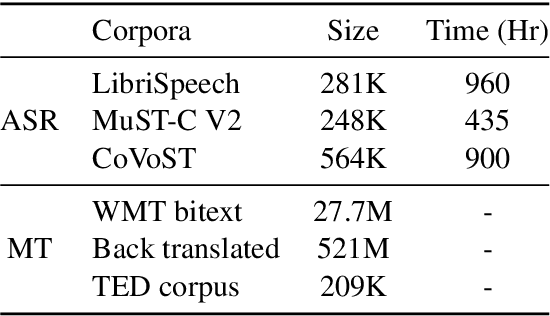
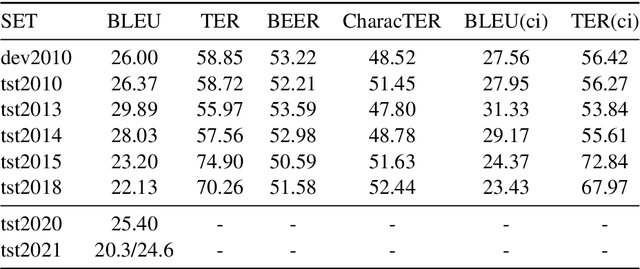
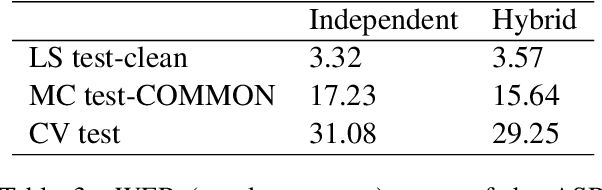
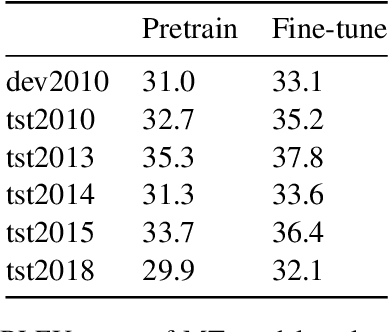
This paper describes our work in participation of the IWSLT-2021 offline speech translation task. Our system was built in a cascade form, including a speaker diarization module, an Automatic Speech Recognition (ASR) module and a Machine Translation (MT) module. We directly use the LIUM SpkDiarization tool as the diarization module. The ASR module is trained with three ASR datasets from different sources, by multi-source training, using a modified Transformer encoder. The MT module is pretrained on the large-scale WMT news translation dataset and fine-tuned on the TED corpus. Our method achieves 24.6 BLEU score on the 2021 test set.
Improved Language Identification Through Cross-Lingual Self-Supervised Learning
Aug 04, 2021
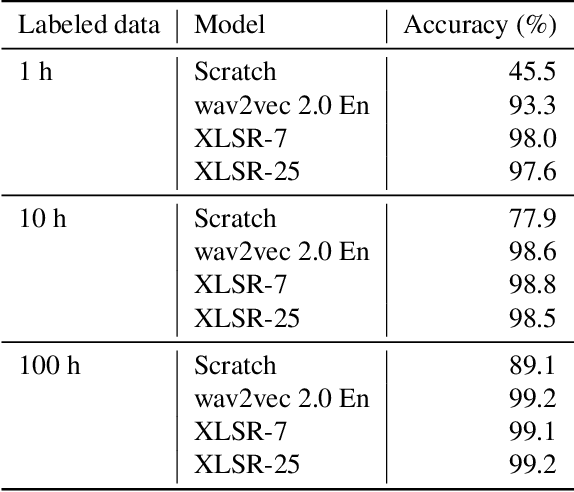
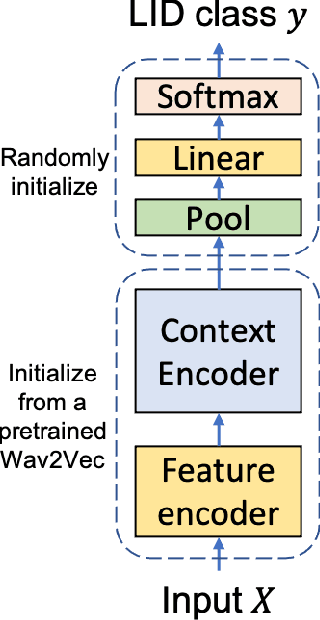
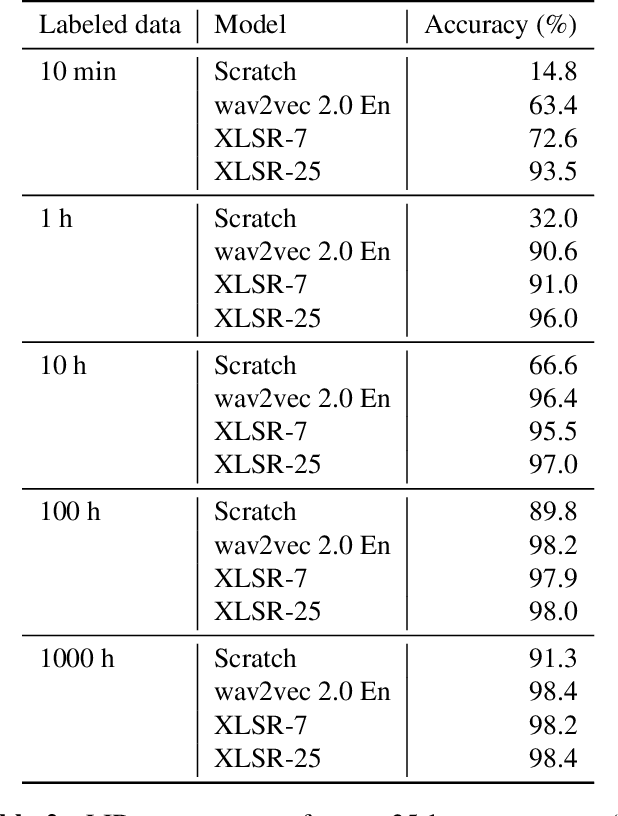
Language identification greatly impacts the success of downstream tasks such as automatic speech recognition. Recently, self-supervised speech representations learned by wav2vec 2.0 have been shown to be very effective for a range of speech tasks. We extend previous self-supervised work on language identification by experimenting with pre-trained models which were learned on real-world unconstrained speech in multiple languages and not just on English. We show that models pre-trained on many languages perform better and enable language identification systems that require very little labeled data to perform well. Results on a 25 languages setup show that with only 10 minutes of labeled data per language, a cross-lingually pre-trained model can achieve over 93% accuracy.
Implementation Of Back-Propagation Neural Network For Isolated Bangla Speech Recognition
Aug 17, 2013
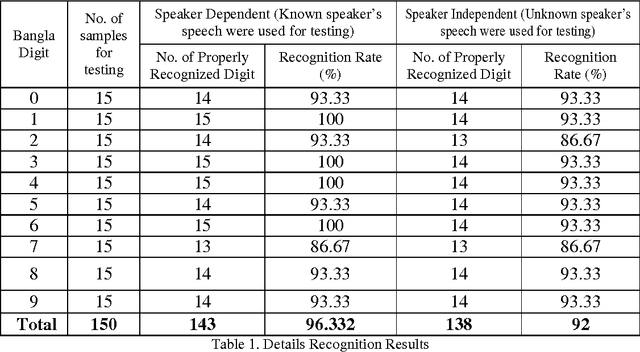
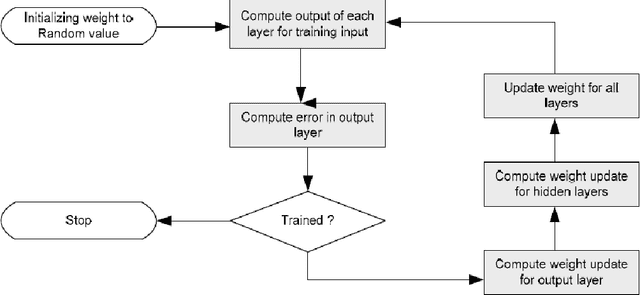

This paper is concerned with the development of Back-propagation Neural Network for Bangla Speech Recognition. In this paper, ten bangla digits were recorded from ten speakers and have been recognized. The features of these speech digits were extracted by the method of Mel Frequency Cepstral Coefficient (MFCC) analysis. The mfcc features of five speakers were used to train the network with Back propagation algorithm. The mfcc features of ten bangla digit speeches, from 0 to 9, of another five speakers were used to test the system. All the methods and algorithms used in this research were implemented using the features of Turbo C and C++ languages. From our investigation it is seen that the developed system can successfully encode and analyze the mfcc features of the speech signal to recognition. The developed system achieved recognition rate about 96.332% for known speakers (i.e., speaker dependent) and 92% for unknown speakers (i.e., speaker independent).
* 9 pages, 3 figures, 1 table
Sequence-level self-learning with multiple hypotheses
Dec 10, 2021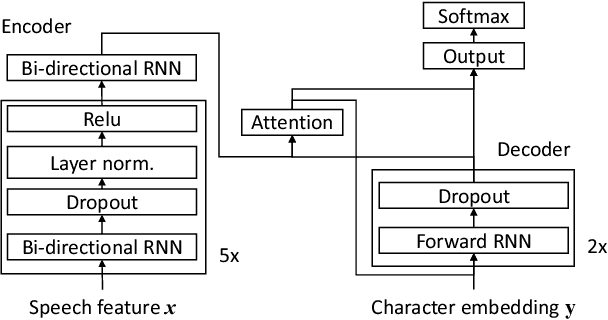
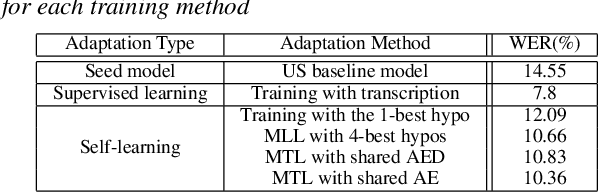
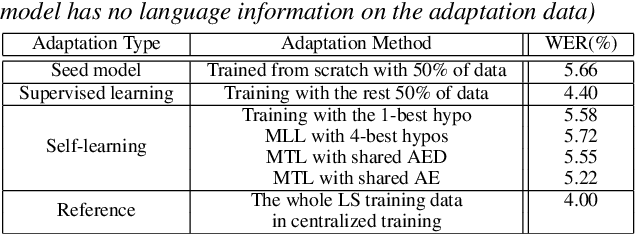
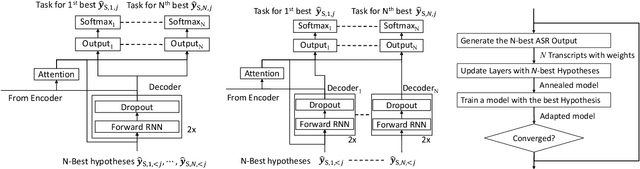
In this work, we develop new self-learning techniques with an attention-based sequence-to-sequence (seq2seq) model for automatic speech recognition (ASR). For untranscribed speech data, the hypothesis from an ASR system must be used as a label. However, the imperfect ASR result makes unsupervised learning difficult to consistently improve recognition performance especially in the case that multiple powerful teacher models are unavailable. In contrast to conventional unsupervised learning approaches, we adopt the \emph{multi-task learning} (MTL) framework where the $n$-th best ASR hypothesis is used as the label of each task. The seq2seq network is updated through the MTL framework so as to find the common representation that can cover multiple hypotheses. By doing so, the effect of the \emph{hard-decision} errors can be alleviated. We first demonstrate the effectiveness of our self-learning methods through ASR experiments in an accent adaptation task between the US and British English speech. Our experiment results show that our method can reduce the WER on the British speech data from 14.55\% to 10.36\% compared to the baseline model trained with the US English data only. Moreover, we investigate the effect of our proposed methods in a federated learning scenario.
An empirical assessment of deep learning approaches to task-oriented dialog management
Aug 07, 2021Deep learning is providing very positive results in areas related to conversational interfaces, such as speech recognition, but its potential benefit for dialog management has still not been fully studied. In this paper, we perform an assessment of different configurations for deep-learned dialog management with three dialog corpora from different application domains and varying in size, dimensionality and possible system responses. Our results have allowed us to identify several aspects that can have an impact on accuracy, including the approaches used for feature extraction, input representation, context consideration and the hyper-parameters of the deep neural networks employed.
A.I. based Embedded Speech to Text Using Deepspeech
Feb 25, 2020
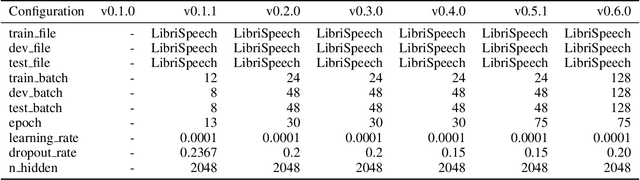
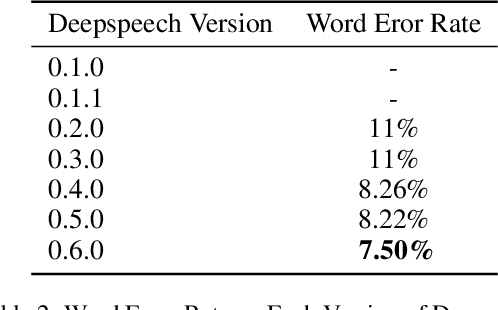
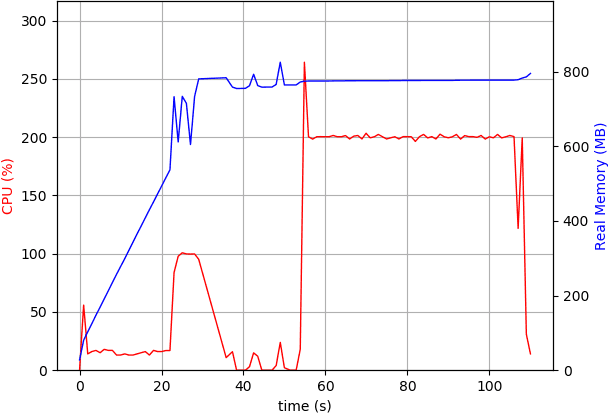
Deepspeech was very useful for development IoT devices that need voice recognition. One of the voice recognition systems is deepspeech from Mozilla. Deepspeech is an open-source voice recognition that was using a neural network to convert speech spectrogram into a text transcript. This paper shows the implementation process of speech recognition on a low-end computational device. Development of English-language speech recognition that has many datasets become a good point for starting. The model that used results from pre-trained model that provide by each version of deepspeech, without change of the model that already released, furthermore the benefit of using raspberry pi as a media end-to-end speech recognition device become a good thing, user can change and modify of the speech recognition, and also deepspeech can be standalone device without need continuously internet connection to process speech recognition, and even this paper show the power of Tensorflow Lite can make a significant difference on inference by deepspeech rather than using Tensorflow non-Lite.This paper shows the experiment using Deepspeech version 0.1.0, 0.1.1, and 0.6.0, and there is some improvement on Deepspeech version 0.6.0, faster while processing speech-to-text on old hardware raspberry pi 3 b+.