 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTLCD: A Deep Transfer Learning Framework for Cross-Disciplinary Cognitive Diagnosis
Oct 27, 2025Driven by the dual principles of smart education and artificial intelligence technology, the online education model has rapidly emerged as an important component of the education industry. Cognitive diagnostic technology can utilize students' learning data and feedback information in educational evaluation to accurately assess their ability level at the knowledge level. However, while massive amounts of information provide abundant data resources, they also bring about complexity in feature extraction and scarcity of disciplinary data. In cross-disciplinary fields, traditional cognitive diagnostic methods still face many challenges. Given the differences in knowledge systems, cognitive structures, and data characteristics between different disciplines, this paper conducts in-depth research on neural network cognitive diagnosis and knowledge association neural network cognitive diagnosis, and proposes an innovative cross-disciplinary cognitive diagnosis method (TLCD). This method combines deep learning techniques and transfer learning strategies to enhance the performance of the model in the target discipline by utilizing the common features of the main discipline. The experimental results show that the cross-disciplinary cognitive diagnosis model based on deep learning performs better than the basic model in cross-disciplinary cognitive diagnosis tasks, and can more accurately evaluate students' learning situation.
A Closed-Loop Personalized Learning Agent Integrating Neural Cognitive Diagnosis, Bounded-Ability Adaptive Testing, and LLM-Driven Feedback
Oct 26, 2025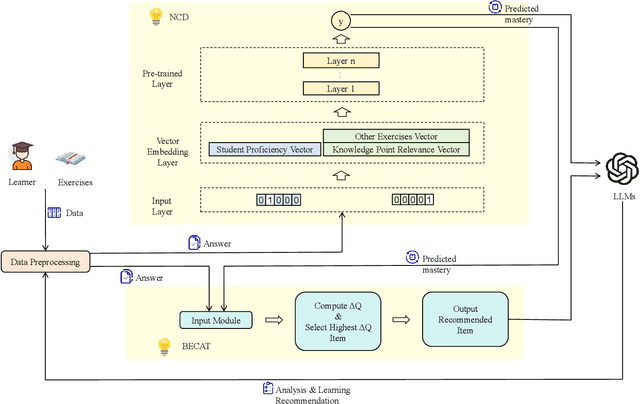
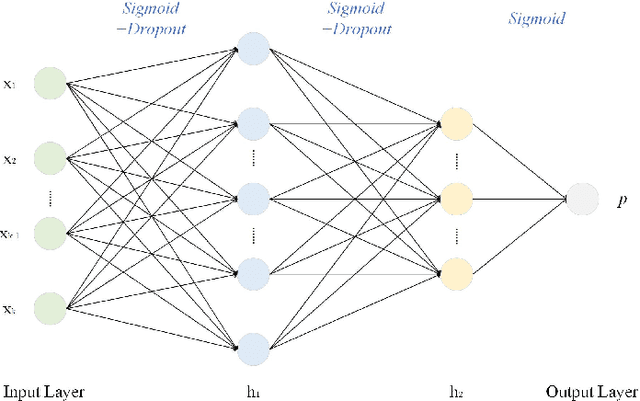
As information technology advances, education is moving from one-size-fits-all instruction toward personalized learning. However, most methods handle modeling, item selection, and feedback in isolation rather than as a closed loop. This leads to coarse or opaque student models, assumption-bound adaptivity that ignores diagnostic posteriors, and generic, non-actionable feedback. To address these limitations, this paper presents an end-to-end personalized learning agent, EduLoop-Agent, which integrates a Neural Cognitive Diagnosis model (NCD), a Bounded-Ability Estimation Computerized Adaptive Testing strategy (BECAT), and large language models (LLMs). The NCD module provides fine-grained estimates of students' mastery at the knowledge-point level; BECAT dynamically selects subsequent items to maximize relevance and learning efficiency; and LLMs convert diagnostic signals into structured, actionable feedback. Together, these components form a closed-loop framework of ``Diagnosis--Recommendation--Feedback.'' Experiments on the ASSISTments dataset show that the NCD module achieves strong performance on response prediction while yielding interpretable mastery assessments. The adaptive recommendation strategy improves item relevance and personalization, and the LLM-based feedback offers targeted study guidance aligned with identified weaknesses. Overall, the results indicate that the proposed design is effective and practically deployable, providing a feasible pathway to generating individualized learning trajectories in intelligent education.
Mobile Recording Device Recognition Based Cross-Scale and Multi-Level Representation Learning
Nov 06, 2024



This paper introduces a modeling approach that employs multi-level global processing, encompassing both short-term frame-level and long-term sample-level feature scales. In the initial stage of shallow feature extraction, various scales are employed to extract multi-level features, including Mel-Frequency Cepstral Coefficients (MFCC) and pre-Fbank log energy spectrum. The construction of the identification network model involves considering the input two-dimensional temporal features from both frame and sample levels. Specifically, the model initially employs one-dimensional convolution-based Convolutional Long Short-Term Memory (ConvLSTM) to fuse spatiotemporal information and extract short-term frame-level features. Subsequently, bidirectional long Short-Term Memory (BiLSTM) is utilized to learn long-term sample-level sequential representations. The transformer encoder then performs cross-scale, multi-level processing on global frame-level and sample-level features, facilitating deep feature representation and fusion at both levels. Finally, recognition results are obtained through Softmax. Our method achieves an impressive 99.6% recognition accuracy on the CCNU_Mobile dataset, exhibiting a notable improvement of 2% to 12% compared to the baseline system. Additionally, we thoroughly investigate the transferability of our model, achieving an 87.9% accuracy in a classification task on a new dataset.
Multi-Scale Deformable Transformers for Student Learning Behavior Detection in Smart Classroom
Oct 10, 2024The integration of Artificial Intelligence into the modern educational system is rapidly evolving, particularly in monitoring student behavior in classrooms, a task traditionally dependent on manual observation. This conventional method is notably inefficient, prompting a shift toward more advanced solutions like computer vision. However, existing target detection models face significant challenges such as occlusion, blurring, and scale disparity, which are exacerbated by the dynamic and complex nature of classroom settings. Furthermore, these models must adeptly handle multiple target detection. To overcome these obstacles, we introduce the Student Learning Behavior Detection with Multi-Scale Deformable Transformers (SCB-DETR), an innovative approach that utilizes large convolutional kernels for upstream feature extraction, and multi-scale feature fusion. This technique significantly improves the detection capabilities for multi-scale and occluded targets, offering a robust solution for analyzing student behavior. SCB-DETR establishes an end-to-end framework that simplifies the detection process and consistently outperforms other deep learning methods. Employing our custom Student Classroom Behavior (SCBehavior) Dataset, SCB-DETR achieves a mean Average Precision (mAP) of 0.626, which is a 1.5% improvement over the baseline model's mAP and a 6% increase in AP50. These results demonstrate SCB-DETR's superior performance in handling the uneven distribution of student behaviors and ensuring precise detection in dynamic classroom environments.
DSARSR: Deep Stacked Auto-encoders Enhanced Robust Speaker Recognition
Jul 06, 2023Speaker recognition is a biometric modality that utilizes the speaker's speech segments to recognize the identity, determining whether the test speaker belongs to one of the enrolled speakers. In order to improve the robustness of the i-vector framework on cross-channel conditions and explore the nova method for applying deep learning to speaker recognition, the Stacked Auto-encoders are used to get the abstract extraction of the i-vector instead of applying PLDA. After pre-processing and feature extraction, the speaker and channel-independent speeches are employed for UBM training. The UBM is then used to extract the i-vector of the enrollment and test speech. Unlike the traditional i-vector framework, which uses linear discriminant analysis (LDA) to reduce dimension and increase the discrimination between speaker subspaces, this research use stacked auto-encoders to reconstruct the i-vector with lower dimension and different classifiers can be chosen to achieve final classification. The experimental results show that the proposed method achieves better performance than the state-of-the-art method.
Learning Behavior Recognition in Smart Classroom with Multiple Students Based on YOLOv5
Mar 20, 2023



Deep learning-based computer vision technology has grown stronger in recent years, and cross-fertilization using computer vision technology has been a popular direction in recent years. The use of computer vision technology to identify students' learning behavior in the classroom can reduce the workload of traditional teachers in supervising students in the classroom, and ensure greater accuracy and comprehensiveness. However, existing student learning behavior detection systems are unable to track and detect multiple targets precisely, and the accuracy of learning behavior recognition is not high enough to meet the existing needs for the accurate recognition of student behavior in the classroom. To solve this problem, we propose a YOLOv5s network structure based on you only look once (YOLO) algorithm to recognize and analyze students' classroom behavior in this paper. Firstly, the input images taken in the smart classroom are pre-processed. Then, the pre-processed image is fed into the designed YOLOv5 networks to extract deep features through convolutional layers, and the Squeeze-and-Excitation (SE) attention detection mechanism is applied to reduce the weight of background information in the recognition process. Finally, the extracted features are classified by the Feature Pyramid Networks (FPN) and Path Aggregation Network (PAN) structures. Multiple groups of experiments were performed to compare with traditional learning behavior recognition methods to validate the effectiveness of the proposed method. When compared with YOLOv4, the proposed method is able to improve the mAP performance by 11%.
Graph Neural Networks Enhanced Smart Contract Vulnerability Detection of Educational Blockchain
Mar 08, 2023With the development of blockchain technology, more and more attention has been paid to the intersection of blockchain and education, and various educational evaluation systems and E-learning systems are developed based on blockchain technology. Among them, Ethereum smart contract is favored by developers for its ``event-triggered" mechanism for building education intelligent trading systems and intelligent learning platforms. However, due to the immutability of blockchain, published smart contracts cannot be modified, so problematic contracts cannot be fixed by modifying the code in the educational blockchain. In recent years, security incidents due to smart contract vulnerabilities have caused huge property losses, so the detection of smart contract vulnerabilities in educational blockchain has become a great challenge. To solve this problem, this paper proposes a graph neural network (GNN) based vulnerability detection for smart contracts in educational blockchains. Firstly, the bytecodes are decompiled to get the opcode. Secondly, the basic blocks are divided, and the edges between the basic blocks according to the opcode execution logic are added. Then, the control flow graphs (CFG) are built. Finally, we designed a GNN-based model for vulnerability detection. The experimental results show that the proposed method is effective for the vulnerability detection of smart contracts. Compared with the traditional approaches, it can get good results with fewer layers of the GCN model, which shows that the contract bytecode and GCN model are efficient in vulnerability detection.
End-to-end Recording Device Identification Based on Deep Representation Learning
Dec 05, 2022



Deep learning techniques have achieved specific results in recording device source identification. The recording device source features include spatial information and certain temporal information. However, most recording device source identification methods based on deep learning only use spatial representation learning from recording device source features, which cannot make full use of recording device source information. Therefore, in this paper, to fully explore the spatial information and temporal information of recording device source, we propose a new method for recording device source identification based on the fusion of spatial feature information and temporal feature information by using an end-to-end framework. From a feature perspective, we designed two kinds of networks to extract recording device source spatial and temporal information. Afterward, we use the attention mechanism to adaptively assign the weight of spatial information and temporal information to obtain fusion features. From a model perspective, our model uses an end-to-end framework to learn the deep representation from spatial feature and temporal feature and train using deep and shallow loss to joint optimize our network. This method is compared with our previous work and baseline system. The results show that the proposed method is better than our previous work and baseline system under general conditions.
JSRNN: Joint Sampling and Reconstruction Neural Networks for High Quality Image Compressed Sensing
Nov 11, 2022Most Deep Learning (DL) based Compressed Sensing (DCS) algorithms adopt a single neural network for signal reconstruction, and fail to jointly consider the influences of the sampling operation for reconstruction. In this paper, we propose unified framework, which jointly considers the sampling and reconstruction process for image compressive sensing based on well-designed cascade neural networks. Two sub-networks, which are the sampling sub-network and the reconstruction sub-network, are included in the proposed framework. In the sampling sub-network, an adaptive full connected layer instead of the traditional random matrix is used to mimic the sampling operator. In the reconstruction sub-network, a cascade network combining stacked denoising autoencoder (SDA) and convolutional neural network (CNN) is designed to reconstruct signals. The SDA is used to solve the signal mapping problem and the signals are initially reconstructed. Furthermore, CNN is used to fully recover the structure and texture features of the image to obtain better reconstruction performance. Extensive experiments show that this framework outperforms many other state-of-the-art methods, especially at low sampling rates.
Audio Tampering Detection Based on Shallow and Deep Feature Representation Learning
Oct 19, 2022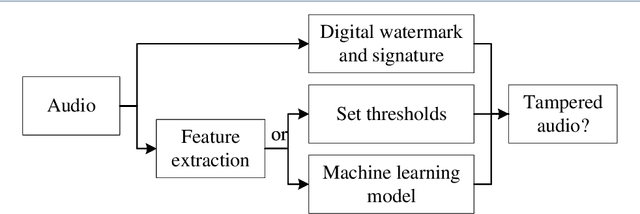

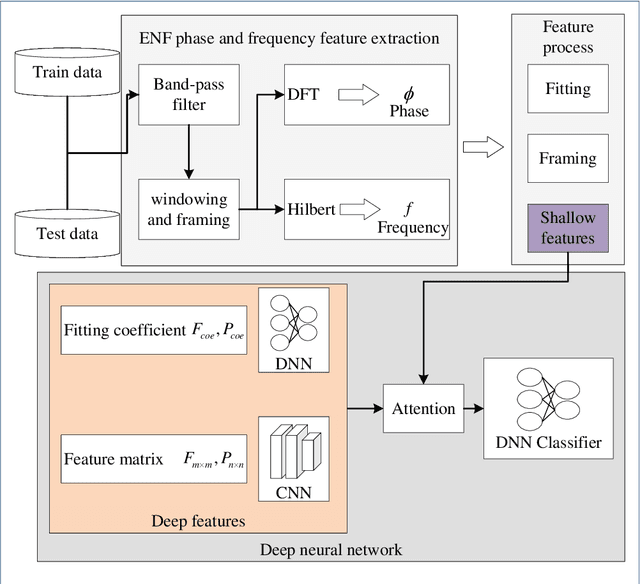

Digital audio tampering detection can be used to verify the authenticity of digital audio. However, most current methods use standard electronic network frequency (ENF) databases for visual comparison analysis of ENF continuity of digital audio or perform feature extraction for classification by machine learning methods. ENF databases are usually tricky to obtain, visual methods have weak feature representation, and machine learning methods have more information loss in features, resulting in low detection accuracy. This paper proposes a fusion method of shallow and deep features to fully use ENF information by exploiting the complementary nature of features at different levels to more accurately describe the changes in inconsistency produced by tampering operations to raw digital audio. The method achieves 97.03% accuracy on three classic databases: Carioca 1, Carioca 2, and New Spanish. In addition, we have achieved an accuracy of 88.31% on the newly constructed database GAUDI-DI. Experimental results show that the proposed method is superior to the state-of-the-art method.