 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShift-Dependent Asymmetry: Orthogonal Inverse Low-Rank Adaptation for Federated Medical Segmentation
Jun 07, 2026Low-Rank Adaptation (LoRA) enables efficient federated fine-tuning of segmentation foundation models for medical imaging. However, most federated LoRA methods adopt a uniform aggregation rule, which breaks under the encoder-decoder asymmetry in medical segmentation: the encoder is dominated by appearance shifts, while the decoder is dominated by supervision variations. This mismatch entangles shared anatomy with site-specific biases and harms generalization. To address this, we propose Inverse Asymmetric Tuning (IAT). IAT aligns adaptation with heterogeneity sources by personalizing module-specific components in the encoder to absorb appearance shifts and in the decoder to accommodate site-dependent supervision, while retaining a shared pathway for transferable consensus. However, structural separation alone is insufficient under LoRA's bilinear parameterization, where multiplicative coupling can still cause site-specific updates to leak into the shared direction. We therefore introduce a Subspace Orthogonality Regularizer that penalizes shared-local collinearity in the effective update space, mitigating leakage without extra communication. Experiments show consistent improvements over strong federated LoRA and parameter-efficient FL baselines.
AstroRAG -- A Pagerank-Based Retrieval-Augmented Generation Pipeline for Question Answering in Astronomy
May 24, 2026Large language models (LLMs) demonstrate strong performance in natural language processing but often generate factual errors when relying solely on parametric knowledge. Retrieval-Augmented Generation (RAG) mitigates these errors by grounding responses in external evidence, yet conventional retrieve-and-dump approaches frequently introduce irrelevant context that degrades answer quality. In this work, we present AstroRAG -- a PageRank-based retrieval-augmented generation (RAG) pipeline adapted for question answering in astronomy. The system performs token-aware chunking and per-instance, ephemeral indexing in Elasticsearch, then executes a two-stage retrieval: (i) Maximal Marginal Relevance (MMR) to obtain a small, diverse candidate set and (ii) a reader-driven PageRank (PR) re-ranking on a similarity graph to identify a compact, mutually supportive context under a strict token budget. Our design is training-free, privacy-preserving, and reproducible, as each instance is processed through transient indexing to prevent cross-task leakage. We evaluate the pipeline on the AstroQA benchmark for astronomy QA, and demonstrate competitive performance across all difficulty levels. In particular, the RAG-enhanced Mistral-7B achieves \textbf{79.49\% accuracy} and \textbf{79.49\% F1-score}, nearly doubling the performance of its non-RAG counterpart. These results highlight the effectiveness of disciplined retrieval and refinement in boosting domain-specific reasoning, establishing a robust foundation for extending RAG to other scientific fields.
ReconMIL: Synergizing Latent Space Reconstruction with Bi-Stream Mamba for Whole Slide Image Analysis
Mar 20, 2026Whole slide image (WSI) analysis heavily relies on multiple instance learning (MIL). While recent methods benefit from large-scale foundation models and advanced sequence modeling to capture long-range dependencies, they still struggle with two critical issues. First, directly applying frozen, task-agnostic features often leads to suboptimal separability due to the domain gap with specific histological tasks. Second, relying solely on global aggregators can cause over-smoothing, where sparse but critical diagnostic signals are overshadowed by the dominant background context. In this paper, we present ReconMIL, a novel framework designed to bridge this domain gap and balance global-local feature aggregation. Our approach introduces a Latent Space Reconstruction module that adaptively projects generic features into a compact, task-specific manifold, improving boundary delineation. To prevent information dilution, we develop a bi-stream architecture combining a Mamba-based global stream for contextual priors and a CNN-based local stream to preserve subtle morphological anomalies. A scale-adaptive selection mechanism dynamically fuses these two streams, determining when to rely on overall architecture versus local saliency. Evaluations across multiple diagnostic and survival prediction benchmarks show that ReconMIL consistently outperforms current state-of-the-art methods, effectively localizing fine-grained diagnostic regions while suppressing background noise. Visualization results confirm the models superior ability to localize diagnostic regions by effectively balancing global structure and local granularity.
R4Det: 4D Radar-Camera Fusion for High-Performance 3D Object Detection
Mar 12, 20264D radar-camera sensing configuration has gained increasing importance in autonomous driving. However, existing 3D object detection methods that fuse 4D Radar and camera data confront several challenges. First, their absolute depth estimation module is not robust and accurate enough, leading to inaccurate 3D localization. Second, the performance of their temporal fusion module will degrade dramatically or even fail when the ego vehicle's pose is missing or inaccurate. Third, for some small objects, the sparse radar point clouds may completely fail to reflect from their surfaces. In such cases, detection must rely solely on visual unimodal priors. To address these limitations, we propose R4Det, which enhances depth estimation quality via the Panoramic Depth Fusion module, enabling mutual reinforcement between absolute and relative depth. For temporal fusion, we design a Deformable Gated Temporal Fusion module that does not rely on the ego vehicle's pose. In addition, we built an Instance-Guided Dynamic Refinement module that extracts semantic prototypes from 2D instance guidance. Experiments show that R4Det achieves state-of-the-art 3D object detection results on the TJ4DRadSet and VoD datasets.
TLCD: A Deep Transfer Learning Framework for Cross-Disciplinary Cognitive Diagnosis
Oct 27, 2025Driven by the dual principles of smart education and artificial intelligence technology, the online education model has rapidly emerged as an important component of the education industry. Cognitive diagnostic technology can utilize students' learning data and feedback information in educational evaluation to accurately assess their ability level at the knowledge level. However, while massive amounts of information provide abundant data resources, they also bring about complexity in feature extraction and scarcity of disciplinary data. In cross-disciplinary fields, traditional cognitive diagnostic methods still face many challenges. Given the differences in knowledge systems, cognitive structures, and data characteristics between different disciplines, this paper conducts in-depth research on neural network cognitive diagnosis and knowledge association neural network cognitive diagnosis, and proposes an innovative cross-disciplinary cognitive diagnosis method (TLCD). This method combines deep learning techniques and transfer learning strategies to enhance the performance of the model in the target discipline by utilizing the common features of the main discipline. The experimental results show that the cross-disciplinary cognitive diagnosis model based on deep learning performs better than the basic model in cross-disciplinary cognitive diagnosis tasks, and can more accurately evaluate students' learning situation.
A Closed-Loop Personalized Learning Agent Integrating Neural Cognitive Diagnosis, Bounded-Ability Adaptive Testing, and LLM-Driven Feedback
Oct 26, 2025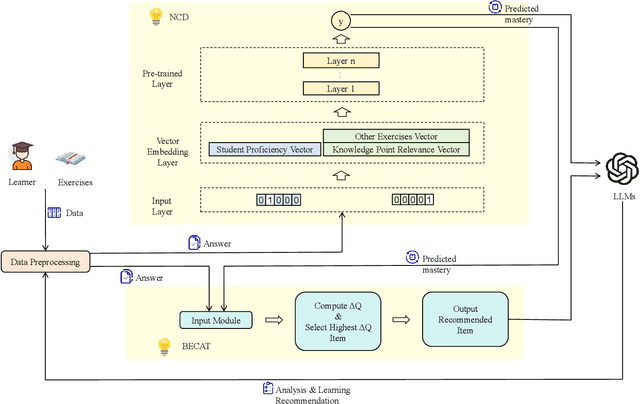
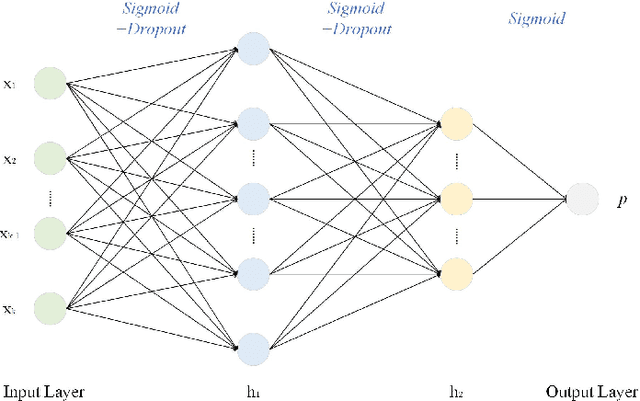
As information technology advances, education is moving from one-size-fits-all instruction toward personalized learning. However, most methods handle modeling, item selection, and feedback in isolation rather than as a closed loop. This leads to coarse or opaque student models, assumption-bound adaptivity that ignores diagnostic posteriors, and generic, non-actionable feedback. To address these limitations, this paper presents an end-to-end personalized learning agent, EduLoop-Agent, which integrates a Neural Cognitive Diagnosis model (NCD), a Bounded-Ability Estimation Computerized Adaptive Testing strategy (BECAT), and large language models (LLMs). The NCD module provides fine-grained estimates of students' mastery at the knowledge-point level; BECAT dynamically selects subsequent items to maximize relevance and learning efficiency; and LLMs convert diagnostic signals into structured, actionable feedback. Together, these components form a closed-loop framework of ``Diagnosis--Recommendation--Feedback.'' Experiments on the ASSISTments dataset show that the NCD module achieves strong performance on response prediction while yielding interpretable mastery assessments. The adaptive recommendation strategy improves item relevance and personalization, and the LLM-based feedback offers targeted study guidance aligned with identified weaknesses. Overall, the results indicate that the proposed design is effective and practically deployable, providing a feasible pathway to generating individualized learning trajectories in intelligent education.
Angio-Diff: Learning a Self-Supervised Adversarial Diffusion Model for Angiographic Geometry Generation
Jun 24, 2025Vascular diseases pose a significant threat to human health, with X-ray angiography established as the gold standard for diagnosis, allowing for detailed observation of blood vessels. However, angiographic X-rays expose personnel and patients to higher radiation levels than non-angiographic X-rays, which are unwanted. Thus, modality translation from non-angiographic to angiographic X-rays is desirable. Data-driven deep approaches are hindered by the lack of paired large-scale X-ray angiography datasets. While making high-quality vascular angiography synthesis crucial, it remains challenging. We find that current medical image synthesis primarily operates at pixel level and struggles to adapt to the complex geometric structure of blood vessels, resulting in unsatisfactory quality of blood vessel image synthesis, such as disconnections or unnatural curvatures. To overcome this issue, we propose a self-supervised method via diffusion models to transform non-angiographic X-rays into angiographic X-rays, mitigating data shortages for data-driven approaches. Our model comprises a diffusion model that learns the distribution of vascular data from diffusion latent, a generator for vessel synthesis, and a mask-based adversarial module. To enhance geometric accuracy, we propose a parametric vascular model to fit the shape and distribution of blood vessels. The proposed method contributes a pipeline and a synthetic dataset for X-ray angiography. We conducted extensive comparative and ablation experiments to evaluate the Angio-Diff. The results demonstrate that our method achieves state-of-the-art performance in synthetic angiography image quality and more accurately synthesizes the geometric structure of blood vessels. The code is available at https://github.com/zfw-cv/AngioDiff.
Visual and textual prompts for enhancing emotion recognition in video
Apr 24, 2025Vision Large Language Models (VLLMs) exhibit promising potential for multi-modal understanding, yet their application to video-based emotion recognition remains limited by insufficient spatial and contextual awareness. Traditional approaches, which prioritize isolated facial features, often neglect critical non-verbal cues such as body language, environmental context, and social interactions, leading to reduced robustness in real-world scenarios. To address this gap, we propose Set-of-Vision-Text Prompting (SoVTP), a novel framework that enhances zero-shot emotion recognition by integrating spatial annotations (e.g., bounding boxes, facial landmarks), physiological signals (facial action units), and contextual cues (body posture, scene dynamics, others' emotions) into a unified prompting strategy. SoVTP preserves holistic scene information while enabling fine-grained analysis of facial muscle movements and interpersonal dynamics. Extensive experiments show that SoVTP achieves substantial improvements over existing visual prompting methods, demonstrating its effectiveness in enhancing VLLMs' video emotion recognition capabilities.
Domain-Specific Pruning of Large Mixture-of-Experts Models with Few-shot Demonstrations
Apr 09, 2025



Mixture-of-Experts (MoE) models achieve a favorable trade-off between performance and inference efficiency by activating only a subset of experts. However, the memory overhead of storing all experts remains a major limitation, especially in large-scale MoE models such as DeepSeek-R1 (671B). In this study, we investigate domain specialization and expert redundancy in large-scale MoE models and uncover a consistent behavior we term few-shot expert localization, with only a few demonstrations, the model consistently activates a sparse and stable subset of experts. Building on this observation, we propose a simple yet effective pruning framework, EASY-EP, that leverages a few domain-specific demonstrations to identify and retain only the most relevant experts. EASY-EP comprises two key components: output-aware expert importance assessment and expert-level token contribution estimation. The former evaluates the importance of each expert for the current token by considering the gating scores and magnitudes of the outputs of activated experts, while the latter assesses the contribution of tokens based on representation similarities after and before routed experts. Experiments show that our method can achieve comparable performances and $2.99\times$ throughput under the same memory budget with full DeepSeek-R1 with only half the experts. Our code is available at https://github.com/RUCAIBox/EASYEP.
VasTSD: Learning 3D Vascular Tree-state Space Diffusion Model for Angiography Synthesis
Mar 17, 2025



Angiography imaging is a medical imaging technique that enhances the visibility of blood vessels within the body by using contrast agents. Angiographic images can effectively assist in the diagnosis of vascular diseases. However, contrast agents may bring extra radiation exposure which is harmful to patients with health risks. To mitigate these concerns, in this paper, we aim to automatically generate angiography from non-angiographic inputs, by leveraging and enhancing the inherent physical properties of vascular structures. Previous methods relying on 2D slice-based angiography synthesis struggle with maintaining continuity in 3D vascular structures and exhibit limited effectiveness across different imaging modalities. We propose VasTSD, a 3D vascular tree-state space diffusion model to synthesize angiography from 3D non-angiographic volumes, with a novel state space serialization approach that dynamically constructs vascular tree topologies, integrating these with a diffusion-based generative model to ensure the generation of anatomically continuous vasculature in 3D volumes. A pre-trained vision embedder is employed to construct vascular state space representations, enabling consistent modeling of vascular structures across multiple modalities. Extensive experiments on various angiographic datasets demonstrate the superiority of VasTSD over prior works, achieving enhanced continuity of blood vessels in synthesized angiographic synthesis for multiple modalities and anatomical regions.