 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Phonetically-Oriented Word Error Alignment for Speech Recognition Error Analysis in Speech Translation
Apr 24, 2019

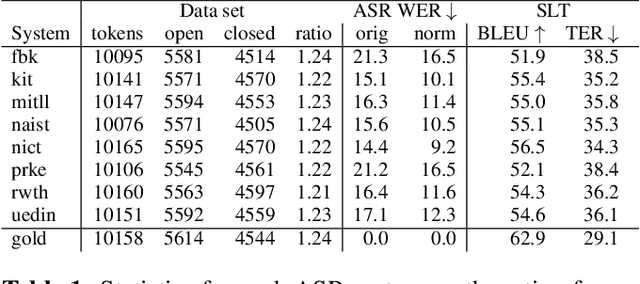
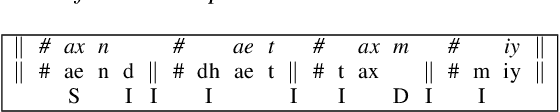
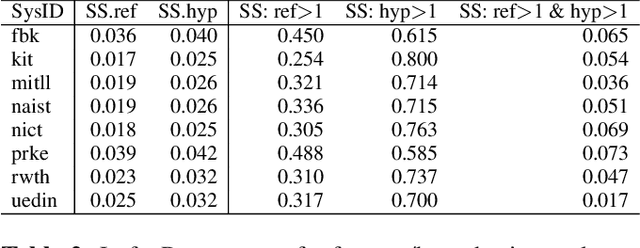
We propose a variation to the commonly used Word Error Rate (WER) metric for speech recognition evaluation which incorporates the alignment of phonemes, in the absence of time boundary information. After computing the Levenshtein alignment on words in the reference and hypothesis transcripts, spans of adjacent errors are converted into phonemes with word and syllable boundaries and a phonetic Levenshtein alignment is performed. The aligned phonemes are recombined into aligned words that adjust the word alignment labels in each error region. We demonstrate that our Phonetically-Oriented Word Error Rate (POWER) yields similar scores to WER with the added advantages of better word alignments and the ability to capture one-to-many word alignments corresponding to homophonic errors in speech recognition hypotheses. These improved alignments allow us to better trace the impact of Levenshtein error types on downstream tasks such as speech translation.
WNARS: WFST based Non-autoregressive Streaming End-to-End Speech Recognition
Apr 08, 2021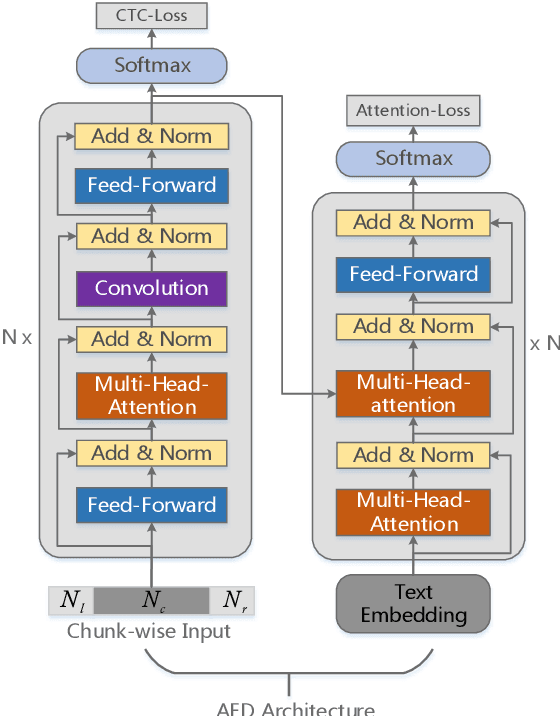


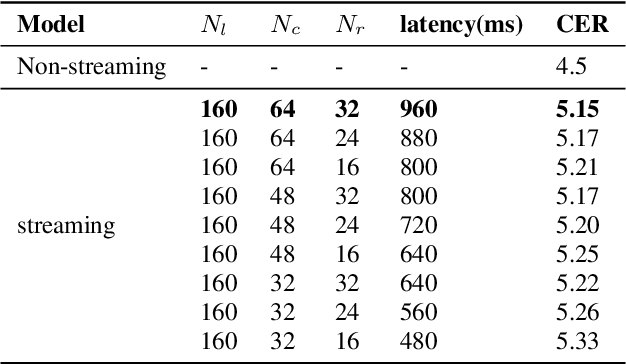
Recently, attention-based encoder-decoder (AED) end-to-end (E2E) models have drawn more and more attention in the field of automatic speech recognition (ASR). AED models, however, still have drawbacks when deploying in commercial applications. Autoregressive beam search decoding makes it inefficient for high-concurrency applications. It is also inconvenient to integrate external word-level language models. The most important thing is that AED models are difficult for streaming recognition due to global attention mechanism. In this paper, we propose a novel framework, namely WNARS, using hybrid CTC-attention AED models and weighted finite-state transducers (WFST) to solve these problems together. We switch from autoregressive beam search to CTC branch decoding, which performs first-pass decoding with WFST in chunk-wise streaming way. The decoder branch then performs second-pass rescoring on the generated hypotheses non-autoregressively. On the AISHELL-1 task, our WNARS achieves a character error rate of 5.22% with 640ms latency, to the best of our knowledge, which is the state-of-the-art performance for online ASR. Further experiments on our 10,000-hour Mandarin task show the proposed method achieves more than 20% improvements with 50% latency compared to a strong TDNN-BLSTM lattice-free MMI baseline.
Should We Always Separate?: Switching Between Enhanced and Observed Signals for Overlapping Speech Recognition
Jun 02, 2021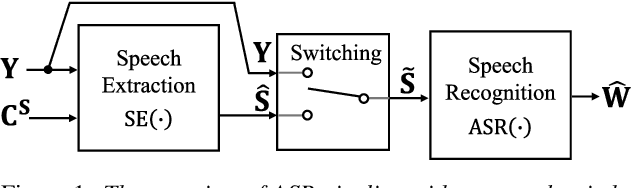
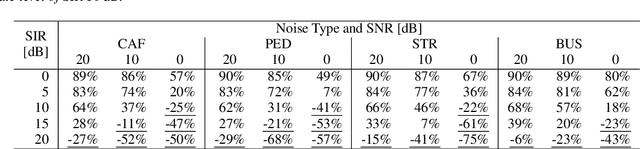
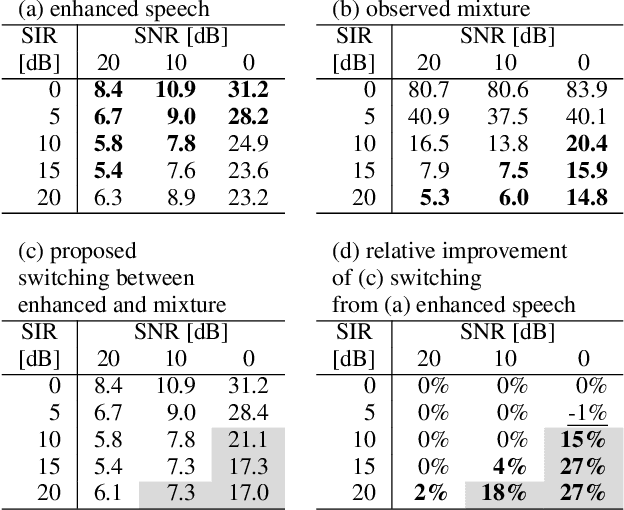
Although recent advances in deep learning technology improved automatic speech recognition (ASR), it remains difficult to recognize speech when it overlaps other people's voices. Speech separation or extraction is often used as a front-end to ASR to handle such overlapping speech. However, deep neural network-based speech enhancement can generate `processing artifacts' as a side effect of the enhancement, which degrades ASR performance. For example, it is well known that single-channel noise reduction for non-speech noise (non-overlapping speech) often does not improve ASR. Likewise, the processing artifacts may also be detrimental to ASR in some conditions when processing overlapping speech with a separation/extraction method, although it is usually believed that separation/extraction improves ASR. In order to answer the question `Do we always have to separate/extract speech from mixtures?', we analyze ASR performance on observed and enhanced speech at various noise and interference conditions, and show that speech enhancement degrades ASR under some conditions even for overlapping speech. Based on these findings, we propose a simple switching algorithm between observed and enhanced speech based on the estimated signal-to-interference ratio and signal-to-noise ratio. We demonstrated experimentally that such a simple switching mechanism can improve recognition performance when processing artifacts are detrimental to ASR.
CORAA: a large corpus of spontaneous and prepared speech manually validated for speech recognition in Brazilian Portuguese
Oct 14, 2021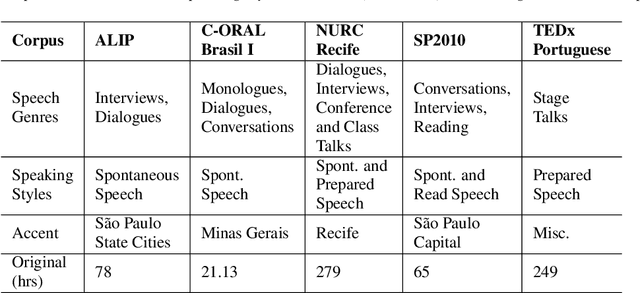
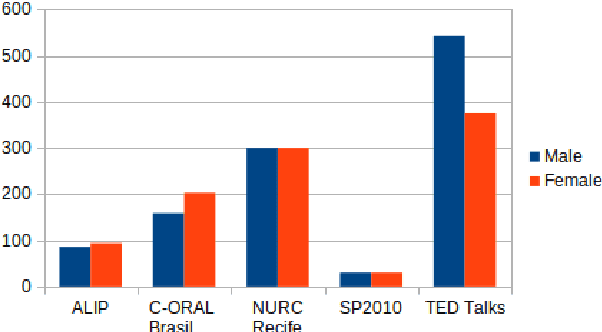
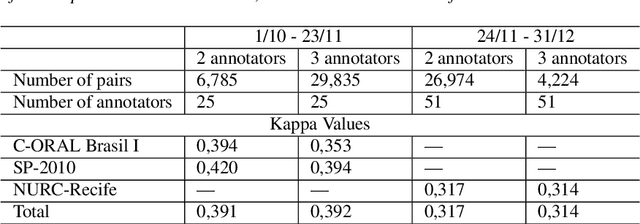
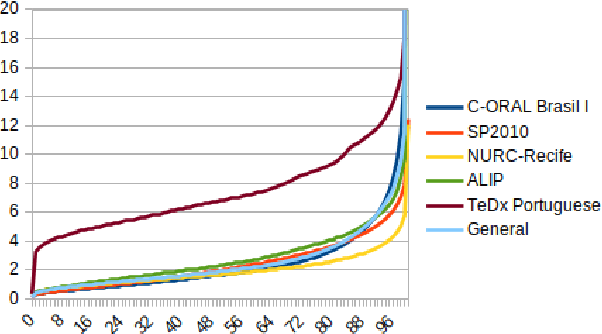
Automatic Speech recognition (ASR) is a complex and challenging task. In recent years, there have been significant advances in the area. In particular, for the Brazilian Portuguese (BP) language, there were about 376 hours public available for ASR task until the second half of 2020. With the release of new datasets in early 2021, this number increased to 574 hours. The existing resources, however, are composed of audios containing only read and prepared speech. There is a lack of datasets including spontaneous speech, which are essential in different ASR applications. This paper presents CORAA (Corpus of Annotated Audios) v1. with 291 hours, a publicly available dataset for ASR in BP containing validated pairs (audio-transcription). CORAA also contains European Portuguese audios (4.69 hours). We also present two public ASR models based on Wav2Vec 2.0 XLSR-53 and fine-tuned over CORAA. Our best model achieved a Word Error Rate of 27.35% on CORAA test set and 16.01% on Common Voice test set. When measuring the Character Error Rate, we obtained 14.26% and 5.45% for CORAA and Common Voice, respectively. CORAA corpora were assembled to both improve ASR models in BP with phenomena from spontaneous speech and motivate young researchers to start their studies on ASR for Portuguese. All the corpora are publicly available at https://github.com/nilc-nlp/CORAA under the CC BY-NC-ND 4.0 license.
Improving Self-Supervised Learning for Audio Representations by Feature Diversity and Decorrelation
Mar 07, 2023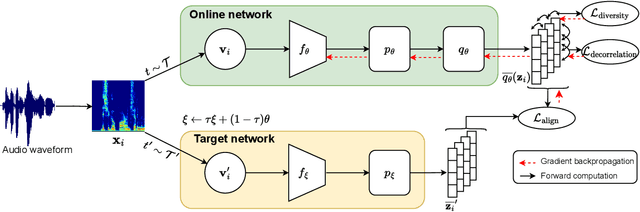
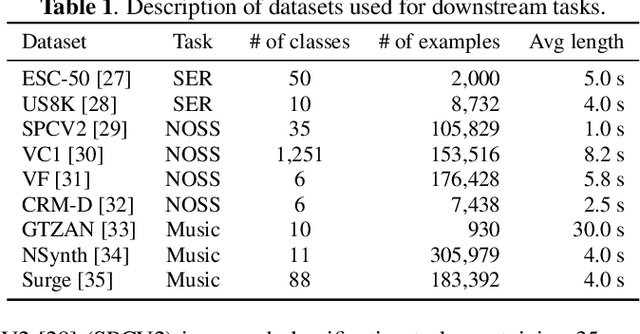
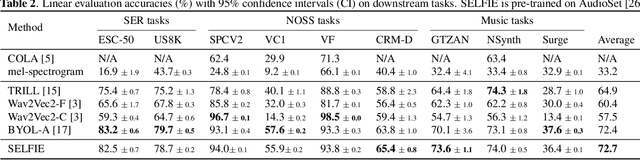
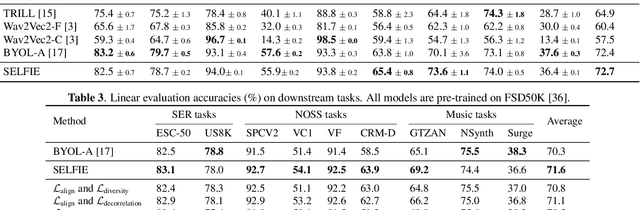
Self-supervised learning (SSL) has recently shown remarkable results in closing the gap between supervised and unsupervised learning. The idea is to learn robust features that are invariant to distortions of the input data. Despite its success, this idea can suffer from a collapsing issue where the network produces a constant representation. To this end, we introduce SELFIE, a novel Self-supervised Learning approach for audio representation via Feature Diversity and Decorrelation. SELFIE avoids the collapsing issue by ensuring that the representation (i) maintains a high diversity among embeddings and (ii) decorrelates the dependencies between dimensions. SELFIE is pre-trained on the large-scale AudioSet dataset and its embeddings are validated on nine audio downstream tasks, including speech, music, and sound event recognition. Experimental results show that SELFIE outperforms existing SSL methods in several tasks.
Align, Write, Re-order: Explainable End-to-End Speech Translation via Operation Sequence Generation
Nov 11, 2022
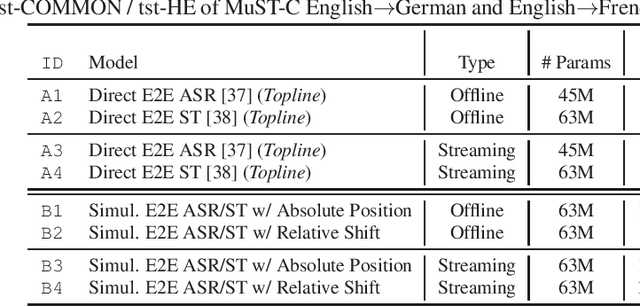
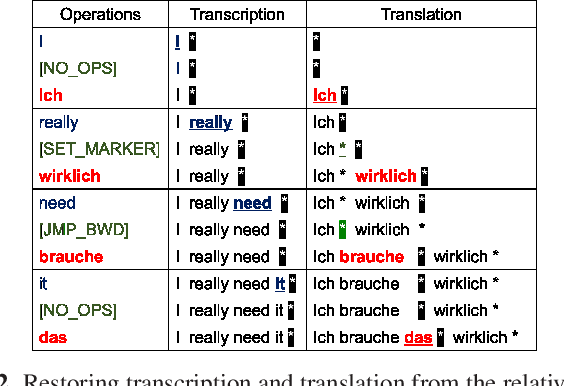
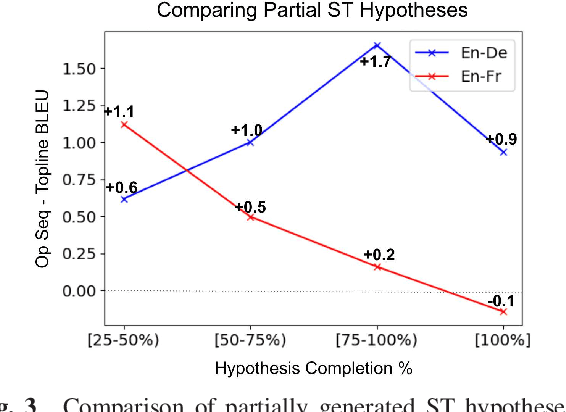
The black-box nature of end-to-end speech translation (E2E ST) systems makes it difficult to understand how source language inputs are being mapped to the target language. To solve this problem, we would like to simultaneously generate automatic speech recognition (ASR) and ST predictions such that each source language word is explicitly mapped to a target language word. A major challenge arises from the fact that translation is a non-monotonic sequence transduction task due to word ordering differences between languages -- this clashes with the monotonic nature of ASR. Therefore, we propose to generate ST tokens out-of-order while remembering how to re-order them later. We achieve this by predicting a sequence of tuples consisting of a source word, the corresponding target words, and post-editing operations dictating the correct insertion points for the target word. We examine two variants of such operation sequences which enable generation of monotonic transcriptions and non-monotonic translations from the same speech input simultaneously. We apply our approach to offline and real-time streaming models, demonstrating that we can provide explainable translations without sacrificing quality or latency. In fact, the delayed re-ordering ability of our approach improves performance during streaming. As an added benefit, our method performs ASR and ST simultaneously, making it faster than using two separate systems to perform these tasks.
A Review of Sparse Expert Models in Deep Learning
Sep 04, 2022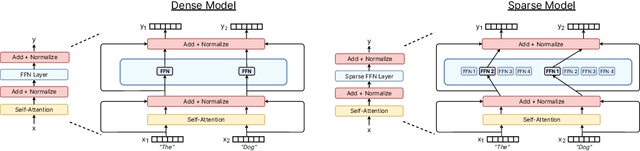

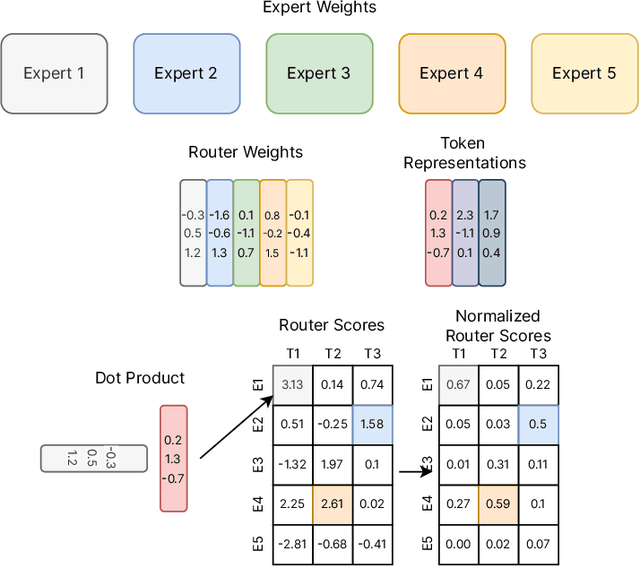

Sparse expert models are a thirty-year old concept re-emerging as a popular architecture in deep learning. This class of architecture encompasses Mixture-of-Experts, Switch Transformers, Routing Networks, BASE layers, and others, all with the unifying idea that each example is acted on by a subset of the parameters. By doing so, the degree of sparsity decouples the parameter count from the compute per example allowing for extremely large, but efficient models. The resulting models have demonstrated significant improvements across diverse domains such as natural language processing, computer vision, and speech recognition. We review the concept of sparse expert models, provide a basic description of the common algorithms, contextualize the advances in the deep learning era, and conclude by highlighting areas for future work.
InterMPL: Momentum Pseudo-Labeling with Intermediate CTC Loss
Nov 02, 2022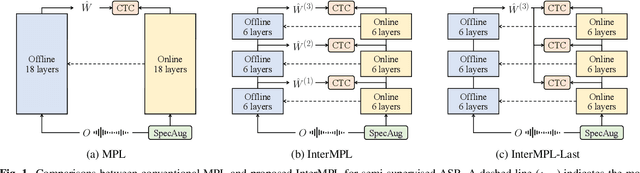
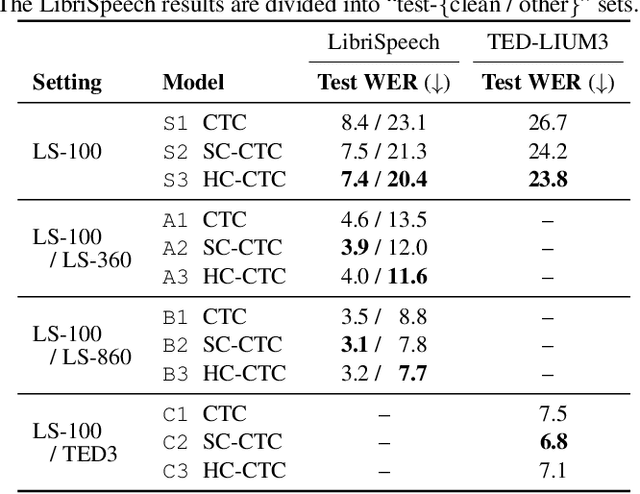
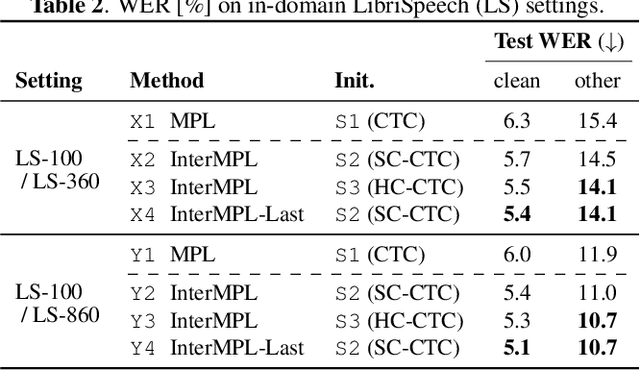
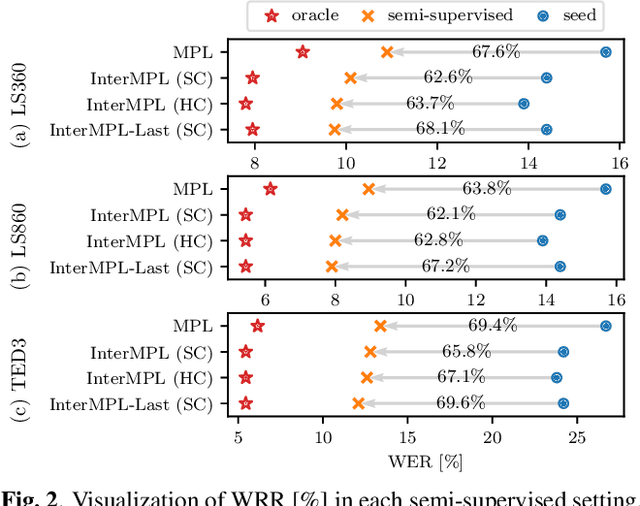
This paper presents InterMPL, a semi-supervised learning method of end-to-end automatic speech recognition (ASR) that performs pseudo-labeling (PL) with intermediate supervision. Momentum PL (MPL) trains a connectionist temporal classification (CTC)-based model on unlabeled data by continuously generating pseudo-labels on the fly and improving their quality. In contrast to autoregressive formulations, such as the attention-based encoder-decoder and transducer, CTC is well suited for MPL, or PL-based semi-supervised ASR in general, owing to its simple/fast inference algorithm and robustness against generating collapsed labels. However, CTC generally yields inferior performance than the autoregressive models due to the conditional independence assumption, thereby limiting the performance of MPL. We propose to enhance MPL by introducing intermediate loss, inspired by the recent advances in CTC-based modeling. Specifically, we focus on self-conditional and hierarchical conditional CTC, that apply auxiliary CTC losses to intermediate layers such that the conditional independence assumption is explicitly relaxed. We also explore how pseudo-labels should be generated and used as supervision for intermediate losses. Experimental results in different semi-supervised settings demonstrate that the proposed approach outperforms MPL and improves an ASR model by up to a 12.1% absolute performance gain. In addition, our detailed analysis validates the importance of the intermediate loss.
BECTRA: Transducer-based End-to-End ASR with BERT-Enhanced Encoder
Nov 02, 2022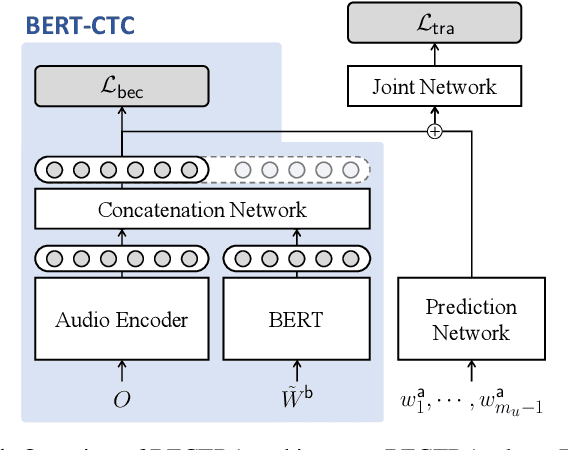

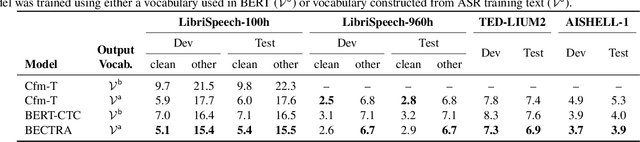
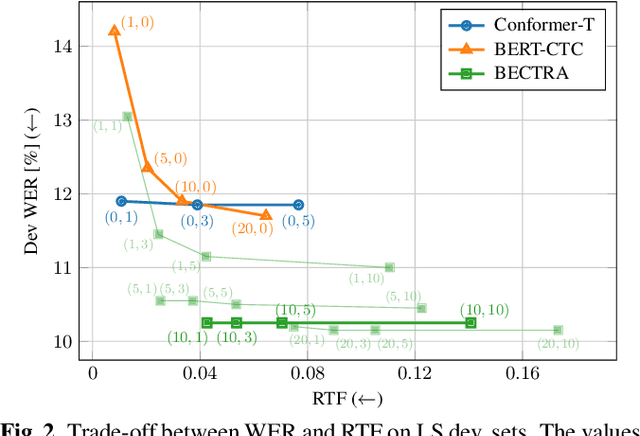
We present BERT-CTC-Transducer (BECTRA), a novel end-to-end automatic speech recognition (E2E-ASR) model formulated by the transducer with a BERT-enhanced encoder. Integrating a large-scale pre-trained language model (LM) into E2E-ASR has been actively studied, aiming to utilize versatile linguistic knowledge for generating accurate text. One crucial factor that makes this integration challenging lies in the vocabulary mismatch; the vocabulary constructed for a pre-trained LM is generally too large for E2E-ASR training and is likely to have a mismatch against a target ASR domain. To overcome such an issue, we propose BECTRA, an extended version of our previous BERT-CTC, that realizes BERT-based E2E-ASR using a vocabulary of interest. BECTRA is a transducer-based model, which adopts BERT-CTC for its encoder and trains an ASR-specific decoder using a vocabulary suitable for a target task. With the combination of the transducer and BERT-CTC, we also propose a novel inference algorithm for taking advantage of both autoregressive and non-autoregressive decoding. Experimental results on several ASR tasks, varying in amounts of data, speaking styles, and languages, demonstrate that BECTRA outperforms BERT-CTC by effectively dealing with the vocabulary mismatch while exploiting BERT knowledge.
ILASR: Privacy-Preserving Incremental Learning for AutomaticSpeech Recognition at Production Scale
Jul 19, 2022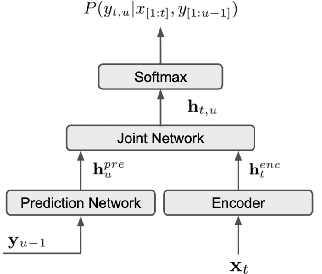
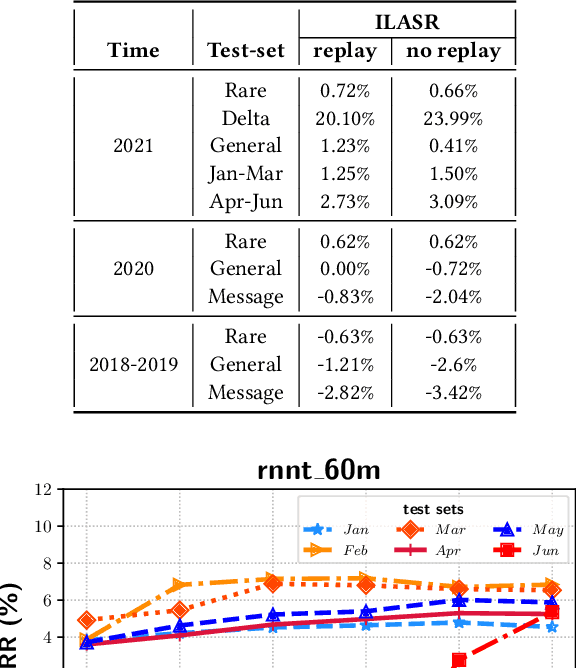
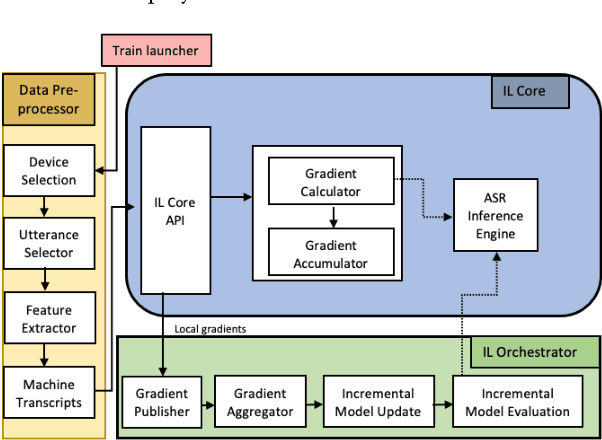
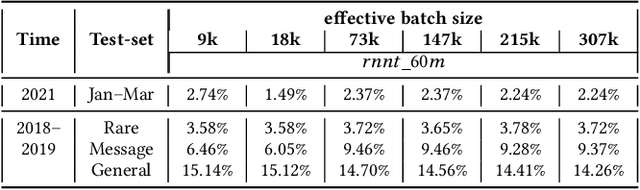
Incremental learning is one paradigm to enable model building and updating at scale with streaming data. For end-to-end automatic speech recognition (ASR) tasks, the absence of human annotated labels along with the need for privacy preserving policies for model building makes it a daunting challenge. Motivated by these challenges, in this paper we use a cloud based framework for production systems to demonstrate insights from privacy preserving incremental learning for automatic speech recognition (ILASR). By privacy preserving, we mean, usage of ephemeral data which are not human annotated. This system is a step forward for production levelASR models for incremental/continual learning that offers near real-time test-bed for experimentation in the cloud for end-to-end ASR, while adhering to privacy-preserving policies. We show that the proposed system can improve the production models significantly(3%) over a new time period of six months even in the absence of human annotated labels with varying levels of weak supervision and large batch sizes in incremental learning. This improvement is 20% over test sets with new words and phrases in the new time period. We demonstrate the effectiveness of model building in a privacy-preserving incremental fashion for ASR while further exploring the utility of having an effective teacher model and use of large batch sizes.