 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNextformer: A ConvNeXt Augmented Conformer For End-To-End Speech Recognition
Jun 30, 2022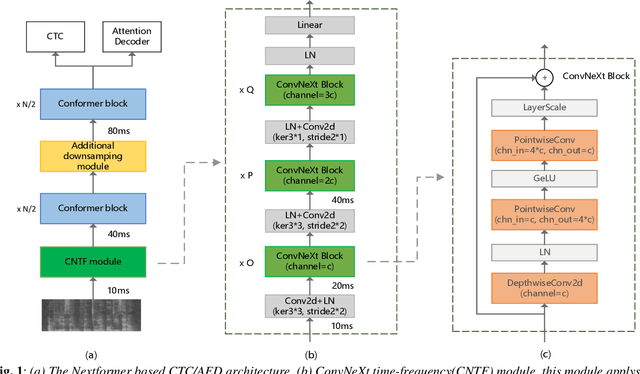
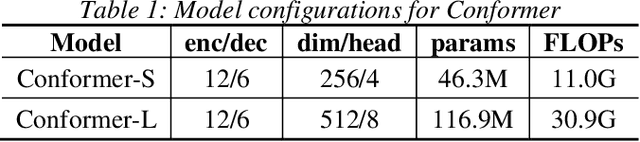
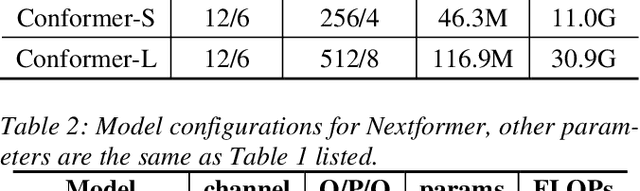
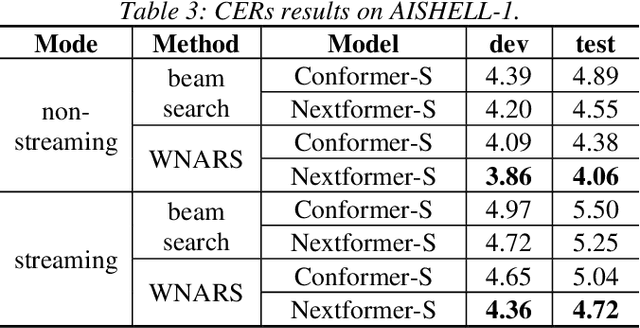
Conformer models have achieved state-of-the-art(SOTA) results in end-to-end speech recognition. However Conformer mainly focuses on temporal modeling while pays less attention on time-frequency property of speech feature. In this paper we augment Conformer with ConvNeXt and propose Nextformer structure. We use stacks of ConvNeXt block to replace the commonly used subsampling module in Conformer for utilizing the information contained in time-frequency speech feature. Besides, we insert an additional downsampling module in middle of Conformer layers to make our model more efficient and accurate. We conduct experiments on two opening datasets, AISHELL-1 and WenetSpeech. On AISHELL-1, compared to Conformer baselines, Nextformer obtains 7.3% and 6.3% relative CER reduction in non-streaming and streaming mode respectively, and on a much larger WenetSpeech dataset, Nextformer gives 5.0%~6.5% and 7.5%~14.6% relative CER reduction in non-streaming and streaming mode, while keep the computational cost FLOPs comparable to Conformer. To the best of our knowledge, the proposed Nextformer model achieves SOTA results on AISHELL-1(CER 4.06%) and WenetSpeech(CER 7.56%/11.29%).
WNARS: WFST based Non-autoregressive Streaming End-to-End Speech Recognition
Apr 21, 2021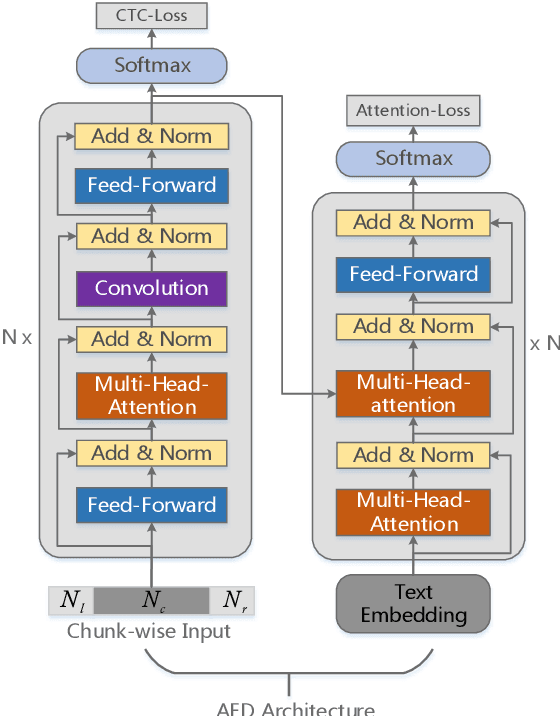


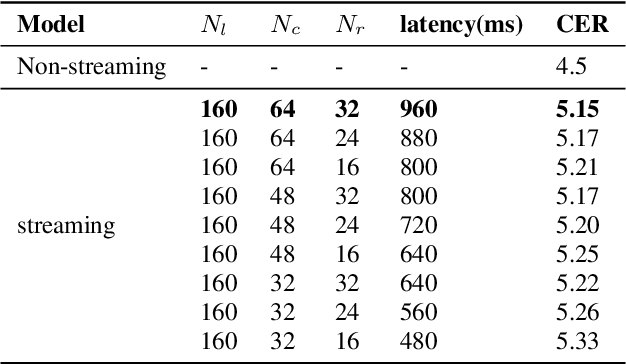
Recently, attention-based encoder-decoder (AED) end-to-end (E2E) models have drawn more and more attention in the field of automatic speech recognition (ASR). AED models, however, still have drawbacks when deploying in commercial applications. Autoregressive beam search decoding makes it inefficient for high-concurrency applications. It is also inconvenient to integrate external word-level language models. The most important thing is that AED models are difficult for streaming recognition due to global attention mechanism. In this paper, we propose a novel framework, namely WNARS, using hybrid CTC-attention AED models and weighted finite-state transducers (WFST) to solve these problems together. We switch from autoregressive beam search to CTC branch decoding, which performs first-pass decoding with WFST in chunk-wise streaming way. The decoder branch then performs second-pass rescoring on the generated hypotheses non-autoregressively. On the AISHELL-1 task, our WNARS achieves a character error rate of 5.22% with 640ms latency, to the best of our knowledge, which is the state-of-the-art performance for online ASR. Further experiments on our 10,000-hour Mandarin task show the proposed method achieves more than 20% improvements with 50% latency compared to a strong TDNN-BLSTM lattice-free MMI baseline.
Modality Attention for End-to-End Audio-visual Speech Recognition
Nov 13, 2018
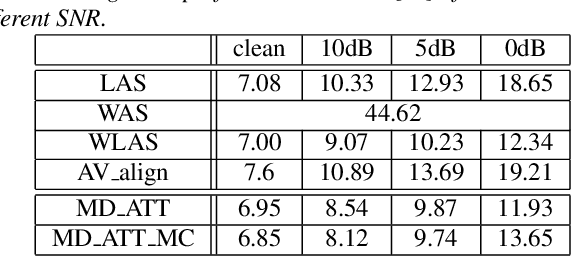
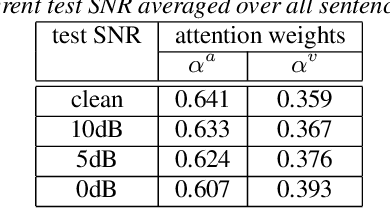
Audio-visual speech recognition (AVSR) system is thought to be one of the most promising solutions for robust speech recognition, especially in noisy environment. In this paper, we propose a novel multimodal attention based method for audio-visual speech recognition which could automatically learn the fused representation from both modalities based on their importance. Our method is realized using state-of-the-art sequence-to-sequence (Seq2seq) architectures. Experimental results show that relative improvements from 2% up to 36% over the auditory modality alone are obtained depending on the different signal-to-noise-ratio (SNR). Compared to the traditional feature concatenation methods, our proposed approach can achieve better recognition performance under both clean and noisy conditions. We believe modality attention based end-to-end method can be easily generalized to other multimodal tasks with correlated information.