 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Speech Recognition with Pre-trained Masked Language Model
Oct 01, 2024



We present a novel approach to end-to-end automatic speech recognition (ASR) that utilizes pre-trained masked language models (LMs) to facilitate the extraction of linguistic information. The proposed models, BERT-CTC and BECTRA, are specifically designed to effectively integrate pre-trained LMs (e.g., BERT) into end-to-end ASR models. BERT-CTC adapts BERT for connectionist temporal classification (CTC) by addressing the constraint of the conditional independence assumption between output tokens. This enables explicit conditioning of BERT's contextualized embeddings in the ASR process, seamlessly merging audio and linguistic information through an iterative refinement algorithm. BECTRA extends BERT-CTC to the transducer framework and trains the decoder network using a vocabulary suitable for ASR training. This aims to bridge the gap between the text processed in end-to-end ASR and BERT, as these models have distinct vocabularies with varying text formats and styles, such as the presence of punctuation. Experimental results on various ASR tasks demonstrate that the proposed models improve over both the CTC and transducer-based baselines, owing to the incorporation of BERT knowledge. Moreover, our in-depth analysis and investigation verify the effectiveness of the proposed formulations and architectural designs.
Predictive Speech Recognition and End-of-Utterance Detection Towards Spoken Dialog Systems
Sep 30, 2024



Effective spoken dialog systems should facilitate natural interactions with quick and rhythmic timing, mirroring human communication patterns. To reduce response times, previous efforts have focused on minimizing the latency in automatic speech recognition (ASR) to optimize system efficiency. However, this approach requires waiting for ASR to complete processing until a speaker has finished speaking, which limits the time available for natural language processing (NLP) to formulate accurate responses. As humans, we continuously anticipate and prepare responses even while the other party is still speaking. This allows us to respond appropriately without missing the optimal time to speak. In this work, as a pioneering study toward a conversational system that simulates such human anticipatory behavior, we aim to realize a function that can predict the forthcoming words and estimate the time remaining until the end of an utterance (EOU), using the middle portion of an utterance. To achieve this, we propose a training strategy for an encoder-decoder-based ASR system, which involves masking future segments of an utterance and prompting the decoder to predict the words in the masked audio. Additionally, we develop a cross-attention-based algorithm that incorporates both acoustic and linguistic information to accurately detect the EOU. The experimental results demonstrate the proposed model's ability to predict upcoming words and estimate future EOU events up to 300ms prior to the actual EOU. Moreover, the proposed training strategy exhibits general improvements in ASR performance.
A Single Speech Enhancement Model Unifying Dereverberation, Denoising, Speaker Counting, Separation, and Extraction
Oct 12, 2023We propose a multi-task universal speech enhancement (MUSE) model that can perform five speech enhancement (SE) tasks: dereverberation, denoising, speech separation (SS), target speaker extraction (TSE), and speaker counting. This is achieved by integrating two modules into an SE model: 1) an internal separation module that does both speaker counting and separation; and 2) a TSE module that extracts the target speech from the internal separation outputs using target speaker cues. The model is trained to perform TSE if the target speaker cue is given and SS otherwise. By training the model to remove noise and reverberation, we allow the model to tackle the five tasks mentioned above with a single model, which has not been accomplished yet. Evaluation results demonstrate that the proposed MUSE model can successfully handle multiple tasks with a single model.
Harnessing the Zero-Shot Power of Instruction-Tuned Large Language Model in End-to-End Speech Recognition
Sep 19, 2023



We present a novel integration of an instruction-tuned large language model (LLM) and end-to-end automatic speech recognition (ASR). Modern LLMs can perform a wide range of linguistic tasks within zero-shot learning when provided with a precise instruction or a prompt to guide the text generation process towards the desired task. We explore using this zero-shot capability of LLMs to extract linguistic information that can contribute to improving ASR performance. Specifically, we direct an LLM to correct grammatical errors in an ASR hypothesis and harness the embedded linguistic knowledge to conduct end-to-end ASR. The proposed model is built on the hybrid connectionist temporal classification (CTC) and attention architecture, where an instruction-tuned LLM (i.e., Llama2) is employed as a front-end of the decoder. An ASR hypothesis, subject to correction, is obtained from the encoder via CTC decoding, which is then fed into the LLM along with an instruction. The decoder subsequently takes as input the LLM embeddings to perform sequence generation, incorporating acoustic information from the encoder output. Experimental results and analyses demonstrate that the proposed integration yields promising performance improvements, and our approach largely benefits from LLM-based rescoring.
Mask-CTC-based Encoder Pre-training for Streaming End-to-End Speech Recognition
Sep 09, 2023



Achieving high accuracy with low latency has always been a challenge in streaming end-to-end automatic speech recognition (ASR) systems. By attending to more future contexts, a streaming ASR model achieves higher accuracy but results in larger latency, which hurts the streaming performance. In the Mask-CTC framework, an encoder network is trained to learn the feature representation that anticipates long-term contexts, which is desirable for streaming ASR. Mask-CTC-based encoder pre-training has been shown beneficial in achieving low latency and high accuracy for triggered attention-based ASR. However, the effectiveness of this method has not been demonstrated for various model architectures, nor has it been verified that the encoder has the expected look-ahead capability to reduce latency. This study, therefore, examines the effectiveness of Mask-CTCbased pre-training for models with different architectures, such as Transformer-Transducer and contextual block streaming ASR. We also discuss the effect of the proposed pre-training method on obtaining accurate output spike timing.
Conversation-oriented ASR with multi-look-ahead CBS architecture
Nov 02, 2022


During conversations, humans are capable of inferring the intention of the speaker at any point of the speech to prepare the following action promptly. Such ability is also the key for conversational systems to achieve rhythmic and natural conversation. To perform this, the automatic speech recognition (ASR) used for transcribing the speech in real-time must achieve high accuracy without delay. In streaming ASR, high accuracy is assured by attending to look-ahead frames, which leads to delay increments. To tackle this trade-off issue, we propose a multiple latency streaming ASR to achieve high accuracy with zero look-ahead. The proposed system contains two encoders that operate in parallel, where a primary encoder generates accurate outputs utilizing look-ahead frames, and the auxiliary encoder recognizes the look-ahead portion of the primary encoder without look-ahead. The proposed system is constructed based on contextual block streaming (CBS) architecture, which leverages block processing and has a high affinity for the multiple latency architecture. Various methods are also studied for architecting the system, including shifting the network to perform as different encoders; as well as generating both encoders' outputs in one encoding pass.
InterMPL: Momentum Pseudo-Labeling with Intermediate CTC Loss
Nov 02, 2022



This paper presents InterMPL, a semi-supervised learning method of end-to-end automatic speech recognition (ASR) that performs pseudo-labeling (PL) with intermediate supervision. Momentum PL (MPL) trains a connectionist temporal classification (CTC)-based model on unlabeled data by continuously generating pseudo-labels on the fly and improving their quality. In contrast to autoregressive formulations, such as the attention-based encoder-decoder and transducer, CTC is well suited for MPL, or PL-based semi-supervised ASR in general, owing to its simple/fast inference algorithm and robustness against generating collapsed labels. However, CTC generally yields inferior performance than the autoregressive models due to the conditional independence assumption, thereby limiting the performance of MPL. We propose to enhance MPL by introducing intermediate loss, inspired by the recent advances in CTC-based modeling. Specifically, we focus on self-conditional and hierarchical conditional CTC, that apply auxiliary CTC losses to intermediate layers such that the conditional independence assumption is explicitly relaxed. We also explore how pseudo-labels should be generated and used as supervision for intermediate losses. Experimental results in different semi-supervised settings demonstrate that the proposed approach outperforms MPL and improves an ASR model by up to a 12.1% absolute performance gain. In addition, our detailed analysis validates the importance of the intermediate loss.
BECTRA: Transducer-based End-to-End ASR with BERT-Enhanced Encoder
Nov 02, 2022



We present BERT-CTC-Transducer (BECTRA), a novel end-to-end automatic speech recognition (E2E-ASR) model formulated by the transducer with a BERT-enhanced encoder. Integrating a large-scale pre-trained language model (LM) into E2E-ASR has been actively studied, aiming to utilize versatile linguistic knowledge for generating accurate text. One crucial factor that makes this integration challenging lies in the vocabulary mismatch; the vocabulary constructed for a pre-trained LM is generally too large for E2E-ASR training and is likely to have a mismatch against a target ASR domain. To overcome such an issue, we propose BECTRA, an extended version of our previous BERT-CTC, that realizes BERT-based E2E-ASR using a vocabulary of interest. BECTRA is a transducer-based model, which adopts BERT-CTC for its encoder and trains an ASR-specific decoder using a vocabulary suitable for a target task. With the combination of the transducer and BERT-CTC, we also propose a novel inference algorithm for taking advantage of both autoregressive and non-autoregressive decoding. Experimental results on several ASR tasks, varying in amounts of data, speaking styles, and languages, demonstrate that BECTRA outperforms BERT-CTC by effectively dealing with the vocabulary mismatch while exploiting BERT knowledge.
BERT Meets CTC: New Formulation of End-to-End Speech Recognition with Pre-trained Masked Language Model
Oct 29, 2022



This paper presents BERT-CTC, a novel formulation of end-to-end speech recognition that adapts BERT for connectionist temporal classification (CTC). Our formulation relaxes the conditional independence assumptions used in conventional CTC and incorporates linguistic knowledge through the explicit output dependency obtained by BERT contextual embedding. BERT-CTC attends to the full contexts of the input and hypothesized output sequences via the self-attention mechanism. This mechanism encourages a model to learn inner/inter-dependencies between the audio and token representations while maintaining CTC's training efficiency. During inference, BERT-CTC combines a mask-predict algorithm with CTC decoding, which iteratively refines an output sequence. The experimental results reveal that BERT-CTC improves over conventional approaches across variations in speaking styles and languages. Finally, we show that the semantic representations in BERT-CTC are beneficial towards downstream spoken language understanding tasks.
An Investigation of Enhancing CTC Model for Triggered Attention-based Streaming ASR
Oct 20, 2021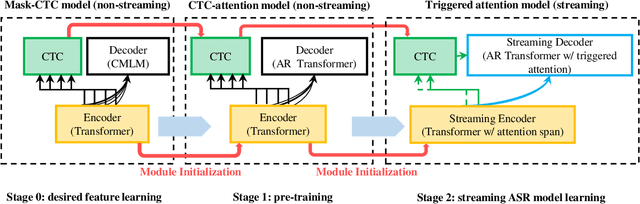

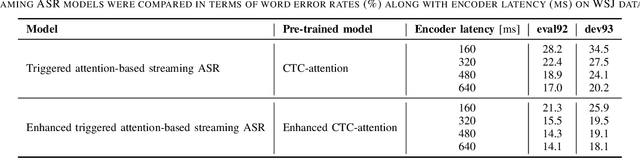
In the present paper, an attempt is made to combine Mask-CTC and the triggered attention mechanism to construct a streaming end-to-end automatic speech recognition (ASR) system that provides high performance with low latency. The triggered attention mechanism, which performs autoregressive decoding triggered by the CTC spike, has shown to be effective in streaming ASR. However, in order to maintain high accuracy of alignment estimation based on CTC outputs, which is the key to its performance, it is inevitable that decoding should be performed with some future information input (i.e., with higher latency). It should be noted that in streaming ASR, it is desirable to be able to achieve high recognition accuracy while keeping the latency low. Therefore, the present study aims to achieve highly accurate streaming ASR with low latency by introducing Mask-CTC, which is capable of learning feature representations that anticipate future information (i.e., that can consider long-term contexts), to the encoder pre-training. Experimental comparisons conducted using WSJ data demonstrate that the proposed method achieves higher accuracy with lower latency than the conventional triggered attention-based streaming ASR system.