 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCORAA: a large corpus of spontaneous and prepared speech manually validated for speech recognition in Brazilian Portuguese
Oct 14, 2021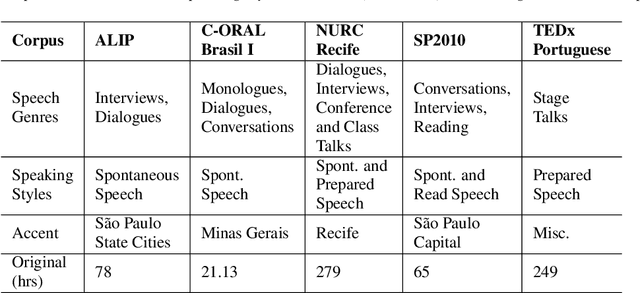
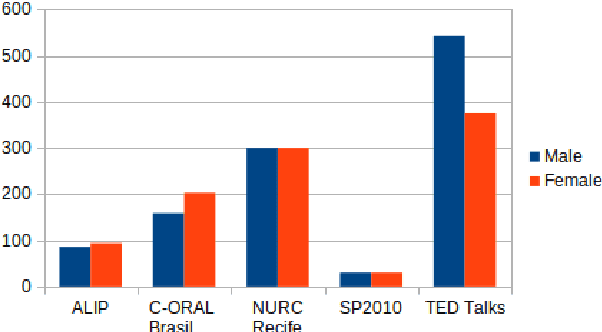
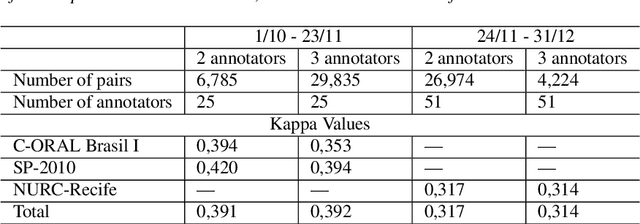
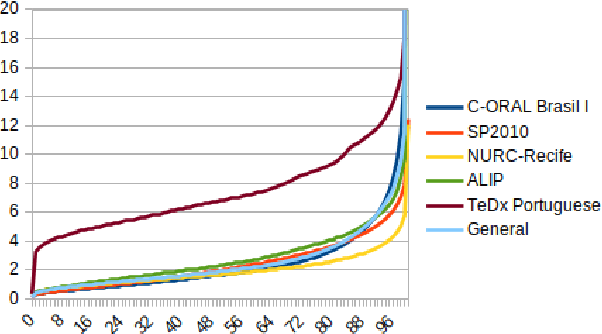
Automatic Speech recognition (ASR) is a complex and challenging task. In recent years, there have been significant advances in the area. In particular, for the Brazilian Portuguese (BP) language, there were about 376 hours public available for ASR task until the second half of 2020. With the release of new datasets in early 2021, this number increased to 574 hours. The existing resources, however, are composed of audios containing only read and prepared speech. There is a lack of datasets including spontaneous speech, which are essential in different ASR applications. This paper presents CORAA (Corpus of Annotated Audios) v1. with 291 hours, a publicly available dataset for ASR in BP containing validated pairs (audio-transcription). CORAA also contains European Portuguese audios (4.69 hours). We also present two public ASR models based on Wav2Vec 2.0 XLSR-53 and fine-tuned over CORAA. Our best model achieved a Word Error Rate of 27.35% on CORAA test set and 16.01% on Common Voice test set. When measuring the Character Error Rate, we obtained 14.26% and 5.45% for CORAA and Common Voice, respectively. CORAA corpora were assembled to both improve ASR models in BP with phenomena from spontaneous speech and motivate young researchers to start their studies on ASR for Portuguese. All the corpora are publicly available at https://github.com/nilc-nlp/CORAA under the CC BY-NC-ND 4.0 license.