 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Vector Arithmetic for Emotional Expressivity Control in Language-Model-Based Text-to-Speech
Jun 03, 2026We investigate whether task-vector arithmetic, successful for cross-speaker emotional intensity control in modular text-to-speech (TTS), transfers to large-scale TTS systems built on language-model backbones with in-context learning (LM-TTS). Through a systematic elimination study over four progressively narrower operands on Qwen3-TTS-12Hz-1.7B - model weights via LoRA fine-tuning, continuous codec embeddings, discrete codec tokens, and the speaker embedding (x-vector) produced by an ECAPA-TDNN encoder jointly trained with the synthesis backbone - we localize the dominant carrier of emotional prosody to the x-vector. Building on this finding, we propose a training-free method based on centroid arithmetic in x-vector space: an emotion direction $τ= \mathbb{E}_i[x(s_i,\text{emo})] -\mathbb{E}_i[x(s_i,\text{neutral})]$ applied to an unseen target speaker as $x_{\text{new}} = x(\text{target},\text{neutral}) + α\cdotτ$. Using ESD (English) as the $τ$ source and emoUERJ (Brazilian Portuguese) as a cross-lingual ground-truth target, we observe average gains of $+0.29$ in emotion2vec cosine over the ICL baseline on English held-out speakers and $+0.09$ on Brazilian Portuguese held-out speakers, while largely preserving identity (WavLM SECS $\gtrsim 0.88$ for the multi-speaker $τ$ variant) and intelligibility (WER $\approx 0$ in PT-BR). These results offer initial evidence that the reported incompatibility of centroid-arithmetic style control with token-based TTS architectures may be circumvented when the arithmetic operates on the speaker embedding.
Fine-tuning Pre-trained Audio Models for COVID-19 Detection: A Technical Report
Nov 18, 2025This technical report investigates the performance of pre-trained audio models on COVID-19 detection tasks using established benchmark datasets. We fine-tuned Audio-MAE and three PANN architectures (CNN6, CNN10, CNN14) on the Coswara and COUGHVID datasets, evaluating both intra-dataset and cross-dataset generalization. We implemented a strict demographic stratification by age and gender to prevent models from exploiting spurious correlations between demographic characteristics and COVID-19 status. Intra-dataset results showed moderate performance, with Audio-MAE achieving the strongest result on Coswara (0.82 AUC, 0.76 F1-score), while all models demonstrated limited performance on Coughvid (AUC 0.58-0.63). Cross-dataset evaluation revealed severe generalization failure across all models (AUC 0.43-0.68), with Audio-MAE showing strong performance degradation (F1-score 0.00-0.08). Our experiments demonstrate that demographic balancing, while reducing apparent model performance, provides more realistic assessment of COVID-19 detection capabilities by eliminating demographic leakage - a confounding factor that inflate performance metrics. Additionally, the limited dataset sizes after balancing (1,219-2,160 samples) proved insufficient for deep learning models that typically require substantially larger training sets. These findings highlight fundamental challenges in developing generalizable audio-based COVID-19 detection systems and underscore the importance of rigorous demographic controls for clinically robust model evaluation.
The Impact of Prosodic Segmentation on Speech Synthesis of Spontaneous Speech
Nov 06, 2025Spontaneous speech presents several challenges for speech synthesis, particularly in capturing the natural flow of conversation, including turn-taking, pauses, and disfluencies. Although speech synthesis systems have made significant progress in generating natural and intelligible speech, primarily through architectures that implicitly model prosodic features such as pitch, intensity, and duration, the construction of datasets with explicit prosodic segmentation and their impact on spontaneous speech synthesis remains largely unexplored. This paper evaluates the effects of manual and automatic prosodic segmentation annotations in Brazilian Portuguese on the quality of speech synthesized by a non-autoregressive model, FastSpeech 2. Experimental results show that training with prosodic segmentation produced slightly more intelligible and acoustically natural speech. While automatic segmentation tends to create more regular segments, manual prosodic segmentation introduces greater variability, which contributes to more natural prosody. Analysis of neutral declarative utterances showed that both training approaches reproduced the expected nuclear accent pattern, but the prosodic model aligned more closely with natural pre-nuclear contours. To support reproducibility and future research, all datasets, source codes, and trained models are publicly available under the CC BY-NC-ND 4.0 license.
FreeSVC: Towards Zero-shot Multilingual Singing Voice Conversion
Jan 09, 2025This work presents FreeSVC, a promising multilingual singing voice conversion approach that leverages an enhanced VITS model with Speaker-invariant Clustering (SPIN) for better content representation and the State-of-the-Art (SOTA) speaker encoder ECAPA2. FreeSVC incorporates trainable language embeddings to handle multiple languages and employs an advanced speaker encoder to disentangle speaker characteristics from linguistic content. Designed for zero-shot learning, FreeSVC enables cross-lingual singing voice conversion without extensive language-specific training. We demonstrate that a multilingual content extractor is crucial for optimal cross-language conversion. Our source code and models are publicly available.
No Saved Kaleidosope: an 100% Jitted Neural Network Coding Language with Pythonic Syntax
Sep 17, 2024



We developed a jitted compiler for training Artificial Neural Networks using C++, LLVM and Cuda. It features object-oriented characteristics, strong typing, parallel workers for data pre-processing, pythonic syntax for expressions, PyTorch like model declaration and Automatic Differentiation. We implement the mechanisms of cache and pooling in order to manage VRAM, cuBLAS for high performance matrix multiplication and cuDNN for convolutional layers. Our experiments with Residual Convolutional Neural Networks on ImageNet, we reach similar speed but degraded performance. Also, the GRU network experiments show similar accuracy, but our compiler have degraded speed in that task. However, our compiler demonstrates promising results at the CIFAR-10 benchmark, in which we reach the same performance and about the same speed as PyTorch. We make the code publicly available at: https://github.com/NoSavedDATA/NoSavedKaleidoscope
Contrasting Deep Learning Models for Direct Respiratory Insufficiency Detection Versus Blood Oxygen Saturation Estimation
Jul 30, 2024



We contrast high effectiveness of state of the art deep learning architectures designed for general audio classification tasks, refined for respiratory insufficiency (RI) detection and blood oxygen saturation (SpO2) estimation and classification through automated audio analysis. Recently, multiple deep learning architectures have been proposed to detect RI in COVID patients through audio analysis, achieving accuracy above 95% and F1-score above 0.93. RI is a condition associated with low SpO2 levels, commonly defined as the threshold SpO2 <92%. While SpO2 serves as a crucial determinant of RI, a medical doctor's diagnosis typically relies on multiple factors. These include respiratory frequency, heart rate, SpO2 levels, among others. Here we study pretrained audio neural networks (CNN6, CNN10 and CNN14) and the Masked Autoencoder (Audio-MAE) for RI detection, where these models achieve near perfect accuracy, surpassing previous results. Yet, for the regression task of estimating SpO2 levels, the models achieve root mean square error values exceeding the accepted clinical range of 3.5% for finger oximeters. Additionally, Pearson correlation coefficients fail to surpass 0.3. As deep learning models perform better in classification than regression, we transform SpO2-regression into a SpO2-threshold binary classification problem, with a threshold of 92%. However, this task still yields an F1-score below 0.65. Thus, audio analysis offers valuable insights into a patient's RI status, but does not provide accurate information about actual SpO2 levels, indicating a separation of domains in which voice and speech biomarkers may and may not be useful in medical diagnostics under current technologies.
Yin Yang Convolutional Nets: Image Manifold Extraction by the Analysis of Opposites
Oct 24, 2023



Computer vision in general presented several advances such as training optimizations, new architectures (pure attention, efficient block, vision language models, generative models, among others). This have improved performance in several tasks such as classification, and others. However, the majority of these models focus on modifications that are taking distance from realistic neuroscientific approaches related to the brain. In this work, we adopt a more bio-inspired approach and present the Yin Yang Convolutional Network, an architecture that extracts visual manifold, its blocks are intended to separate analysis of colors and forms at its initial layers, simulating occipital lobe's operations. Our results shows that our architecture provides State-of-the-Art efficiency among low parameter architectures in the dataset CIFAR-10. Our first model reached 93.32\% test accuracy, 0.8\% more than the older SOTA in this category, while having 150k less parameters (726k in total). Our second model uses 52k parameters, losing only 3.86\% test accuracy. We also performed an analysis on ImageNet, where we reached 66.49\% validation accuracy with 1.6M parameters. We make the code publicly available at: https://github.com/NoSavedDATA/YinYang_CNN.
Evaluating OpenAI's Whisper ASR for Punctuation Prediction and Topic Modeling of life histories of the Museum of the Person
May 26, 2023

Automatic speech recognition (ASR) systems play a key role in applications involving human-machine interactions. Despite their importance, ASR models for the Portuguese language proposed in the last decade have limitations in relation to the correct identification of punctuation marks in automatic transcriptions, which hinder the use of transcriptions by other systems, models, and even by humans. However, recently Whisper ASR was proposed by OpenAI, a general-purpose speech recognition model that has generated great expectations in dealing with such limitations. This chapter presents the first study on the performance of Whisper for punctuation prediction in the Portuguese language. We present an experimental evaluation considering both theoretical aspects involving pausing points (comma) and complete ideas (exclamation, question, and fullstop), as well as practical aspects involving transcript-based topic modeling - an application dependent on punctuation marks for promising performance. We analyzed experimental results from videos of Museum of the Person, a virtual museum that aims to tell and preserve people's life histories, thus discussing the pros and cons of Whisper in a real-world scenario. Although our experiments indicate that Whisper achieves state-of-the-art results, we conclude that some punctuation marks require improvements, such as exclamation, semicolon and colon.
Interpretability Analysis of Deep Models for COVID-19 Detection
Nov 25, 2022



During the outbreak of COVID-19 pandemic, several research areas joined efforts to mitigate the damages caused by SARS-CoV-2. In this paper we present an interpretability analysis of a convolutional neural network based model for COVID-19 detection in audios. We investigate which features are important for model decision process, investigating spectrograms, F0, F0 standard deviation, sex and age. Following, we analyse model decisions by generating heat maps for the trained models to capture their attention during the decision process. Focusing on a explainable Inteligence Artificial approach, we show that studied models can taken unbiased decisions even in the presence of spurious data in the training set, given the adequate preprocessing steps. Our best model has 94.44% of accuracy in detection, with results indicating that models favors spectrograms for the decision process, particularly, high energy areas in the spectrogram related to prosodic domains, while F0 also leads to efficient COVID-19 detection.
Bringing NURC/SP to Digital Life: the Role of Open-source Automatic Speech Recognition Models
Oct 14, 2022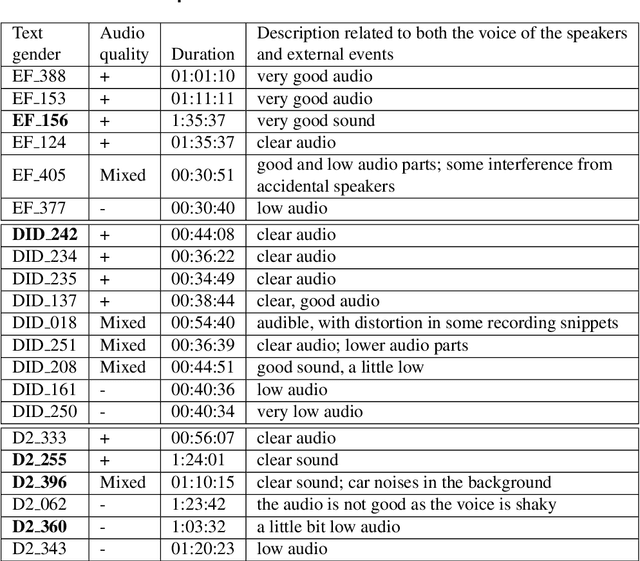

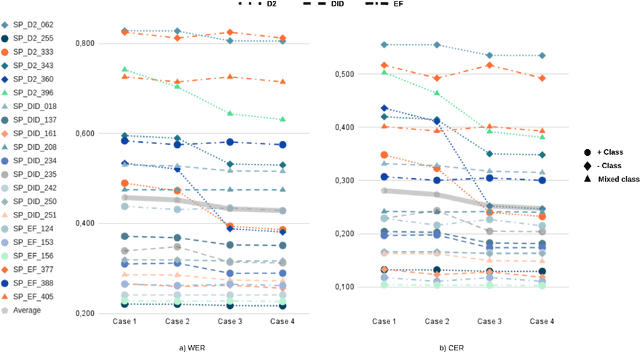
The NURC Project that started in 1969 to study the cultured linguistic urban norm spoken in five Brazilian capitals, was responsible for compiling a large corpus for each capital. The digitized NURC/SP comprises 375 inquiries in 334 hours of recordings taken in S\~ao Paulo capital. Although 47 inquiries have transcripts, there was no alignment between the audio-transcription, and 328 inquiries were not transcribed. This article presents an evaluation and error analysis of three automatic speech recognition models trained with spontaneous speech in Portuguese and one model trained with prepared speech. The evaluation allowed us to choose the best model, using WER and CER metrics, in a manually aligned sample of NURC/SP, to automatically transcribe 284 hours.